
学习导读
如何阅读这份笔记
- 如果你是第一次学,建议按
基础认知 -> 基础使用 -> 镜像构建 -> 存储 -> 网络 -> Compose -> 监控与调试 -> 底层原理 -> 扩展实践的顺序阅读。 - 如果你是为了查命令,可以直接跳到对应模块中的实践案例和命令清单。
- 如果你想建立体系,重点关注“镜像 / 容器 / 仓库 / 存储 / 网络 / 编排 / 运行时原理”之间的关系。
知识主线
- 云原生给出的是一种应用构建与交付的方法论,Docker 是其中最重要的容器化工具之一。
- Docker 的核心对象是
镜像、容器、仓库:镜像负责打包,容器负责运行,仓库负责分发。 - 当容器从单个应用走向生产场景时,就必须继续理解
存储、网络、多容器编排与监控运维。 - 想真正理解 Docker 为什么轻量、为什么能快速构建与启动,还要继续深入
Namespace、Cgroups、OverlayFS、RootFS和Buildx。 - 最后的 NPC Playground 属于“平台侧延伸”,展示 Docker 与云原生平台、流水线、Agent 的结合方式。
知识关系图
flowchart TD
A[云原生理念] --> B[容器化]
B --> C[Docker 核心架构]
C --> D[镜像 Image]
C --> E[容器 Container]
C --> F[仓库 Registry]
D --> G[Dockerfile 构建]
D --> H[镜像分层与 OverlayFS]
E --> I[容器生命周期管理]
E --> J[容器存储]
E --> K[容器网络]
J --> L[Bind Mount / Volume]
K --> M[Bridge / Host / Container / None / Overlay]
G --> N[Compose 多容器编排]
N --> O[环境变量与 .env]
I --> P[日志 / inspect / stats / exec]
H --> Q[RootFS]
G --> R[Buildx 多平台构建]
A --> S[CNB / NPC Playground 平台实践]
模块导航
| 模块 | 你要解决的问题 | 重点内容 |
|---|---|---|
| Part 1 基础认知与 Docker 入门 | Docker 为什么出现、解决什么问题、怎么开始用 | 云原生、技术演进、应用场景、架构、基础命令 |
| Part 2 镜像构建与存储管理 | 镜像怎么来,容器数据放哪,为什么会丢 | commit / Dockerfile / Volume / Bind Mount / OverlayFS |
| Part 3 网络管理、Compose 与多容器协作 | 多容器怎么通信、怎么一起启动 | Docker Network、Compose、环境变量、Todo 项目 |
| Part 4 容器监控、运维与进阶原理 | 容器如何运维、如何排障、底层如何工作 | stats / logs / exec / Portainer / RootFS / Buildx |
| Part 5 CNB NPC Playground 扩展 | Docker 如何落到平台与 Agent 场景 | NPC、Skills、镜像、流水线、平台集成 |
Part 1 基础认知与 Docker 入门(day1 上午)
这一部分解决三个最基础的问题:为什么需要容器、Docker 解决什么问题、我们怎样开始使用 Docker。建议按“云原生背景 → 技术演进 → 应用场景 → 架构原理 → 基础命令”来理解。
云原生和 git
1. Git 分支管理
- 课堂开始简要介绍了 Git 分支合并时可能出现的冲突问题和 git 相关操作。
- coldenchen 演示了如何通过手动操作(删除和重新添加分支)来解决合并时的状态问题。
2. 云原生概念讲解
-
云原生是一个在公有云、私有云及混合云环境中构建弹性、可扩展应用的概念,而非单一技术。
-
云原生包含的关键技术包括:
- 容器服务:Docker 是其代表性技术之一,但容器化概念本身并不新鲜。
- 微服务:一种将单体应用拆分为多个独立服务的架构理念,以提升系统的灵活性和可维护性,但并非适用于所有场景。
- 服务网格:为微服务间的通信、流量管理和监控提供的基础设施层。
- 不可变基础设施:强调应用的“不可变”性,即出现问题时应通过完全重建(替换)来修复,而非直接修改运行中的实例,以避免“配置漂移”问题。
- 声明式 API:通过定义期望的状态(如配置文件),由系统自动达成该状态,区别于传统的“命令式”操作。
K8s 弃用 Docker这个说法其实有点误导。实际情况是 K8s 不再直接使用 Docker 的完整运行时,而是改用 Docker 底层的一个组件containerd作为运行时接口。同时 K8s 还专门开发了CRI-O作为替代方案。
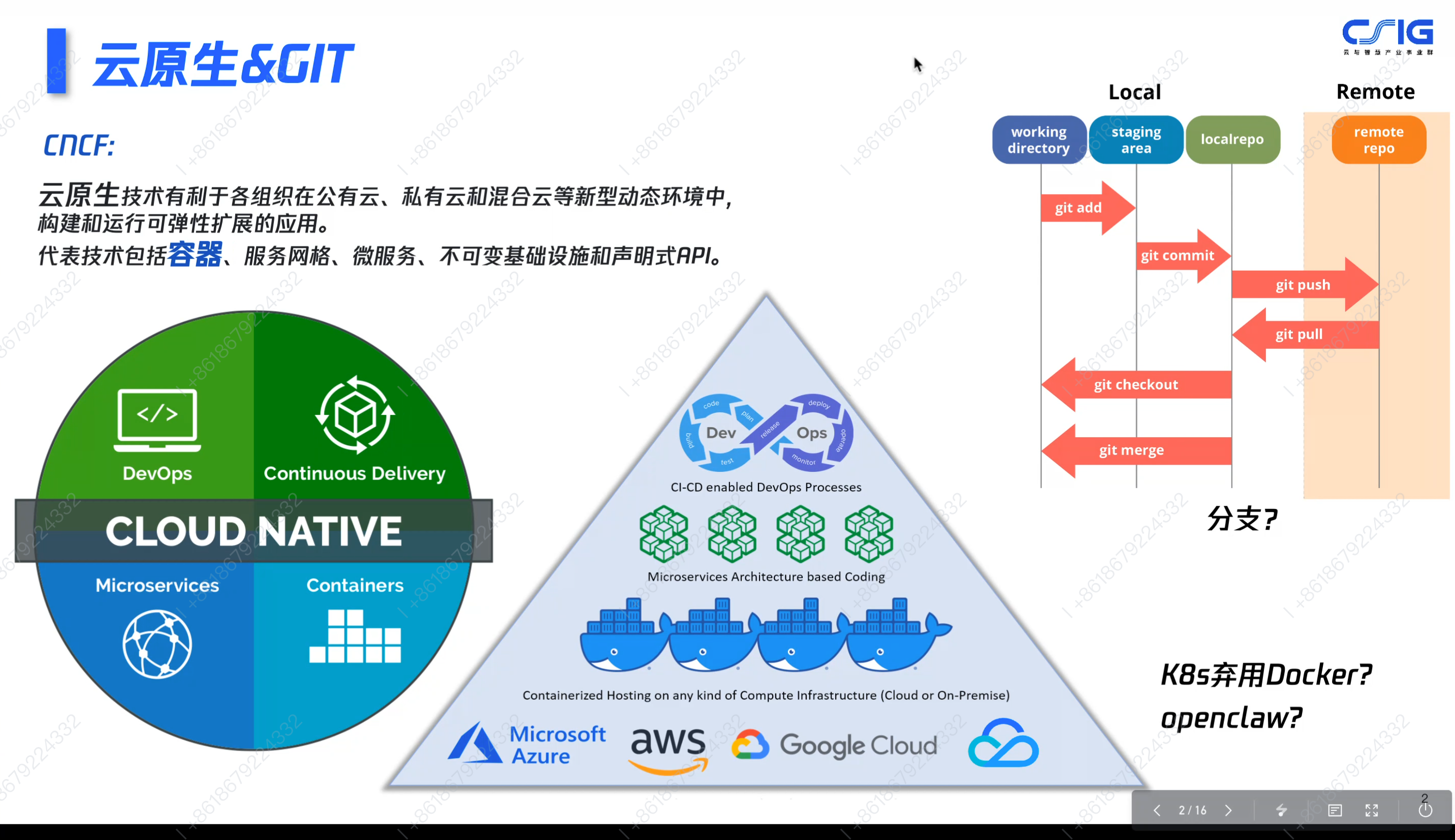
从物理机到容器化的技术演进
一、技术演进总览
服务器部署技术经历了三个核心阶段:物理机时代 → 虚拟化时代 → 容器化时代,核心演进目标是解决资源利用率、部署效率与环境隔离的痛点。
二、各阶段技术解析
1. 物理机时代
架构模型
- 底层:
Hardware(物理硬件) - 中层:
Operating System(宿主操作系统) - 上层:直接运行多个
App(应用),共享同一操作系统内核
特性
- ✅ 优点:架构简单,无额外虚拟化开销
- ❌ 缺点:资源浪费严重,单台服务器硬件资源无法高效隔离,应用间相互影响,资源利用率低。
2. 虚拟化时代
架构模型
- 底层:
Hardware(物理硬件) - 中层:
Operating System(宿主操作系统)+Hypervisor(虚拟化层,如VMware/KVM) - 上层:多个独立的
Virtual Machine(虚拟机),每个虚拟机包含独立的Operating System(客户机操作系统)+Bin/Library(依赖库)+App(应用)
特性
- ✅ 优点:实现了环境隔离,彻底解决应用间依赖冲突问题,硬件资源可通过 Hypervisor 分配给不同虚拟机。
- ❌ 缺点:
- 虚拟机体积臃肿,为 GB 量级(包含完整操作系统内核)
- 部署/启动速度慢,耗时数分钟
- 操作系统内核层存在额外开销,资源利用率仍有优化空间
3. 容器化时代
架构模型
- 底层:
Hardware(物理硬件) - 中层:
Operating System(宿主操作系统)+Container Runtime(容器运行时,如Docker) - 上层:多个独立的
Container(容器),每个容器仅包含Bin/Library(依赖库)+App(应用),共享宿主操作系统内核
特性
- ✅ 优点:
- 继承了虚拟化的环境隔离能力,解决依赖冲突问题
- 容器体积小(不含操作系统内核,仅包含应用与依赖)
- 启动速度快(秒级启动,直接复用宿主内核,无需加载完整系统)
- 资源开销极低,硬件资源利用率大幅提升
- ❌ 缺点:容器共享宿主内核,隔离性弱于虚拟机,内核层面的漏洞可能影响所有容器。
三、核心演进对比表
| 阶段 | 隔离方式 | 启动速度 | 资源开销 | 镜像大小 | 典型代表 |
|---|---|---|---|---|---|
| 物理机 | 无隔离 | - | 极高(资源浪费) | - | 传统物理服务器部署 |
| 虚拟化 | 硬件级隔离(Hypervisor+独立内核) | 分钟级 | 较高(每个虚拟机运行完整 OS) | GB 级 | VMware、KVM |
| 容器化 | 进程级隔离(共享宿主内核) | 秒级 | 极低(仅运行应用与依赖) | MB 级 | Docker、Kubernetes |
四、核心演进逻辑
- 解决隔离性问题:从物理机无隔离,到虚拟化的硬件级强隔离,再到容器化的进程级轻量隔离,平衡隔离性与资源开销。
- 提升资源利用率:从单台物理机资源浪费,到虚拟机按需分配资源,再到容器共享内核、极致利用硬件资源。
- 优化部署效率:从数分钟的虚拟机部署,到秒级的容器启动,大幅降低应用交付的时间成本。
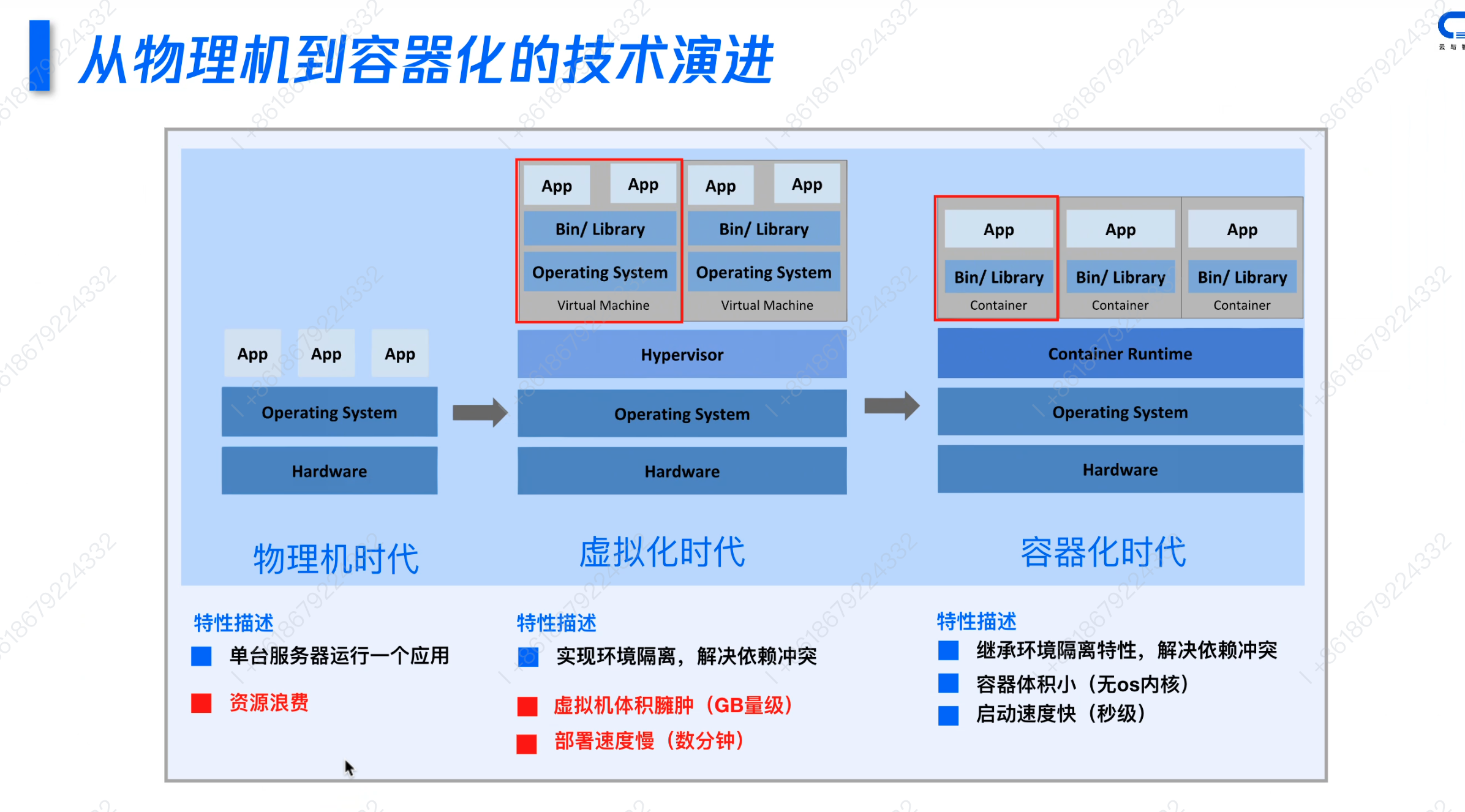
Docker 应用场景
一、Docker 核心价值总览
Docker 以容器化技术为核心,通过标准化、隔离性、可移植性三大特性,解决传统开发运维中的环境不一致、资源浪费、部署复杂等痛点,覆盖从开发、测试到运维的全流程场景。
二、分场景详细解析
| 序号 | 使用场景 | 核心价值 | 解决的问题 | Docker 方案 |
|---|---|---|---|---|
| 1 | 单体应用微服务化 | 渐进式拆分 | 大系统难维护、难扩展 | 逐步拆分为微服务容器 |
| 2 | 加速应用开发 | 环境一致性 | 新人上手慢、并行开发难 | 提供标准化开发容器 |
| 3 | 基础设施即代码 | 可重复配置 | 配置漂移、环境不一致 | Dockerfile 定义即代码 |
| 4 | 多环境标准化部署 | 消除差异 | “我机器上能跑”问题 | 同一镜像多环境部署 |
| 5 | 松耦合架构 | 故障隔离 | 单点故障影响全局 | 服务容器化隔离 |
| 6 | 多租户隔离 | 安全隔离 | 租户间相互影响 | 容器级租户隔离 |
| 7 | 加速 CI/CD 流水线 | 并行构建 | 构建部署太慢 | 容器化 CI/CD 并行执行 |
| 8 | 隔离应用环境 | 依赖隔离 | 多项目依赖冲突 | 每项目独立容器 |
| 9 | 应用跨平台分发 | 可移植性 | 跨平台部署复杂 | 镜像打包一次到处跑 |
| 10 | 混合云/多云部署 | 云平台无关 | 厂商锁定风险 | 容器化实现云无关 |
| 11 | 降低 IT 成本 | 资源高效 | 服务器资源浪费 | 容器高密度部署 |
| 12 | 灾难恢复 | 快速恢复 | 故障停机时间长 | 预构建镜像快速启动 |
| 13 | 简化弹性扩展 | 按需扩缩 | 扩容流程复杂耗时 | K8s 自动扩缩容 |
| 14 | 依赖管理 | 依赖打包 | 依赖地狱版本混乱 | 依赖打包进镜像 |
| 15 | 提升安全性 | 容器隔离 | 攻击面大隔离不足 | 容器隔离 + 权限控制 |
三、关键场景补充说明
-
环境一致性(场景 2/4) Docker 镜像包含应用及其所有依赖,从开发机到测试环境、生产环境,镜像完全一致,彻底解决“本地能跑、线上报错”的经典问题。
-
基础设施即代码(场景 3) 通过
Dockerfile将环境配置、依赖安装流程代码化,可版本控制、可重复执行,避免手动配置导致的漂移问题。 -
CI/CD 加速(场景 7) 容器可以快速创建销毁,支持流水线并行执行构建任务,同时镜像缓存机制大幅缩短构建耗时。
-
资源高效与成本优化(场景 11) 容器共享宿主操作系统内核,无需为每个应用启动完整虚拟机,实现服务器资源的高密度利用,降低硬件成本。
-
故障隔离与弹性扩展(场景 5/13) 容器间进程级隔离,单个容器故障不影响全局;结合 Kubernetes 可实现根据负载自动扩缩容,简化运维复杂度。
四、Docker 核心优势总结
- 开发侧:统一开发环境,降低新人上手成本,并行开发更顺畅
- 交付侧:一次构建、多环境运行,消除部署差异,提升交付效率
- 运维侧:故障隔离、快速恢复、弹性扩缩容,降低运维成本与风险
- 架构侧:支撑微服务、多云/混合云架构,避免厂商锁定,提升架构灵活性
cnb 平台部署初体验


fork 后可点击一键部署
实践项目:使用 docker 部署 TodoList 应用
在本章节中,我们将创建一个完整的 Todo 应用,包含以下组件:
- Nginx: 路由转发
- 前端: React 应用
- 后端: Node.js API 服务
- 数据库: MongoDB
项目结构
5_compose/
├── docker-compose.yml # Compose 配置文件
├── nginx/ # nginx
├── frontend/ # React 前端应用
├── backend/ # Node.js 后端服务
└── INSTRUCTIONS.md # 项目说明Docker Compose 配置解析
服务定义
-
nginx 服务
- 使用官方 nginx 镜像
- 映射端口 8080,作为应用的访问入口
- 将 nginx.conf 配置文件打包进镜像
-
frontend 服务
- 使用本地 Dockerfile 构建
- 暴露端口 3000,仅容器网络访问
- 设置 API URL 环境变量
- 依赖于 backend 服务
- 使用卷挂载实现热重载
-
backend 服务
- 使用本地 Dockerfile 构建
- 映射端口 3001,仅容器网络访问
- 设置 MongoDB 连接环境变量
- 依赖于 mongodb 服务
- 使用卷挂载实现热重载
-
mongodb 服务
- 使用官方 MongoDB 镜像
- 映射端口 27017,仅容器网络访问
- 使用命名卷持久化数据
网络配置
- Docker Compose 会自动创建一个默认网络 (bridge 模式)
- 所有服务都在同一网络中
- 服务可以通过服务名互相访问
数据持久化
- 使用命名卷
mongodb_data持久化数据库数据 - 使用绑定挂载实现开发时的代码热重载
使用说明
-
在后台启动服务
docker compose up -d -
查看服务状态
docker compose ps -
查看服务日志
查看特定服务的日志: ```bash docker compose logs frontend docker compose logs backend docker compose logs mongodb -
停止所有服务
docker compose down -
重新构建服务
docker compose build -
重启单个服务
docker compose restart frontend
访问应用
我们使用了在 nginx 这里配置了 8080 端口作为 todo 应用的整体入口,在 cnb 上我们可以通过添加一个 8080 的端口映射来实现外网访问, 可以按照如下步骤来配置。
点击这个浏览器图标,就可以访问 todo 应用了。
Docker 架构
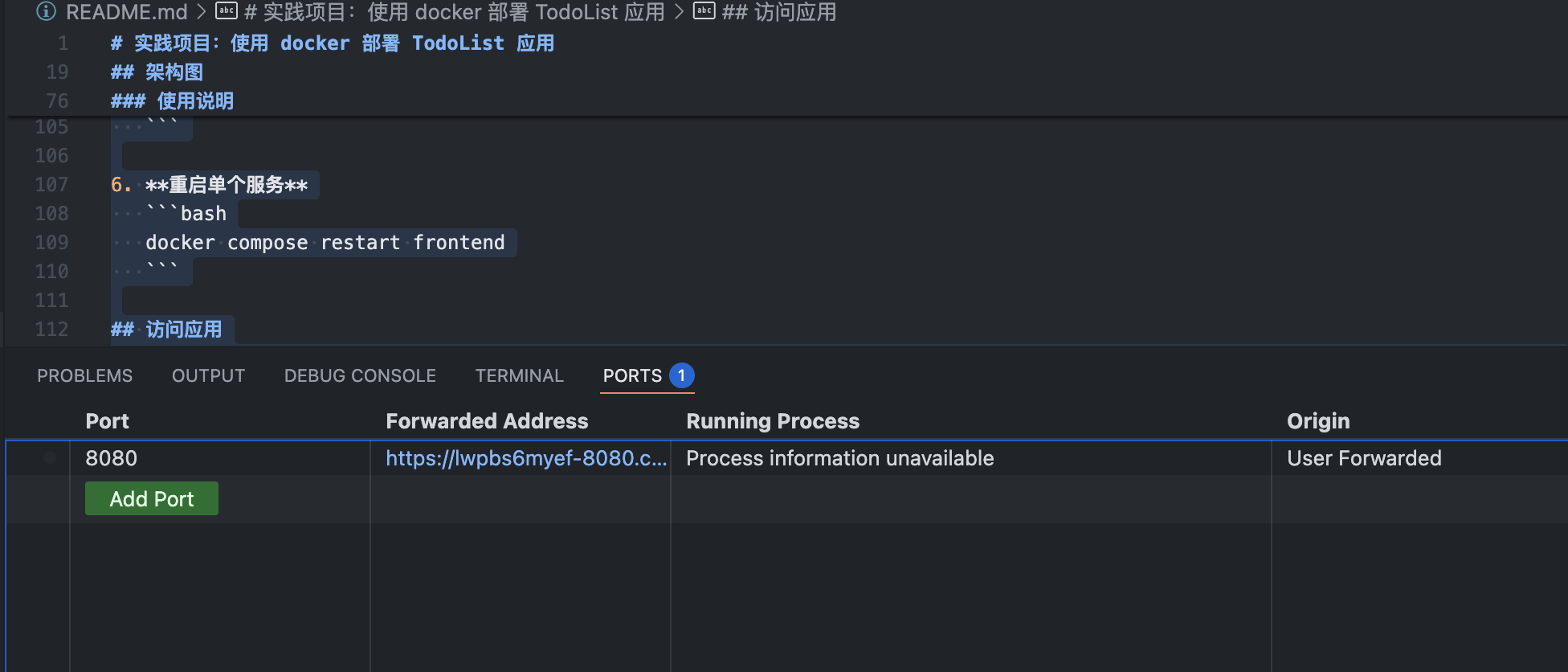
一、整体架构:C/S 模式
Docker 采用典型的 客户端-服务器(C/S)架构,分为客户端(Client)、服务端(Docker Host)、仓库(Registry)三部分,核心交互流程如下:
- 用户通过客户端(
docker CLI)发送指令; - 客户端将指令转为 API 请求,发送给服务端的
Docker Daemon; Docker Daemon处理请求,完成镜像构建、容器管理、仓库交互等实际操作。
二、核心组件详解
1. 客户端(Client)
- 核心角色:用户交互入口
- 核心能力:接收用户指令(如
docker run/docker build/docker pull),并通过 REST API 与服务端通信,不直接处理容器和镜像的底层操作。
2. 服务端(Docker Host)
- 核心进程:
Docker Daemon(守护进程),运行在宿主机器后台 - 核心职责:
- 监听客户端的 API 请求
- 负责镜像管理(构建、拉取、存储)
- 负责容器生命周期管理(创建、启动、停止、删除)
- 负责资源分配(网络、存储、数据卷)
- 核心管理对象:
Images(镜像):容器的只读模板,包含应用及依赖Containers(容器):镜像的运行实例,进程级隔离的应用运行环境Network(网络):容器间、容器与外部的通信管理Data Volumes(数据卷):容器数据持久化存储
3. 仓库(Registry)
- 核心作用:镜像的集中存储与分发服务
- 常见类型:公共仓库(Docker Hub)、私有仓库(Harbor、Registry)
- 核心交互流程:
docker pull:从仓库拉取镜像到本地docker push:将本地镜像推送到仓库
三、三大核心概念
1. 镜像(Image)
- 定义:只读的应用运行模板,包含应用代码、依赖库、环境变量、配置文件等
- 特点:分层存储、只读,可通过
Dockerfile构建,支持版本管理
2. 容器(Container)
- 定义:镜像的运行实例,是一个轻量级的隔离进程
- 特点:可读写、独立运行,多个容器可共享同一镜像,通过进程级隔离实现资源隔离
3. 仓库(Registry)
- 定义:集中存储和分发 Docker 镜像的服务
- 特点:支持镜像版本管理、权限控制,实现镜像在不同环境的共享与分发
四、核心指令与流程
| 指令 | 客户端行为 | 服务端行为 | 核心作用 |
|---|---|---|---|
docker run | 发送容器创建请求 | 基于镜像创建并启动容器,分配资源 | 运行应用容器 |
docker build | 发送镜像构建请求 | 解析 Dockerfile,分层构建镜像 | 自定义应用镜像 |
docker pull | 发送镜像拉取请求 | 从 Registry 拉取镜像到本地 | 获取公共/私有镜像 |
五、架构优势
- 解耦用户交互与底层操作:客户端仅负责指令转发,服务端专注底层资源管理,架构清晰易扩展
- 标准化镜像分发:通过仓库实现镜像一次构建、多环境运行,消除环境差异
- 轻量级隔离:容器共享宿主内核,进程级隔离,资源开销远低于虚拟机
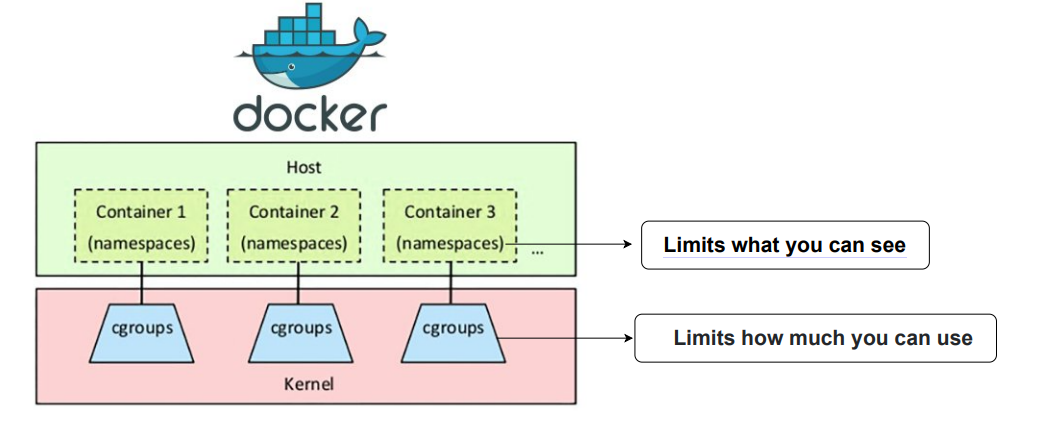
六、容器资源管理核心:Cgroup 与 Namespace
- Namespace(隔离):为容器提供独立的进程、网络、文件系统等资源视图,让容器进程 “以为自己运行在独立系统中”
- Cgroup(资源控制):Linux 内核的资源管理机制,类似 “资源管家”,可精确限制每个容器的 CPU、内存、磁盘 I/O 等资源配额,避免单个容器占用宿主机全部资源
- 补充说明:容器本质是共享宿主机内核的进程,Namespace 解决 “隔离性” 问题,Cgroup 解决 “资源配额” 问题,两者配合实现容器的轻量级资源管控
Docker 基础使用
CNB 云原生开发环境中已经预装了 Docker,无需手动安装,直接体验即可。
查看 Docker 信息
docker version # 查看版本信息
docker info # 查看运行时信息运行第一个容器:hello-world
docker run hello-world学习一门新语言,第一个程序是输出 hello world!
学习 Docker,第一个容器运行输出 hello from Docker!
案例:运行 Alpine Linux 容器
扩展知识:
Alpine 镜像在企业生产环境中被广泛应用:
- 极简的 Linux 发行版
- 只包含基本命令和工具
- 镜像体积小(约 8MB)
- 内置包管理系统
apk- 常用作其他镜像的基础
为什么一启动 alpine 就退出
一句话:alpine 默认没有常驻前台进程,主进程跑完就结束,容器跟着退出
解决方法:交互式/后台运行
| 命令 | 主进程 | 容器状态 | 原因 |
|---|---|---|---|
docker run alpine | /bin/sh(瞬间退出) | Exited | 无前台常驻任务 |
docker run -it alpine | /bin/sh(前台交互) | Running | 终端附着,sh 不退出 |
docker run -d alpine sleep 3600 | sleep 3600(前台) | Running | sleep 长期占用前台 |
使用 docker ps -a 能查到这个已退出的 alpine 容器
镜像操作
1. 拉取镜像
# 拉取 alpine 镜像,默认以 latest 标签拉取
docker pull alpine2. 查看镜像
docker image ls镜像格式:[REGISTRY_HOST[:PORT]/]PATH[:TAG]
- REGISTRY_HOST:镜像仓库地址,默认 Docker Hub
docker.io - PORT:registry 端口
- PATH:镜像路径,Docker Hub 镜像格式为
[NAMESPACE/]REPOSITORY,无命名空间默认library - TAG:镜像标签,默认 latest
完整镜像示例:
-
alpine等同于docker.io/library/alpine:latest -
私有仓库镜像示例
docker.cnb.cool/docker-666/campus-academy-template/dev-env:latest
示例:
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.cnb.cool/docker-666/campus-academy-template/dev-env latest 890755180ee4 7 hours ago 722MB
mongo 6 bdc4e039b30b 8 weeks ago 764MB3. 镜像可见性
- Public:公开镜像,无需登录直接拉取
- Private:私有镜像,必须登录仓库才可拉取
# 公开镜像
docker pull docker.cnb.cool/coldenn/docker-open-camp/docker-exercises/my-alpine:latest
# 私有镜像(未登录拉取失败)
docker pull docker.cnb.cool/docker-open-camp/private-repo/my-alpine4. 登录镜像仓库
docker login [-u ${username}] [-p ${password}] ${repository}5. 删除镜像
docker image rm ${image_id}6. 查看镜像历史
docker history ${image_id}容器操作
1. 运行容器
docker run alpine2. 查看容器
docker ps问题:临时容器无法查询 原因:无前台持续进程的容器,启动后会立即退出
查看所有容器(含停止状态):
docker ps -a3. 交互式运行容器
docker run -it alpine参数说明:
-it:开启交互式终端-d:后台守护模式运行
# 进入运行中容器
docker exec -it <container_id> /bin/sh
# 执行单条命令
docker exec <container_id> ls -la /app4. 后台运行容器
docker run -d alpine sleep 3600注意:Alpine 无常驻前台进程,后台运行需指定长命令保活
5. 容器生命周期管理
docker stop <container_id> # 停止
docker start <container_id> # 启动
docker restart <container_id> # 重启
docker rm <container_id> # 删除6. 进入运行中的容器
docker exec -it <container_id> /bin/sh容器内 PID=1 为核心进程,exec 新建进程退出不会导致容器停止。
也可使用 bash
7. 容器进入替代方式
docker attach <container_id>缺点:直接挂载一号进程,退出会导致容器停止,不推荐使用
8. 查看容器详情
docker inspect <container_id>9. 查看容器日志
docker logs <container_id>拓展
Docker DevOps
flowchart LR
subgraph 开发阶段
A[代码编写] --> B[本地Docker测试]
end
subgraph CI持续集成
B --> C[Git Push]
C --> D[自动构建镜像]
D --> E[运行测试]
E --> F[代码扫描]
end
subgraph CD持续部署
F --> G[推送镜像仓库]
G --> H{环境选择}
H -->|开发| I[Dev环境]
H -->|预发| J[Staging环境]
H -->|生产| K[Production环境]
end
subgraph 运维监控
I & J & K --> L[监控告警]
L --> M[日志收集]
M --> N[反馈优化]
end
N -.->|迭代| A
OCI 镜像规范
OCI 镜像包含:镜像索引、清单、配置、层文件。镜像索引可选,主要适配多硬件架构,实现跨平台镜像兼容。
Docker 镜像存储
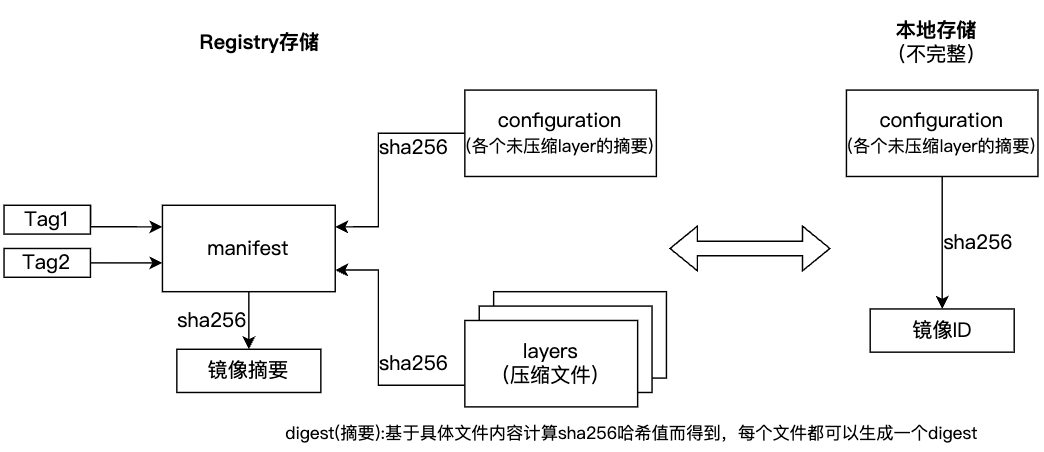
Docker pull 和 Docker push
Docker pull
sequenceDiagram
participant Docker Client
participant Docker Registry
participant Docker Daemon
Docker Client->>Docker Registry: 解析镜像名称
Docker Registry-->>Docker Client: 身份认证
Docker Client->>Docker Registry: 获取镜像清单
Docker Registry-->>Docker Client: 返回清单信息
Docker Client->>Docker Registry: 拉取配置与分层文件
Docker Client->>Docker Daemon: 组装本地镜像
Docker Daemon-->>Docker Client: 镜像拉取完成
Docker push
sequenceDiagram
participant Client
participant Daemon
participant Registry
Client->>Daemon: 执行推送命令
Daemon->>Daemon: 解析镜像分层
Daemon->>Registry: 身份认证
Registry-->>Daemon: 下发令牌
Daemon->>Registry: 校验镜像层
Daemon->>Registry: 上传缺失分层
Daemon->>Registry: 推送镜像清单
Registry-->>Daemon: 推送成功
Daemon-->>Client: 反馈结果
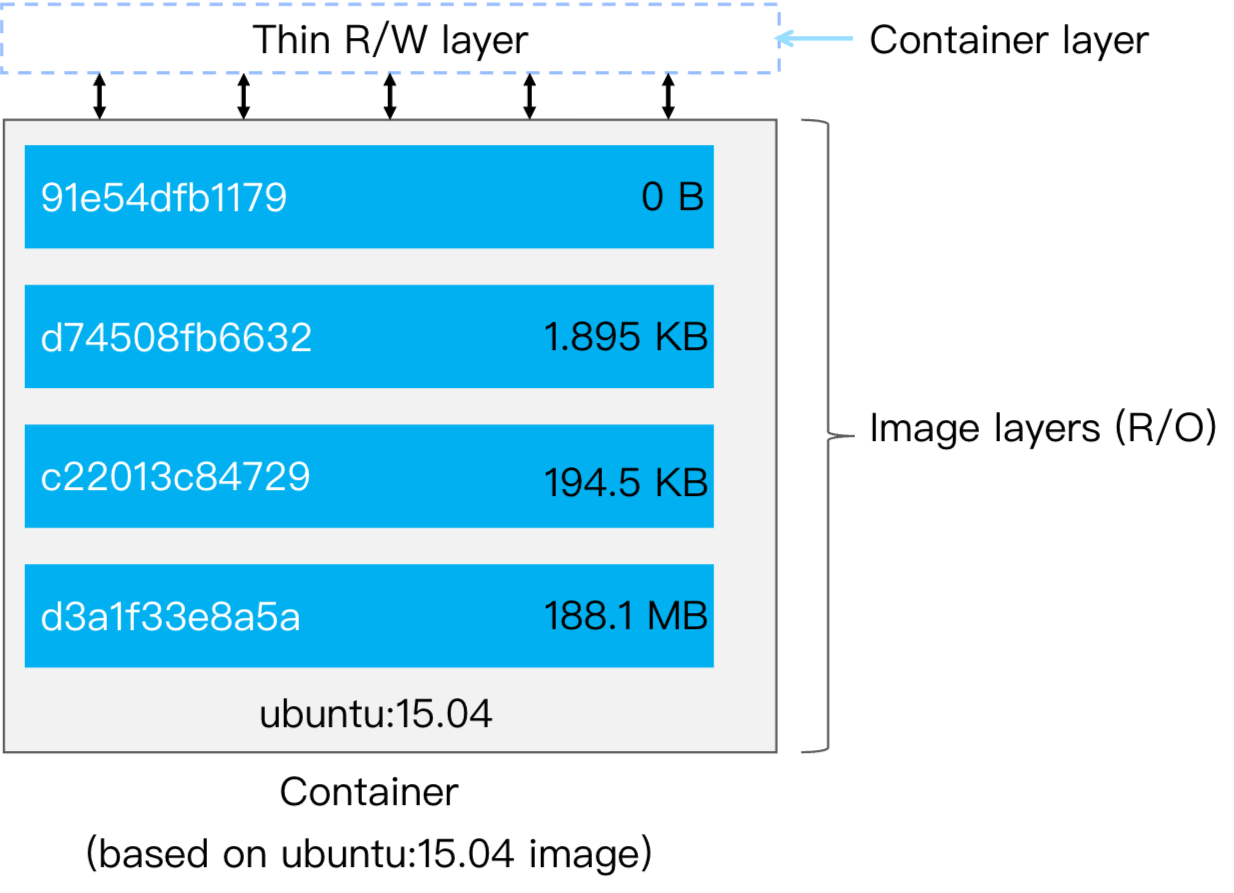
镜像分层 OverlayFS
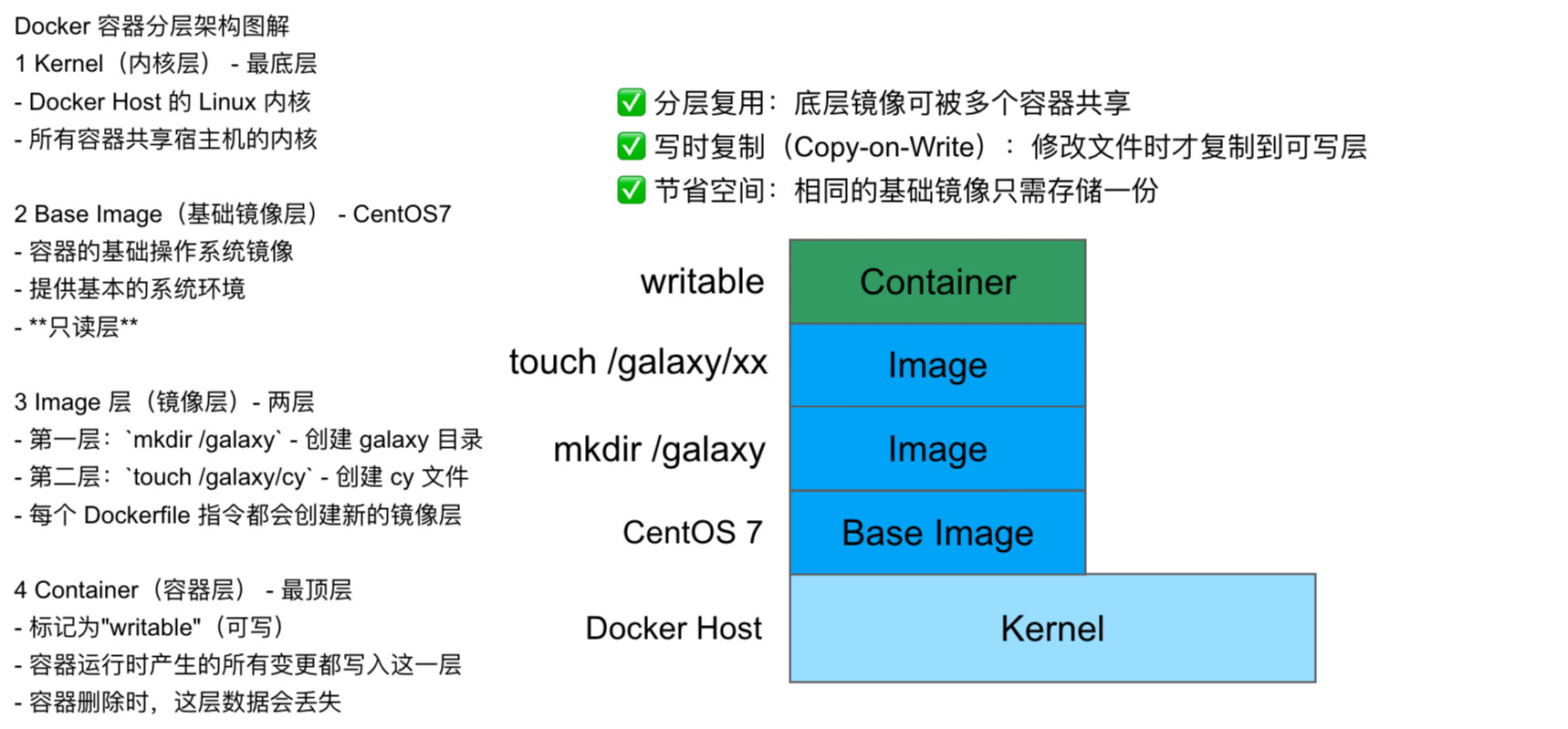
OverlayFS 的核心概念
OverlayFS 是一种联合文件系统(Union Filesystem),它通过堆叠多层目录实现文件系统的叠加,主要分为:
-
Lower Dir(镜像层):只读的基础层(可以是多个,对应 Docker 镜像的每一层)。
-
Upper Dir(容器层):可写层,容器运行时新增或修改的文件会存储在这里。
-
Merged Dir(合并视图):用户看到的最终统一文件系统,是上下层叠加后的结果。同名文件上层覆盖下层,访问文件时优先从 upperdir 读取。
OverlayFS 的工作示例
假设镜像层(lowerdir)有一个文件 /galaxy,而容器层(upperdir)也创建了同名文件:
# 镜像层(只读)
lowerdir/
└── galaxy # 内容:"Hello from image"
# 容器层(可写)
upperdir/
└── galaxy # 内容:"Hello from container"
# 用户看到的合并视图
merged/
└── galaxy # 实际显示 "Hello from container"(上层覆盖下层)当删除容器层的 galaxy 文件时,容器层会创建 whiteout 文件:
# 容器层
upperdir/
└── galaxy # 特殊字符文件表示删除
# 合并视图
mergeddir/
└── galaxy # 文件消失(实际被隐藏)Docker 如何使用 OverlayFS
- 镜像层:Docker 镜像的每一层(如
FROM alpine、RUN apk add)都是 lowerdir。 - 容器层:启动容器时创建的 upperdir 是可写层,存储所有运行时修改。
- 性能优化:OverlayFS 通过写时复制(Copy-on-Write)避免直接修改镜像层,提升效率。
验证 Docker 的存储驱动
运行以下命令查看 Docker 是否使用 OverlayFS
docker info | grep "Storage Driver"输出示例:
Storage Driver: overlay2Namespace 和 cgroups
- Namespace:实现容器环境隔离,隔离进程、网络、挂载、主机名等资源
- Cgroups:实现容器资源限制,管控 CPU、内存、磁盘 IO 使用上限 二者结合,是容器轻量化运行的底层核心。
Part 2 镜像构建与存储管理(ay1 下午)
这一部分从“如何得到镜像”过渡到“数据如何存储”。核心主线是:先理解命令式与声明式构建,再理解 Dockerfile,最后理解容器可写层、Bind Mount、Volume 与底层 OverlayFS 的关系。
练习仓库:https://cnb.cool/docker-666/hust-camp/exercises/-/tree/main
上节课我们学习了 Docker 概述,并实操理解了 Docker 三个核心概念:镜像、容器、仓库。 并且我们已经会使用 Docker 官方提供的镜像,启动容器。
但是这些镜像不能满足我们的需求,比如想定制一个个性化的环境,安装一些特定的软件,这个时候就需要我们自定义镜像。
本节课我们会学习两种自定义镜像的方式,一种是命令式创建镜像,一种是声明式创建镜像。 我们先从最简单的镜像创建方式开始,命令式创建镜像。
命令式创建镜像(从容器创建镜像)
案例
创建一个自定义镜像,基于 alpine 镜像,并安装 figlet 工具。 (figlet:输出艺术字符串的小工具)
1. 启动一个基础容器
docker run -it --name alpine alpine2. 向容器中安装 figlet 工具
然后我们进入容器,在容器中执行一些命令(安装一个软件),然后退出容器。
docker exec -it alpine /bin/sh
apk update
apk add figlet
exit这样,我们就在 alpine 容器中安装了 figlet 工具。
3. 保存容器为镜像
然后我们需要将这个新的容器环境跟其他人分享,我们可以通过 commit 命令将容器保存为一个镜像。
docker ps -a #查看容器
docker commit ${container_id} alpine-figlet这样,我们就创建了一个名为 alpine-figlet 的镜像。
4. 使用新镜像
最后我们就可以使用这个新的镜像了, 运行体验下艺术字生成的效果。
docker run alpine-figlet figlet "hello docker"5. 推送镜像
最后我们也可以使用 docker push 命令将镜像推送到镜像仓库中,其他人便可以使用 docker pull 来使用这个镜像了。
上述从容器创建镜像的方式虽然简单易懂,但是考虑真实项目中,我们可能需要安装很多工具,比如 git,vim,curl,wget 等等。如果我们每次都使用这种方式来创建镜像,就会非常麻烦,并且容易出错。
命令式创建的局限性
- 不可重复性:容器安装过程依赖人工操作,无法保证环境一致性
- 臃肿镜像:容器可能包含临时文件/缓存,导致镜像体积膨胀
- 安全风险:无法追溯安装过程,可能存在安全隐患
- 维护困难:无法版本化管理构建步骤
因此,我们需要一种更加方便的镜像创建方式,这就是 Dockerfile。
声明式创建镜像(Dockerfile)
案例
我们来使用 Dockerfile 来自定义一个同样的镜像。它的格式是:
docker build -t alpine-figlet-from-dockerfile .
docker run alpine-figlet-from-dockerfile figlet "hello docker"这样当我们需要安装 git 的时候,只需要修改 Dockerfile 中的命令后重新构建镜像即可。
docker build -t alpine-figlet-from-dockerfile .
docker run alpine-figlet-from-dockerfile gitDockerfile:
FROM alpine:latest
RUN apk update &&\
apk add figlet什么是构建上下文
docker build [OPTIONS] PATH | URL | -
^^^^^^^^^^^^^^本课程只讨论本地构建,可以指定相对或者绝对文件路径。
Docker 会从构建上下文中寻找文件名为 Dockerfile 的文件,没有这个文件则需要使用 -f 参数来指定 Dockerfile 的路径。
如果把这个目录作为构建上下文,那么 Docker 会在构建时将整个目录传递给 Docker Daemon。
提示:这也是为什么需要
.dockerignore文件的原因 — 避免将不必要的文件(如node_modules、.git)发送给 Daemon,拖慢构建速度。
小结
关于 Dockerfile,上节课我们介绍部署技术历史中提及过,它的出现,帮助 Docker 成为容器化时代下最受欢迎的方案。
那它到底是什么呢?
Dockerfile 是一种静态文件,用来声明镜像的内容。
Dockerfile 为什么如此重要呢?
Dockerfile 给容器化实践提供了一种规范,让创建镜像的操作简单化、标准化。 简单化让开发者可以快速上手,标准化让镜像可以重复使用、可移植、可复用。这些好处从侧面上推动了 Docker 的普及。
Dockerfile 实践 & 关键语法介绍
为了上手书写 Dockerfile,我们还要学习它的语法。我们通过两个案例来学习。
使用 Dockerfile 构建一个 jupyter notebook 镜像
让我们使用 Docker 来构建一个真实可用的镜像,比如 jupyter notebook 镜像。Dockerfile
docker build -t jupyter-sample jupyter_sample/该镜像使用 RUN 指令来安装 jupyter notebook,使用 WORKDIR 指令设置工作目录, 使用 COPY 指令将代码复制到镜像中,使用 EXPOSE 指令来暴露端口, 最后使用 CMD 指令来启动 jupyter notebook 服务。
使用上述镜像来启动 jupyter notebook 服务。
docker run -d -p 8888:8888 jupyter-sample我们使用了 -p 参数来将容器内的 8888 端口映射到宿主机的 8888 端口,在 cnb 上我们可以通过添加一个端口映射来实现外网访问。

点击这个浏览器图标,就可以访问 jupyter notebook 服务了。
使用多阶段构建来打包一个 golang 应用
在实际开发中,我们经常需要构建 golang 应用。 如果使用传统的单阶段构建,最终的镜像会包含整个 Go 开发环境,导致镜像体积非常大。 通过多阶段构建,我们可以创建一个非常小的生产镜像。
创建一个 main.go 文件, 一个普通构建的 Dockerfile 以及一个多阶段构建的 Dockerfile
构建镜像:
docker build -t golang-demo-single -f golang_sample/Dockerfile.single golang_sample/
docker build -t golang-demo-multi -f golang_sample/Dockerfile.multi golang_sample/运行容器:
docker run -d -p 8080:8080 golang-demo-single
docker run -d -p 8081:8081 golang-demo-multi容器运行成功后可以通过如下命令行来访问,可以看到两个容器都是在运行我们写的 golang 服务。
curl http://localhost:8080
curl http://localhost:8081让我们来对比一下单阶段构建和多阶段构建的区别:
# 查看镜像大小
docker images | grep golang-demo你会发现最终的镜像只有几十 MB,而如果使用单阶段构建(直接使用 golang 镜像),镜像大小会超过 1GB。这就是多阶段构建的优势:
- 最终镜像只包含运行时必需的文件
- 不包含源代码和构建工具,提高了安全性
- 大大减小了镜像体积,节省存储空间和网络带宽
这种构建方式特别适合 Go 应用,因为 Go 可以编译成单一的静态二进制文件。在实际开发中,我们可以使用这种方式来构建和部署高效的容器化 Go 应用。
Dockerfile 命令
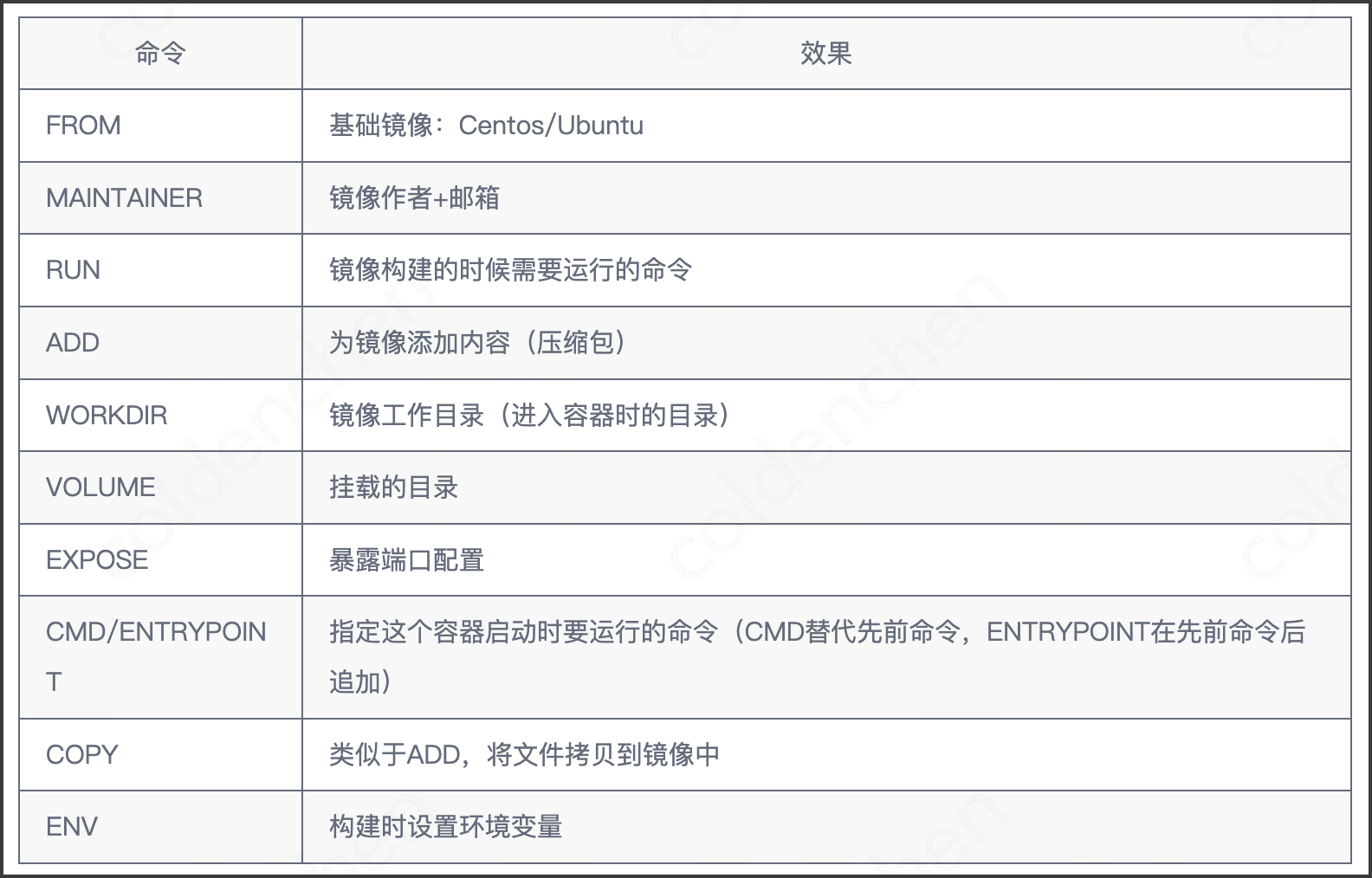
构建过程
- 每个保留关键字(指令)都必须是大写字母
- 从上到下顺序执行
- ”#” 表示注释
- 每一个指令都会创建并提交一个新的镜像层
CMD 和 ENTRYPOINT 的区别
- CMD:指定容器启动时要运行的命令,只有最后一个 CMD 会生效,且可被
docker run的参数覆盖 - ENTRYPOINT:指定容器启动时要运行的命令,
docker run的参数会作为额外参数追加
场景示例:
假设你的 Dockerfile 如下:
Dockerfile
ENTRYPOINT ["python", "app.py"]
CMD ["--help"]- 执行
docker run my-image: 容器实际运行的是:python app.py --help。 - 执行
docker run my-image --version: 这里的--version会覆盖CMD里的--help。 容器实际运行的是:python app.py --version。
Dockerfile 优化技巧
-
层合并:合并 RUN 指令减少镜像层数
RUN apk update && \ apk add --no-cache figlet git && \ rm -rf /var/cache/apk/* -
多阶段构建:构建多个镜像层,最后只保留最终的镜像层
-
使用
.dockerignore文件:忽略不需要的文件,减少构建上下文体积 -
避免硬编码敏感信息:不要在 Dockerfile 中写入密码等敏感信息,推荐在运行时通过环境变量注入
# 运行时注入敏感信息(推荐) docker run -e DB_PASSWORD=xxx image注意:避免使用
ARG+ENV将密码写入镜像,因为docker history可以查看到明文值。# 反例:密码会明文保留在镜像层中 ARG DB_PASSWORD ENV DB_PASSWORD=${DB_PASSWORD}构建时传入
docker build --build-arg DB_PASSWORD=secret .,之后任何人执行docker history即可看到密码明文。 -
使用特定版本的基础镜像:避免因基础镜像更新导致的不稳定性
# 明确指定版本 FROM alpine:3.14
Docker 容器在运行时会产生大量数据,这些数据如何持久化和管理是一个重要的话题。 本节我们将通过一个 Nginx Web 服务器的案例,来深入探讨 Docker 的三种数据管理方式。
Docker 存储基础
Docker 提供了三种主要的数据管理方式:
- 默认存储:容器内的数据随容器删除而丢失
- Bind Mounts(绑定挂载):将主机上的目录或文件直接挂载到容器中
- Volumes(卷):由 Docker 管理的持久化存储空间,完全独立于容器的生命周期
让我们通过一个 Nginx Web 服务器的例子来理解这三种方式的区别。我们将在每种方式下执行相同的操作:创建一个 HTML 文件,然后测试数据的持久性。
场景一:默认存储(非持久化)
在这个场景中,我们直接在容器内创建文件,看看数据会发生什么:
# 运行一个 nginx 容器
docker run -d --name web-default -p 8000:80 nginx
# 在容器中创建一个测试页面
docker exec -it web-default /bin/sh
echo "<h1>Hello from Default Storage</h1>" > /usr/share/nginx/html/index.html
exit
# 访问页面验证内容
curl http://localhost:8000
# 获取容器在宿主机上的实际存储路径(MergedDir)
docker inspect -f '{{.GraphDriver.Data.MergedDir}}' <container_id>
# 删除容器
docker stop web-default
docker rm web-default
# 用同样的配置重新运行容器
docker run -d --name web-default-2 -p 8000:80 nginx
# 再次访问页面,内容不存在
curl http://localhost:8000关于 MergedDir:容器目录本质上是宿主机目录的一个子目录,通过 Linux 的 chroot 技术实现隔离。当容器使用联合文件系统(如 overlay2)时,
MergedDir是所有镜像层最终合并后在宿主机上的实际路径。容器目录对宿主机隔离,一般禁止直接访问。
为什么数据会丢失?理解 Docker 的分层存储
Docker 使用 OverlayFS(联合文件系统) 来管理容器的文件系统,它由多个层组成:
┌─────────────────────────────────┐
│ 容器可写层(Container Layer) │ ← 你在容器中创建/修改的文件都在这里
│ 生命周期 = 容器生命周期 │ ← 容器删除时,这一层也被删除!
├─────────────────────────────────┤
│ 镜像只读层 3(Nginx 配置) │
├─────────────────────────────────┤
│ 镜像只读层 2(Nginx 程序) │ ← 这些层是只读的,多个容器共享
├─────────────────────────────────┤
│ 镜像只读层 1(基础系统) │
└─────────────────────────────────┘工作原理:
- 当你
docker run时,Docker 在镜像层之上创建一个可写层 - 容器内的所有写操作(创建文件、修改文件)都发生在这个可写层
- 当你
docker rm删除容器时,可写层随之删除,所有修改都丢失 - 镜像层保持不变,下次创建新容器时又是一个”干净”的状态
这就是为什么:
web-default中创建的index.html存储在容器的可写层- 删除
web-default后,可写层被清除 web-default-2是一个全新的容器,有自己的空白可写层,所以看不到之前的文件
Volume 和 Bind Mount 的本质:它们都是绕过可写层,将数据直接存储在容器外部(宿主机),因此不受容器生命周期影响。
场景二:使用 Bind Mount
Bind Mount 将宿主机上的指定目录直接映射到容器内部。数据实际存储在宿主机的文件系统上,容器删除后宿主机上的文件依然存在。
# 创建本地目录
mkdir nginx-content
# 运行 Nginx 容器并挂载本地目录
docker run -d --name web-bind \
-p 8081:80 \
-v $(pwd)/nginx-content:/usr/share/nginx/html nginx
# 在容器中创建一个测试页面
docker exec -it web-bind sh -c 'echo "<h1>Hello from Bind Mounts</h1>" > /usr/share/nginx/html/index.html'
# 访问页面验证内容
curl http://localhost:8081
# 删除容器
docker rm -f web-bind
# 用同样的配置重新运行容器
docker run -d --name web-bind-2 -p 8081:80 \
-v $(pwd)/nginx-content:/usr/share/nginx/html nginx
# 再次访问页面,内容仍然存在
curl http://localhost:8081场景三:使用 Volume
Volume 是由 Docker 引擎管理的存储区域,数据存储在 Docker 的管理目录中(默认 /var/lib/docker/volumes/),完全独立于容器生命周期。相比 Bind Mount,Volume 不依赖宿主机的目录结构,更适合生产环境。
# 创建一个 Docker volume
docker volume create nginx_data
# 运行 Nginx 容器并挂载卷
docker run -d --name web-volume -p 8082:80 -v nginx_data:/usr/share/nginx/html nginx
# 在容器中创建一个测试页面
docker exec -it web-volume sh -c 'echo "<h1>Hello from Volume Storage</h1>" > /usr/share/nginx/html/index.html'
# 访问页面验证内容
curl http://localhost:8082
# 删除容器
docker rm -f web-volume
# 用同样的配置重新运行容器
docker run -d --name web-volume-2 -p 8082:80 \
-v nginx_data:/usr/share/nginx/html nginx
# 再次访问页面,内容仍然存在
curl http://localhost:8082
# 查看卷的详细信息
docker volume ls
docker volume inspect nginx_data三种方式的对比
-
默认存储
- 数据随容器删除而丢失
- 适合存储临时数据
- 容器间数据隔离
- 无需额外配置
-
Bind Mount
- 优点:数据持久化,存储在主机指定位置
- 优点:可以直接在主机上修改文件,开发调试方便
- 不足:目录权限不对等,有安全风险
- 不足:依赖主机文件系统结构,可移植性差
-
Volume
- 数据持久化,独立于容器生命周期
- 数据存储在 Docker 管理区域,安全性好
- 支持多容器共享同一个 Volume
- 可通过 Docker CLI 管理(备份、迁移、删除)
清理操作
完成实验后,可以进行清理:
# 清理容器
docker rm -f web-default web-volume web-volume-2 web-bind web-bind-2
# 清理卷
docker volume rm nginx_data
# 清理本地目录
rm -rf nginx-content存储最佳实践
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 数据库持久化 | Volume | 性能好、Docker 管理、便于备份 |
| 开发环境代码同步 | Bind Mount | 实时修改、IDE 友好 |
| 配置文件注入 | Bind Mount(只读) | 安全、灵活 |
| 临时缓存 | tmpfs | 内存存储、容器停止即清理 |
| 容器日志 | 默认 + 日志驱动 | 避免存储膨胀 |
tmpfs vs 默认存储:两者都是非持久化存储,但有本质区别:
对比维度 默认存储(容器可写层) tmpfs 存储位置 宿主机磁盘 宿主机内存 生命周期 容器删除( docker rm)时丢失容器停止( docker stop)时即丢失读写速度 磁盘 I/O 内存级别(快数个数量级) 是否落盘 是 否,数据从不写入磁盘 数据残留风险 有: docker rm仅标记磁盘块为可用,实际数据未被覆写,理论上可通过磁盘恢复工具找回无:数据仅存在于内存,停止即彻底消失 适用场景 普通临时文件(日志、pid) 敏感信息临时存放、高频读写缓存 # tmpfs 示例:在容器内 /app/cache 挂载 64MB 内存文件系统 docker run -d --name tmpfs-demo --tmpfs /app/cache:rw,size=64m nginx安全建议:密码、token、密钥等敏感信息应使用 tmpfs 而非默认存储,确保数据从不落盘,避免容器删除后敏感数据仍残留在宿主机磁盘上。
实践案例:使用 Volume 部署 MySQL 数据库
我们将通过一个 MySQL 数据库的例子来演示如何使用 Volume 持久化数据。
创建并管理 Volume
# 创建一个数据卷,名称为 mysql_data
docker volume create mysql_data
# 列出所有卷
docker volume ls
# 查看卷信息
docker volume inspect mysql_data运行 MySQL 容器,并挂载卷
# 运行 MySQL 容器并挂载卷
# 备注:MYSQL_ROOT_PASSWORD 是环境变量,用于设置 MySQL 的 root 用户密码
docker run -d \
--name mysql_db \
-e MYSQL_ROOT_PASSWORD=mysecret \
-v mysql_data:/var/lib/mysql \
mysql:8.0安全提示:此处密码仅用于演示。生产环境中应使用 Docker Secrets 或外部密钥管理服务来注入敏感信息,避免明文暴露。
# 进入容器创建测试数据
docker exec -it mysql_db mysql -uroot -pmysecret -h127.0.0.1
# 在 MySQL 中创建测试数据
mysql> CREATE DATABASE test_db;
mysql> USE test_db;
mysql> CREATE TABLE users (id INT, name VARCHAR(50));
mysql> INSERT INTO users VALUES (1, 'John Doe');
mysql> exit验证数据持久化
# 删除原容器
docker rm -f mysql_db
# 使用同一个卷启动新容器
docker run -d \
--name mysql_db2 \
-e MYSQL_ROOT_PASSWORD=mysecret \
-v mysql_data:/var/lib/mysql \
mysql:8.0
# 验证数据是否存在
docker exec -it mysql_db2 \
mysql -uroot -pmysecret -e "USE test_db; SELECT * FROM users;"总结
Docker 提供了多种数据管理方式,核心原则是:需要持久化的数据不应存放在容器可写层中。开发环境优先使用 Bind Mount 实现代码实时同步,生产环境优先使用 Volume 保障数据安全和可管理性。根据实际场景选择合适的存储方式,是构建稳定容器化应用的关键。
Part 3 网络管理、Compose 与多容器协作(day2 上午)
这一部分关注多容器应用真正跑起来时的协作问题:容器如何互联、如何组织多个服务、如何管理环境变量,以及如何把单容器能力升级为多服务系统。
Docker 网络是容器通信的基础设施,它使容器能够安全地进行互联互通。在 Docker 中,每个容器都可以被分配到一个或多个网络中,容器可以通过网络进行通信,就像物理机或虚拟机在网络中通信一样。
Docker 网络命令详解
在开始学习不同类型的网络之前,我们先来了解一下 Docker 的常用网络命令:
# 列出所有网络
docker network ls
# 创建自定义网络
docker network create [options] <network-name>
# 检查网络详情
docker network inspect <network-name>
# 将容器连接到网络
docker network connect <network-name> <container-name>
# 断开容器与网络的连接
docker network disconnect <network-name> <container-name>
# 删除网络
docker network rm <network-name>
# 删除所有未使用的网络
docker network prune网络类型及实践案例
容器默认网络
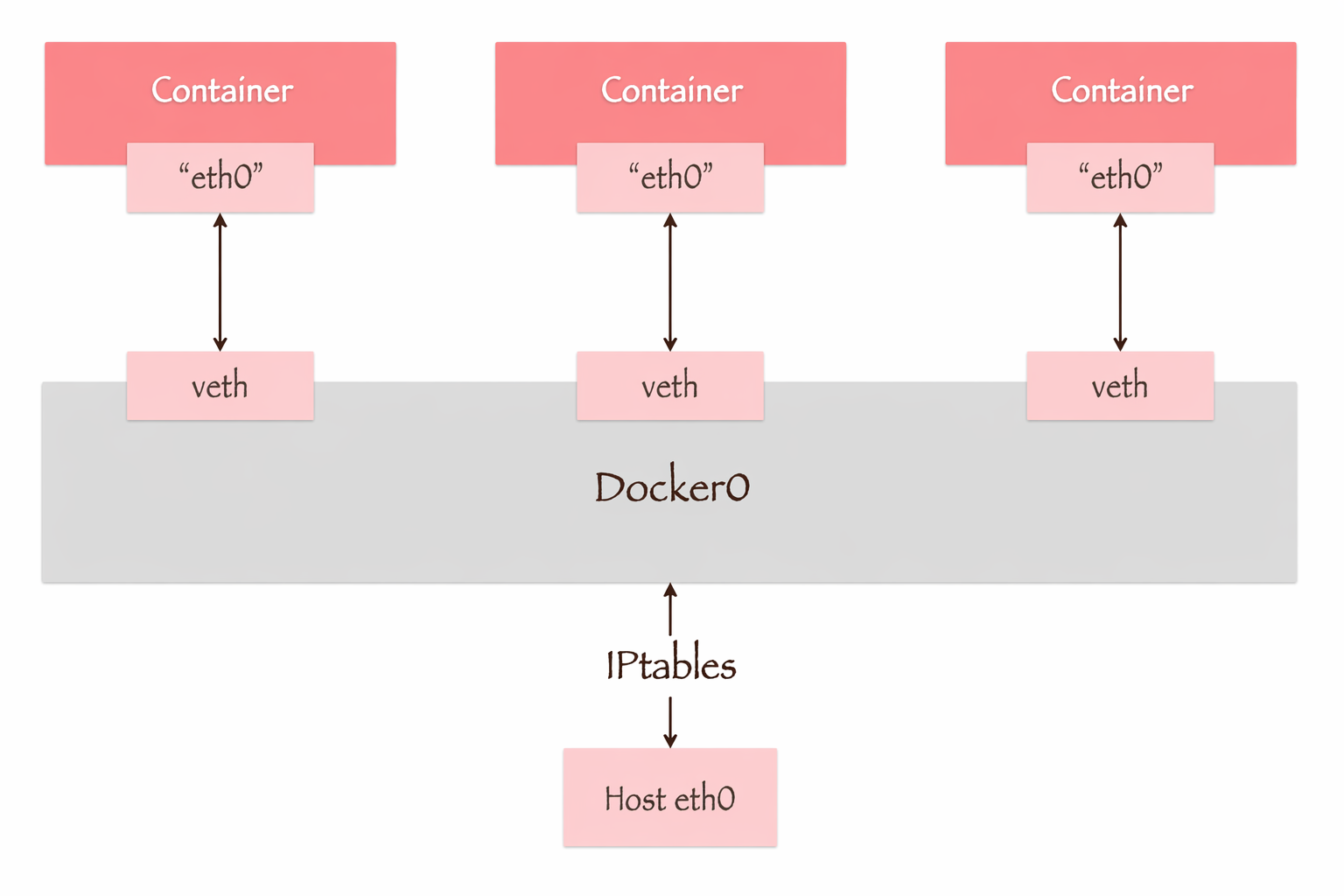
新创建一个容器时,会默认连接到一个叫”默认 Bridge”的网络。而所有连接该网络的容器可以通过这座”桥梁”通信。
Q:这个”默认 Bridge 网络”是什么?是谁创建的?它的通信原理是?
A:它是由 Docker 自动创建的,是一个名为
docker0的 Linux 网桥(使用ip addr命令可以看到),功能上就像是一个虚拟的交换机,将容器相互连接,容器之间可以通过这个网桥进行通信。连接到它的每个容器都会被分配一个 IP 地址,相互之间可以通过 IP 地址进行通信。
Q:除了 Bridge 网络,还有哪些网络类型?
A:除了 Bridge 网络,Docker 还支持 Host 网络、None 网络和自定义网络。Host 网络直接将容器连接到主机网络,None 网络禁用了容器的网络功能,自定义网络则允许用户创建自己的网络。这些网络类型各有优缺点,可以根据实际需求选择使用。接下来,我们将分别介绍这些网络类型及其实践案例。
1. Bridge 网络
实践案例一:默认 Bridge 网络
让我们先来看看默认 bridge 网络的行为:
# 启动两个 nginx 容器
docker run -d --name container1 nginx
docker run -d --name container2 nginx
# 查看默认 bridge 网络的 ID
docker network ls
docker network inspect bridge -f '{{.ID}}'
# 或者 docker network inspect bridge | jq '.[0] | {Id, Name, Driver}'
# 查看容器是否连接到默认 bridge 网络
docker network inspect bridge -f '{{.Containers}}'
docker inspect container1 -f '{{range .NetworkSettings.Networks}}{{.NetworkID}}{{end}}'
docker inspect container2 -f '{{range .NetworkSettings.Networks}}{{.NetworkID}}{{end}}'
# 查看容器的 IP 地址
docker inspect container1 -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'
docker inspect container2 -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'
# 进入容器1,尝试通过 IP 访问容器2(IP 需根据上一步的实际输出替换)
docker exec -it container1 curl http://172.17.0.3
# 注意:在默认 bridge 网络中,无法通过容器名称访问
docker exec -it container1 curl http://container2 # 这将失败在默认 bridge 网络下,容器之间只能通过 IP 地址互相访问,不支持通过容器名称来通信。通过 IP 访问需要记住容器的 IP 地址,这显然不是个好办法。
实践案例二:自定义 Bridge 网络
为了解决这个限制,Docker 提供了用户自定义 bridge 网络的功能。 通过创建自定义 bridge 网络,容器可通过稳定的名称直接互访,无需依赖 IP 地址,从而简化了记忆 IP 的难度。
接下来,我们在案例中使用自定义网络:尝试将两个容器连接到同一个网络,然后通过容器名称进行通信:
# 创建自定义 bridge 网络
docker network create \
--driver bridge \
my-bridge-network
# 启动两个容器,连接到自定义网络
docker run -d \
--name custom-container1 \
--network my-bridge-network \
nginx
docker run -d \
--name custom-container2 \
--network my-bridge-network \
nginx
# 现在可以通过容器名称访问
docker exec -it custom-container1 curl http://custom-container2Docker 中默认的
bridge网络与自定义bridge网络在容器名称解析上的差异,核心原因在于 DNS 服务的启用机制 和 网络配置的隔离性。默认的bridge网络(即docker0虚拟网桥)不提供容器名称解析功能。容器间若需通信,必须通过 IP 地址。因此默认网络下的容器 IP 可能因重启或容器重建而变化,导致依赖 IP 的通信失效。而自定义
bridge网络启用 Docker 内置的 DNS 服务器(127.0.0.11),容器可通过名称直接解析其他容器的 IP 地址。容器启动时,Docker 自动将/etc/resolv.conf中的 DNS 服务器指向127.0.0.11。# Generated by Docker Engine. # This file can be edited; Docker Engine will not make further changes once it # has been modified. nameserver 127.0.0.11 options ndots:0 # Based on host file: '/etc/resolv.conf' (internal resolver) # ExtServers: [10.235.16.19 183.60.83.19 183.60.82.98] # Overrides: [nameservers] # Option ndots from: host而使用默认 bridge 网络创建的容器,
/etc/resolv.conf文件中的内容如下(nameserver是 Docker 引擎根据宿主机 DNS 配置自动生成的):# Generated by Docker Engine. # This file can be edited; Docker Engine will not make further changes once it # has been modified. nameserver 10.235.16.19 nameserver 183.60.83.19 nameserver 183.60.82.98 options ndots:0 # Based on host file: '/etc/resolv.conf' (legacy) # Overrides: [nameservers] # Option ndots from: host
运行完两个实践案例后运行 ip addr:
或者
ip -c -brief addr,一行显示一个网络接口,简洁直观或者
ip -j addr | jq,JSON 格式输出
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:04:e2:12:94 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:4ff:fee2:1294/64 scope link
valid_lft forever preferred_lft forever
4: veth05895da@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 4a:ef:37:ba:83:f7 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::48ef:37ff:feba:83f7/64 scope link
valid_lft forever preferred_lft forever
6: veth6c3945d@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 9a:7f:92:75:ab:4c brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::987f:92ff:fe75:ab4c/64 scope link
valid_lft forever preferred_lft forever
7: br-b99d1aa4ad94: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:8a:15:98:5a brd ff:ff:ff:ff:ff:ff
inet 172.19.0.1/16 brd 172.19.255.255 scope global br-b99d1aa4ad94
valid_lft forever preferred_lft forever
inet6 fe80::42:8aff:fe15:985a/64 scope link
valid_lft forever preferred_lft forever
9: vethf02e559@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-b99d1aa4ad94 state UP group default
link/ether 8a:27:a3:8e:3f:61 brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::8827:a3ff:fe8e:3f61/64 scope link
valid_lft forever preferred_lft forever
11: vethdd4a1c7@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-b99d1aa4ad94 state UP group default
link/ether 5e:d7:fd:f7:7b:b6 brd ff:ff:ff:ff:ff:ff link-netnsid 4
inet6 fe80::5cd7:fdff:fef7:7bb6/64 scope link
valid_lft forever preferred_lft forever
363437: eth0@if363438: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:10 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.16/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever在 container1 中执行 ip addr:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever在 custom-container1 中执行 ip addr:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
8: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.19.0.2/16 brd 172.19.255.255 scope global eth0
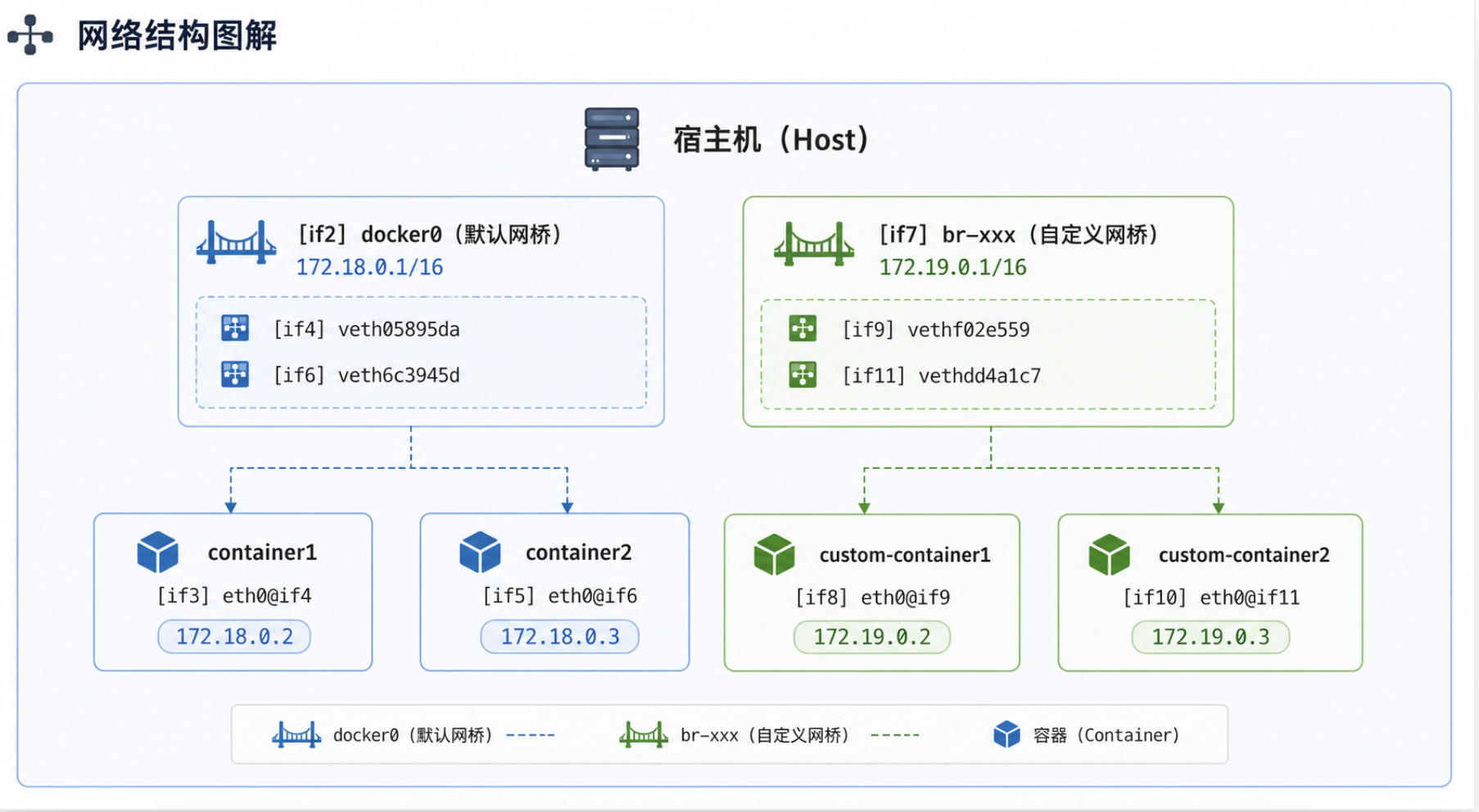
valid_lft forever preferred_lft forever网络结构图解
关键点解读
1. 两个网桥,互相隔离
| 网桥 | 名称 | 连接的容器 |
|---|---|---|
docker0 | 默认 bridge 网络 | container1, container2 |
br-b99d1aa4ad94 | 自定义 bridge 网络 | custom-container1, custom-container2 |
2. ifindex(接口序号)
ip addr 输出中每行开头的数字就是 ifindex(interface index),它是内核为每个网络接口分配的唯一标识:
1: lo ← 序号 1
2: docker0 ← 序号 2
4: veth05895da@if3 ← 序号 4(序号 3 的接口已被删除,不会回收)
7: br-b99d1aa4ad94 ← 序号 7ifindex 有三个关键特性:
- 全局唯一:同一网络命名空间内不会重复
- 单调递增:每创建一个新接口序号 +1,永不回退
- 删除不回收:接口销毁后序号作废,因此输出中会出现不连续的数字(如缺少 3、5)
@ifX 的含义:表示 veth pair 对端的 ifindex,是定位”网线另一头”的关键依据:
4: veth05895da@if3
↑ 本端 ifindex=4(在宿主机) ↑ 对端 ifindex=3(在容器内,即容器的 eth0)3. eth0 与 veth
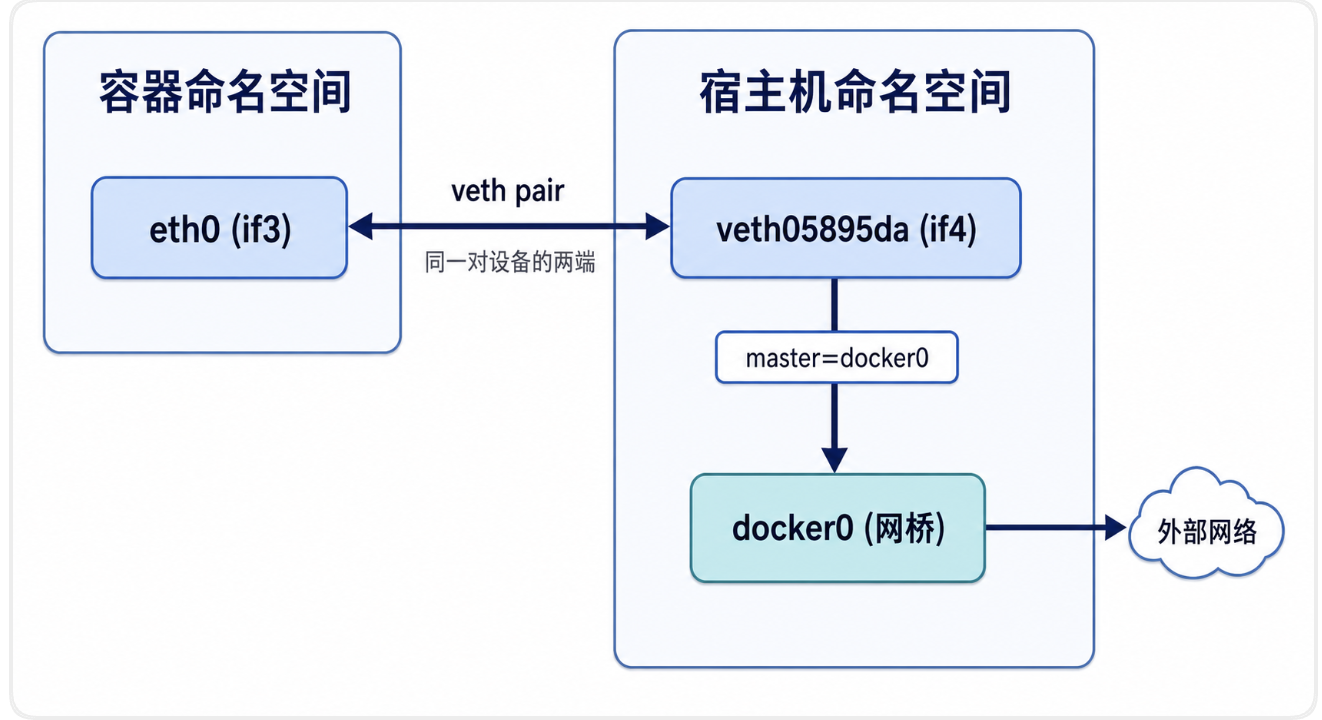
-
eth0 是容器内部看到的主网络接口,就像一台电脑的网卡。每个容器都有自己独立的
eth0,这是 Linux Network Namespace 隔离的结果——容器以为自己独占一套网络栈。 -
veth(Virtual Ethernet)是成对创建的虚拟网络设备。一端在容器内(就是
eth0),另一端在宿主机上(就是vethXXX)。
| 概念 | 物理世界类比 |
|---|---|
eth0 | 电脑上的网口 |
vethXXX | 网线的另一头(插在交换机上) |
docker0 / br-xxx | 交换机 |
| veth pair | 一根网线(两头不可分离) |
关键点:
eth0和vethXXX是同一个 veth pair 的两端——从容器内看叫eth0,从宿主机看叫vethXXX。数据从容器eth0发出后自动到达宿主机的vethXXX,再经网桥转发到目标。每创建一个容器,Docker 就创建一对 veth,容器删除时这对 veth 一起销毁。
4. veth pair 对应关系
每个容器通过 veth pair 连接到网桥,就像一根虚拟网线的两端:
容器内: eth0@if4 <──────────────> 宿主机: veth05895da@if3
└─ 一对虚拟网卡,像一根网线的两端 ─┘对应关系(通过 @ifX 序号匹配): 4 个 veth* 接口 ↔ 4 个运行中的容器
| 容器 | 容器内网卡 | 宿主机 veth | 所属网桥 |
|---|---|---|---|
| container1 | eth0@if4 | veth05895da@if3 | docker0 |
| container2 | eth0@if6 | veth6c3945d@if5 | docker0 |
| custom-container1 | eth0@if9 | vethf02e559@if8 | br-b99d1aa4ad94 |
| custom-container2 | eth0@if11 | vethdd4a1c7@if10 | br-b99d1aa4ad94 |
5. 自定义网络不使用 docker0
从 ip addr 输出可以清楚看到,veth 设备的 master 字段指明了所属网桥:
# 默认网络的容器 → master docker0
veth05895da@if3: ... master docker0 ...
veth6c3945d@if5: ... master docker0 ...
# 自定义网络的容器 → master br-b99d1aa4ad94
vethf02e559@if8: ... master br-b99d1aa4ad94 ...
vethdd4a1c7@if10: ... master br-b99d1aa4ad94 ...这就是为什么不同 bridge 网络的容器默认无法互通——它们连接在不同的虚拟交换机上。
2. Host 网络
Host 网络移除了容器和 Docker 主机之间的网络隔离,直接使用主机的网络。
特点:
- 最佳网络性能
- 直接使用主机的网络栈
- 没有网络隔离
- 端口直接绑定到主机上
实践案例:使用 Host 网络运行 Nginx 服务器
# 启动一个 Nginx 容器,使用 host 网络(为了避免端口冲突,容器1 启动 alpine/curl 即可)
docker run -itd \
--name host1 \
--network host \
alpine \
sh -c "apk add --no-cache curl && sh"
docker run -d \
--name host2 \
--network host \
nginx
# 查询宿主机端口 eth0 是 HOST_IP
ip addr
# 登入容器1,通过宿主机ip访问容器2
docker exec -it host1 curl http://${HOST_IP}:80
# 注意:因为容器使用主机的网络端口,而主机的端口一旦使用,就不能再被其他容器使用,否则会提示端口冲突。
docker run -d \
--name host-3 \
--network host \
nginx
docker logs host-3
# 精简镜像可能没有 ip/ifconfig:可以临时安装
# Debian/Ubuntu:apt-get update && apt-get install -y iproute23. Container 网络
Container 网络模式允许一个容器共享另一个容器的网络命名空间,两个容器将拥有相同的 IP 地址、网络接口和端口空间。
特点:
- 多个容器共享同一个网络栈
- 共享 IP 地址和端口空间
- 容器间可通过
localhost直接通信 - Kubernetes Pod 多容器网络的实现基础
应用场景:
- Sidecar 模式(如日志收集、代理)
- 需要紧密网络协作的容器组
- 模拟 Kubernetes Pod 行为
实践案例:两个容器共享网络命名空间
# 1. 启动网络提供者容器(运行 nginx)
docker run -d --name net-provider nginx
# 2. 启动网络消费者,共享网络(后台运行,保持容器存活)
docker run -d --name net-consumer --network container:net-provider alpine sleep 3600
# 3. 在 net-consumer 容器内,通过 localhost 访问 nginx
docker exec net-consumer wget -qO- http://localhost:80
# 输出: nginx 欢迎页面 HTML
# 4. 查看 net-provider 的 IP 地址
docker inspect net-provider -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'
# 输出示例: 172.17.0.2
# 5. 在 net-consumer 容器内查看网络接口
docker exec net-consumer ip addr
# 输出示例:
# 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 ...
# inet 127.0.0.1/8 scope host lo
# 18: eth0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
# inet 172.17.0.2/16 ... ← 与 net-provider 的 IP 完全相同
# 6. 确认 net-consumer 的网络模式
docker inspect net-consumer -f '{{.HostConfig.NetworkMode}}'
# 输出: container:<net-provider-id>
# 7. 验证端口空间共享(80端口已被 nginx 占用)
docker exec net-consumer sh -c "nc -l -p 80"
# 输出: nc: bind: Address already in use
# 说明两个容器共享同一个端口空间与其他网络模式对比:
| 特性 | Bridge 网络 | Host 网络 | Container 网络 |
|---|---|---|---|
| 网络隔离 | 容器间隔离 | 无隔离 | 共享容器间无隔离 |
| IP 地址 | 各自独立 | 使用宿主机 IP | 共享同一 IP |
| localhost 通信 | 不可直接通信 | 与宿主机共享 | 可直接通信 |
| 端口冲突 | 无 | 与宿主机冲突 | 共享容器间冲突 |
Kubernetes Pod 原理:K8s Pod 中的多个容器就是使用类似 Container 网络的机制,共享同一个网络命名空间,因此 Pod 内的容器可以通过
localhost相互访问。
# 清理
docker rm -f net-provider net-consumer4. None 网络
None 网络完全禁用了容器的网络功能,容器在这个网络中没有任何外部网络接口。
特点:
- 完全隔离的网络环境
- 容器没有网络接口
- 适用于不需要网络的批处理任务
实践案例:使用 None 网络运行独立计算任务
# 运行一个计算密集型任务,不需要网络
docker run --network none alpine sh -c 'for i in $(seq 1 10); do echo $((i*i)); done'5. Overlay 网络
Overlay 网络是 Docker 用于实现跨主机容器通信的网络驱动,主要用于 Docker Swarm 集群环境。它通过在不同主机的物理网络之上创建虚拟网络,使用 VXLAN 技术在主机间建立隧道,从而实现容器间的透明通信。
特点:
- 支持跨主机容器通信
- 使用 VXLAN 技术建立隧道
- 每个容器获得虚拟 IP
- 支持网络加密
- 提供负载均衡和服务发现
应用场景:
- 微服务架构
- 分布式应用
- 分布式数据库集群
- 消息队列集群
- 需要跨主机通信的容器化应用
在 Overlay 网络中,容器之间可以直接通过虚拟 IP 进行通信,而不需要关心容器具体运行在哪个主机上。Overlay 网络支持网络加密,能确保跨主机通信的安全性, 同时还提供了负载均衡和服务发现等特性,是构建大规模容器集群的重要基础设施。
注意:Overlay 网络需要 Docker Swarm 或其他集群编排工具支持,本课程环境为单机,因此仅做原理介绍。
6. macvlan/ipvlan 网络
让容器获得”局域网中的独立 IP”,适合对接传统网络;需网络环境与路由配置到位。
注意:macvlan/ipvlan 网络依赖特定的网络环境配置(如网卡混杂模式、路由规则),本课程仅做原理介绍。
课后实践
实际案例:使用自定义 Bridge 网络演示 Web 应用与 Redis 通信
自定义 bridge 网络是目前 Docker 网络通信中最常用的方式。下面通过一个实际案例来演示自定义 bridge 网络的使用。
前置准备:本案例需要使用 web-app 目录下的代码和 Dockerfile,请确保该目录存在。
# 创建web应用的镜像
docker build -t web-app web-app
# 创建自定义bridge网络
docker network create my-bridge-network
# 启动 Redis 容器
docker run -d \
--name redis-server \
--network my-bridge-network \
redis:alpine
# 启动 Web 应用容器
docker run -d \
--name web-app \
--network my-bridge-network \
-p 5000:5000 \
web-app
# 访问应用
curl http://localhost:5000
# 多次访问,观察计数器增加
curl http://localhost:5000
curl http://localhost:5000
# 查看 Redis 中的数据
docker exec -it redis-server redis-cli get hits清理环境
# 删除课后实践容器
docker rm -f web-app redis-server
docker rm -f custom-container1 custom-container2
# 删除默认 bridge 案例容器
docker rm -f container1 container2
# 删除 Host 网络案例容器
docker rm -f host1 host2 host-3
# 删除自定义网络
docker network rm my-bridge-network
# 删除镜像
docker rmi web-app redis:alpineDocker Compose 引言
在前面的课程中,我们学习了如何使用 Docker 容器来运行单个服务。
通过 docker run 命令,我们可以快速启动一个数据库、一个 Web 服务器或者一个缓存服务。这种方式在开发简单应用时非常有效。
然而,随着应用架构的演进,微服务的理念逐渐流行,一个应用由多个服务共同组成。
本节课我们准备了 一个多服务的 web 应用 的案例如下:
web 应用包含四个独立服务
- Nginx: 路由转发服务
- 前端: React 框架开发 提供前端页面服务
- 后端: Node.js 开发 提供后端 API 服务
- 数据库: MongoDB 提供数据库服务
应用架构
四个服务共同组成了应用,整体架构图如下:
graph TD
A[Nginx :8080] --> B[Frontend--React :3000]
A --> C[Backend--Node.js :3001]
C --> D[MongoDB :27017]
试想一下,我们为了部署这个 Web 应用,需要完成哪些工作?
- 为四个服务分别构建镜像
- 拉取 nginx 镜像
- 拉取 mongodb 镜像
- 手动书写前端服务的 Dockerfile,构建镜像
- 手动书写后端服务的 Dockerfile,构建镜像
- 配置容器间公共的基础设施 如 Docker 网络、存储卷等
- 配置服务间的依赖关系 如前端服务依赖后端服务,后端服务依赖数据库等
- 启动容器
可以看到,随着工程复杂度的提升,服务数量增加,手动管理服务容器会变得越来越复杂。 这不仅增加了运维的复杂度,还增加了手动操作出错的概率。
所以我们需要一个工具来对多容器应用进行管理。于是 Docker Compose 应运而生。
Docker Compose 简介
Docker Compose 是一个用于定义和运行多容器的工具。 它允许我们使用 YAML 文件来定义各容器,然后通过一个命令来启动所有服务。
核心步骤
1)书写 docker-compose.yml 文件
- 定义各个服务基本信息(如镜像、端口、环境变量等)
- 定义网络、存储卷等通用设置
- 定义服务之间的依赖关系
2)运行
docker compose up:创建和启动所有服务
docker-compose.yml 语法
3.1 Yaml 文件格式
Docker Compose 使用 YAML 文件来定义服务。 YAML 是一种人类可读的数据序列化语言,它支持多种数据类型,如字符串、数字、列表、映射等。 Docker Compose 使用 YAML 文件来定义服务,因此我们需要了解 YAML 的基本语法。
- 用缩进表示层级关系,必须为偶数个空格
- 三种基本类型:标量(单个值)、映射(键值对)、序列(列表)
3.2 docker-compose.yaml 语法
docker-compose.yml 详解
- 服务 (Services): 容器的定义,包括使用哪个镜像、端口映射、环境变量等
- 网络 (Networks): 定义容器之间如何通信
- 卷 (Volumes): 定义数据的持久化存储
- 依赖关系 (Dependencies): 定义服务之间的启动顺序
- 环境变量 (Environment Variables): 管理不同环境的配置
Docker Compose 原理
流程:
- 解析 YAML 文件
- 检查/创建所需网络、卷
- 创建和启动每个服务的容器
- 统一管理生命周期 • 源码:https://github.com/docker/compose/blob/cb959100188e9bfa2a463d7b0a6e3e1679bd5d0f/pkg/compose/up.go#L39
实践项目:使用 docker compose 构建 Todo 应用
Docker Compose 配置解析
服务定义
-
nginx 服务
- 使用官方 nginx 镜像
- 映射端口 8080,作为应用的访问入口
- 将 nginx.conf 配置文件打包进镜像
-
frontend 服务
- 使用本地 Dockerfile 构建
- 暴露端口 3000,仅容器网络访问
- 设置 API URL 环境变量
- 依赖于 backend 服务
- 使用卷挂载实现热重载
-
backend 服务
- 使用本地 Dockerfile 构建
- 映射端口 3001,仅容器网络访问
- 设置 MongoDB 连接环境变量
- 依赖于 mongodb 服务
- 使用卷挂载实现热重载
-
mongodb 服务
- 使用官方 MongoDB 镜像
- 映射端口 27017,仅容器网络访问
- 使用命名卷持久化数据
网络配置
- Docker Compose 会自动创建一个默认网络 (bridge 模式)
- 所有服务都在同一网络中
- 服务可以通过服务名互相访问
数据持久化
- 使用命名卷
mongodb_data持久化数据库数据 - 使用绑定挂载实现开发时的代码热重载
常用命令演示
docker compose build: 构建镜像docker compose up: 创建和启动所有服务docker compose down: 停止和删除所有服务docker compose ps: 查看服务状态docker compose logs: 查看服务日志
使用说明
-
在后台启动服务
docker compose up -d -
查看服务状态
docker compose ps -
查看服务日志
docker compose logs frontend docker compose logs backend docker compose logs mongodb -
停止所有服务
docker compose down -
重新构建服务
docker compose build [${service}]当 service 省略时,默认构建所有配置了
build的服务。 -
重启单个服务
docker compose restart frontend
环境变量与 .env 文件最佳实践
在实际项目中,我们经常需要管理不同环境(开发、测试、生产)的配置。 Docker Compose 提供了灵活的环境变量管理机制,让我们能够轻松地在不同环境之间切换配置。
6.1 环境变量的三种设置方式
方式一:直接在 compose.yaml 中定义
services:
backend:
image: node:18
environment:
- NODE_ENV=development
- PORT=3001
- DATABASE_HOST=mongodb优点:简单直观,配置集中
缺点:敏感信息(如密码)会暴露在版本控制中
方式二:使用 .env 文件(推荐)
在 compose.yaml 同级目录创建 .env 文件:
# .env 文件
NODE_ENV=development
MONGODB_PORT=27017
MONGODB_DATABASE=todos
MONGODB_ROOT_USER=admin
MONGODB_ROOT_PASSWORD=secret123在 compose.yaml 中引用:
services:
mongodb:
image: mongo:6
environment:
- MONGO_INITDB_ROOT_USERNAME=${MONGODB_ROOT_USER}
- MONGO_INITDB_ROOT_PASSWORD=${MONGODB_ROOT_PASSWORD}
ports:
- "${MONGODB_PORT}:27017"优点:敏感信息与配置分离,可以将 .env 加入 .gitignore
缺点:需要额外维护 .env 文件
方式三:使用 env_file 指令
services:
backend:
image: node:18
env_file:
- ./backend.env # 后端专用配置
- ./common.env # 公共配置优点:可以按服务或功能拆分配置文件
缺点:文件较多时管理复杂
6.2 .env 文件最佳实践
✅ 推荐做法
-
创建
.env.example模板文件# .env.example - 提交到 Git,作为配置模板 NODE_ENV=development MONGODB_PORT=27017 MONGODB_DATABASE=todos MONGODB_ROOT_USER= MONGODB_ROOT_PASSWORD= -
将
.env加入.gitignore# .gitignore .env .env.local .env.*.local -
为不同环境创建专用配置
.env # 默认开发环境 .env.production # 生产环境 .env.test # 测试环境 -
使用有意义的变量命名
# ❌ 不推荐 DB_P=3306 # 推荐 MYSQL_PORT=3306
避免做法
- 不要在 .env 中存储大段文本或 JSON
- 不要将生产环境的 .env 提交到版本控制
- 不要在变量值中使用未转义的特殊字符
6.3 实践案例:优化 Todo 应用的环境变量管理
第一步:创建 .env.example 模板
# 在 5_compose 目录下创建 .env.example
cat > .env.example << 'EOF'
# ===================
# 应用环境配置
# ===================
NODE_ENV=development
# ===================
# 服务端口配置
# ===================
NGINX_PORT=8080
FRONTEND_PORT=3000
BACKEND_PORT=3001
# ===================
# MongoDB 配置
# ===================
MONGODB_PORT=27017
MONGODB_DATABASE=todos
MONGODB_ROOT_USER=admin
MONGODB_ROOT_PASSWORD=
# ===================
# API 配置
# ===================
API_URL=/api
EOF第二步:创建实际的 .env 文件
# 复制模板并填写实际值
cp .env.example .env
# 编辑 .env 文件,填写密码等敏感信息
# MONGODB_ROOT_PASSWORD=your_secure_password_here第三步:优化 compose.yaml 使用环境变量
创建 compose.env.yaml 展示最佳实践:
services:
# Nginx 反向代理
nginx:
build: ./nginx
ports:
- "${NGINX_PORT:-8080}:80" # 提供默认值
depends_on:
- frontend
- backend
# 前端服务
frontend:
build: ./frontend
expose:
- "${FRONTEND_PORT:-3000}"
environment:
- NODE_ENV=${NODE_ENV:-development}
- REACT_APP_API_URL=${API_URL:-/api}
depends_on:
- backend
volumes:
- ./frontend:/app
- /app/node_modules
# 后端服务
backend:
build: ./backend
expose:
- "${BACKEND_PORT:-3001}"
environment:
- NODE_ENV=${NODE_ENV:-development}
- MONGODB_URI=mongodb://${MONGODB_ROOT_USER}:${MONGODB_ROOT_PASSWORD}@mongodb:${MONGODB_PORT:-27017}/${MONGODB_DATABASE:-todos}?authSource=admin
depends_on:
- mongodb
volumes:
- ./backend:/app
- /app/node_modules
# MongoDB 数据库
mongodb:
image: mongo:6
expose:
- "${MONGODB_PORT:-27017}"
environment:
- MONGO_INITDB_ROOT_USERNAME=${MONGODB_ROOT_USER:-admin}
- MONGO_INITDB_ROOT_PASSWORD=${MONGODB_ROOT_PASSWORD:?请在.env文件中设置MONGODB_ROOT_PASSWORD}
- MONGO_INITDB_DATABASE=${MONGODB_DATABASE:-todos}
volumes:
- mongodb_data:/data/db
volumes:
mongodb_data:6.4 环境变量语法详解
| 语法 | 说明 | 示例 |
|---|---|---|
${VAR} | 直接引用变量 | ${MONGODB_PORT} |
${VAR:-default} | 变量未设置时使用默认值 | ${MONGODB_PORT:-27017} |
${VAR:?error} | 变量未设置时报错并退出 | ${PASSWORD:?密码不能为空} |
${VAR:+value} | 变量已设置时使用替代值 | ${DEBUG:+--verbose} |
6.5 验证环境变量配置
# 查看 compose 解析后的完整配置(包含变量替换结果)
docker compose config
# 仅查看某个服务的配置
docker compose config --services
# 验证配置文件语法
docker compose config --quiet && echo "配置文件语法正确"6.6 多环境部署实践
使用 —env-file 指定不同环境
# 开发环境(默认读取 .env)
docker compose up -d
# 生产环境
docker compose --env-file .env.production up -d
# 测试环境
docker compose --env-file .env.test up -d使用 profiles 实现环境差异化
services:
# 仅在开发环境启用的调试工具
mongo-express:
image: mongo-express
profiles:
- debug
environment:
- ME_CONFIG_MONGODB_SERVER=mongodb
ports:
- "8081:8081"
# 启动时包含调试工具
docker compose --profile debug up -d
# 生产环境不包含调试工具
docker compose up -d6.7 小结
| 场景 | 推荐方案 |
|---|---|
| 简单项目/本地开发 | 直接在 compose.yaml 中定义 |
| 团队协作项目 | .env + .env.example 模板 |
| 微服务架构 | env_file 按服务拆分配置 |
| 多环境部署 | .env.{environment} + --env-file |
| 敏感信息管理 | Docker Secrets(生产环境推荐) |
通过合理使用环境变量和 .env 文件,我们可以:
- 实现配置与代码分离
- 保护敏感信息安全
- 简化多环境部署流程
- 提高团队协作效率
Part 4 容器监控、运维与进阶原理(ay2 下午)
这一部分面向运行态和底层实现:如何监控、调试、可视化管理容器,以及继续深入 OverlayFS、RootFS 和 Buildx 这些“为什么 Docker 能这样工作”的原理问题。
在本章节中,我们将学习如何有效地监控和管理 Docker 容器,包括使用命令行工具和图形化界面(Portainer)进行容器管理。
提示:本节所需的容器可以利用上一节 Docker Compose 启动的容器来演示。
1. 容器管理基础
1.1 容器生命周期管理
以下是一些最常用的容器管理命令:
# 列出所有容器(包括停止的容器)
docker ps -a
# 仅列出运行中的容器
docker ps
# 启动容器
docker start <container_id>
# 停止容器
docker stop <container_id>
# 重启容器
docker restart <container_id>
# 删除容器(需要先停止)
docker rm <container_id>
# 强制删除运行中的容器
docker rm -f <container_id>1.2 容器资源监控
Docker 提供了多种方式来监控容器的资源使用情况:
# 实时查看容器资源使用状态
docker stats
# 查看容器资源使用情况(仅显示名称、CPU 和内存)
docker stats --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}"
# 查看容器详细信息
docker inspect <container_id>
# 查看容器内进程
docker top <container_id>
# 查看容器端口映射
docker port <container_id>
docker stats输出字段说明:
字段 说明 NAME 容器名称 CPU % CPU 使用率 MEM USAGE / LIMIT 内存使用量 / 内存限制 NET I/O 网络输入 / 输出 BLOCK I/O 磁盘读 / 写 PIDS 容器内进程数
2. 容器日志与调试
2.1 日志查看
# 查看容器日志
docker logs <container_id>
# 实时查看最新日志
docker logs -f <container_id>
# 查看最近 100 行日志
docker logs --tail 100 <container_id>
# 显示时间戳
docker logs -t <container_id>
# 组合使用:实时查看最近 50 行带时间戳的日志
docker logs -f --tail 50 -t <container_id>2.2 容器调试
# 进入运行中的容器
docker exec -it <container_id> /bin/sh
# 查看容器内文件系统变更
docker diff <container_id>
# 将容器内文件复制到宿主机
docker cp <container_id>:/path/to/file ./local_path
# 将宿主机文件复制到容器内
docker cp ./local_file <container_id>:/path/to/dest3. 实践练习:使用 Portainer 对 Docker 进行可视化管理
Portainer 是一个轻量级的 Docker 管理工具,提供了直观的 Web 界面来管理 Docker 环境。
3.1 安装 Portainer
# 创建 Portainer 数据卷
docker volume create portainer_data
# 运行 Portainer 容器
docker run -d -p 9000:9000 \
--name portainer \
--restart=always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v portainer_data:/data \
portainer/portainer-ce:2.29.2关于
-v /var/run/docker.sock:/var/run/docker.sock:
/var/run/docker.sock是 Docker 客户端与 Docker 守护进程(dockerd)之间通信的 Unix 套接字文件。将它挂载到 Portainer 容器中,相当于赋予了 Portainer 与宿主机 Docker 引擎同等的控制权,使其能够管理宿主机上的所有 Docker 资源(容器、镜像、网络等)。
安装完成后,在 CNB 上可以通过添加一个 9000 的端口映射来实现外网访问
点击浏览器图标,就可以访问 Portainer 了。
3.2 Portainer 主要功能
-
仪表盘概览
- 查看环境整体状态
- 监控资源使用情况
- 查看事件日志
-
容器管理
- 创建、启动、停止、删除容器
- 查看容器日志和统计信息
- 进入容器终端
- 修改容器配置
-
镜像管理
- 拉取和删除镜像
- 构建新镜像
- 推送镜像到仓库
-
网络管理
- 创建和管理 Docker 网络
- 配置容器网络连接
-
数据卷管理
- 创建和删除数据卷
- 管理数据卷权限
3.3 清理
# 停止并删除 Portainer 容器
docker rm -f portainer
# 删除数据卷(可选,删除后 Portainer 配置将丢失)
docker volume rm portainer_data、、
扩展内容
OverlayFS
实战 1:手动创建 OverlayFS
需要 sudo 权限,在云原生环境中无法演示 OverlayFS 是 Docker 默认使用的存储驱动,下面演示如何手动创建和挂载一个 OverlayFS:
# 1. 创建所需的目录结构
mkdir -p /tmp/overlay-demo/{lower,upper,work,merged}
# 2. 在 lowerdir(只读层)中创建文件
echo "I'm from lower layer" > /tmp/overlay-demo/lower/base.txt
echo "This will be hidden" > /tmp/overlay-demo/lower/override.txt
mkdir -p /tmp/overlay-demo/lower/shared
echo "Shared file" > /tmp/overlay-demo/lower/shared/readme.txt
# 3. 在 upperdir(读写层)中创建文件
echo "I'm from upper layer" > /tmp/overlay-demo/upper/new.txt
echo "This overrides lower" > /tmp/overlay-demo/upper/override.txt
# 4. 挂载 OverlayFS(需要 root 权限)
sudo mount -t overlay overlay \
-o lowerdir=/tmp/overlay-demo/lower,upperdir=/tmp/overlay-demo/upper,workdir=/tmp/overlay-demo/work \
/tmp/overlay-demo/merged
# 5. 查看合并后的文件系统
ls -la /tmp/overlay-demo/merged/
# 输出:
# base.txt ← 来自 lower
# new.txt ← 来自 upper
# override.txt ← 来自 upper(覆盖了 lower)
# shared/ ← 来自 lower
# 6. 验证文件内容
cat /tmp/overlay-demo/merged/base.txt
# I'm from lower layer
cat /tmp/overlay-demo/merged/override.txt
# This overrides lower ← upper 层的内容覆盖了 lower 层
# 7. 在 merged 中写入新文件(会写入 upper 层)
echo "Written in merged" > /tmp/overlay-demo/merged/runtime.txt
# 验证新文件在 upper 层
ls /tmp/overlay-demo/upper/
# new.txt override.txt runtime.txt ← 新文件出现在这里
# 8. 在 merged 中删除 lower 层的文件
rm /tmp/overlay-demo/merged/base.txt
# 查看 upper 层(会创建一个 "whiteout" 文件)
ls -la /tmp/overlay-demo/upper/
# c--------- 1 root root 0, 0 ... base.txt ← whiteout 字符设备文件
# 9. Opaque 目录演示 - 完全隐藏 lower 层的目录
# 首先重新挂载(因为之前的操作可能影响了状态)
sudo umount /tmp/overlay-demo/merged
rm -rf /tmp/overlay-demo/upper/* # 清空 upper 层
sudo mount -t overlay overlay \
-o lowerdir=/tmp/overlay-demo/lower,upperdir=/tmp/overlay-demo/upper,workdir=/tmp/overlay-demo/work \
/tmp/overlay-demo/merged
# 查看 lower 层的 shared 目录内容
ls /tmp/overlay-demo/merged/shared/
# readme.txt ← 来自 lower 层
# 10. 在 merged 视图中删除整个目录并重建
rm -rf /tmp/overlay-demo/merged/shared
mkdir /tmp/overlay-demo/merged/shared
# 11. 查看 upper 层 - 会发现 opaque 标记
ls -la /tmp/overlay-demo/upper/
# drwxr-xr-x 2 root root 4096 ... shared/ ← 新建的目录
# 查看 opaque 扩展属性(这是关键!)
getfattr -n trusted.overlay.opaque /tmp/overlay-demo/upper/shared
# trusted.overlay.opaque="y" ← opaque 标记
# 12. 验证 opaque 效果
# 在新的 shared 目录中创建文件
echo "New content" > /tmp/overlay-demo/merged/shared/new.txt
# 查看 merged 视图 - lower 层的 readme.txt 被完全隐藏了
ls /tmp/overlay-demo/merged/shared/
# new.txt ← 只有新文件,lower 层的 readme.txt 不可见
# 对比:lower 层的文件仍然存在,只是被"遮挡"了
ls /tmp/overlay-demo/lower/shared/
# readme.txt ← 原文件还在,但在 merged 中不可见
# 13. 清理
sudo umount /tmp/overlay-demo/merged
rm -rf /tmp/overlay-demo目录说明:
| 目录 | 作用 | 对应 Docker 概念 |
|---|---|---|
lowerdir | 只读的底层目录 | 镜像层(image layers) |
upperdir | 可读写的上层目录 | 容器层(container layer) |
workdir | OverlayFS 内部使用的工作目录 | Docker 内部管理 |
merged | 合并后的统一视图 | 容器看到的文件系统 |
Whiteout 和 Opaque 机制:
| 机制 | 用途 | 实现方式 | Docker 场景 |
|---|---|---|---|
| Whiteout | 隐藏 lower 层的单个文件 | 在 upper 层创建同名的字符设备文件(0,0) | 容器删除基础镜像中的文件 |
| Opaque | 隐藏 lower 层的整个目录内容 | 在 upper 层目录设置 trusted.overlay.opaque=y 扩展属性 | 容器删除并重建基础镜像中的目录 |
为什么需要这两种机制?
因为 lower 层是只读的,无法真正删除文件。Whiteout 和 Opaque 提供了一种”标记删除”的方式,让 merged 视图看起来文件/目录已被删除,但实际上 lower 层的数据完好无损。
OverlayFS 的工作原理:
┌─────────────────────────────────────┐
│ merged (统一视图) │ ← 用户/容器看到的
├─────────────────────────────────────┤
│ upperdir (读写层) │ ← 所有修改都在这里
├─────────────────────────────────────┤
│ lowerdir (只读层) │ ← 原始镜像内容
└─────────────────────────────────────┘- 读取文件:先查 upper,没有再查 lower
- 写入文件:直接写入 upper
- 修改 lower 的文件:复制到 upper 后修改(Copy-on-Write)
- 删除 lower 的文件:在 upper 创建 whiteout 文件标记删除
- 删除 lower 的目录:在 upper 创建 opaque 目录标记删除
Docker 中 Opaque 的实际应用场景:
# Dockerfile 示例:完全替换配置目录
FROM ubuntu:24.04
# 这个操作会触发 opaque
RUN rm -rf /etc/apt/sources.list.d && \
mkdir /etc/apt/sources.list.d && \
echo "deb http://mirrors.tencent.com/ubuntu noble main" > /etc/apt/sources.list.d/tencent.list
# 结果:原来 sources.list.d 目录下的所有文件都被隐藏
# 只有新创建的 tencent.list 可见要点:Opaque 是 Docker 实现”完全替换目录”的关键机制。当你在 Dockerfile 中删除并重建一个目录时,Docker 会自动设置 opaque 属性,确保底层镜像的该目录内容完全不可见。
实战 2:双容器文件变更 - 在宿主机观察 OverlayFS
这个实验演示两个基于相同镜像的容器,各自的文件修改如何隔离存储在不同的容器层(upperdir)中。
环境要求:本实验需要通过
docker inspect获取容器的 UpperDir/LowerDir 路径。如果宿主机启用了containerd-snapshotter,GraphDriver.Data字段会返回<no value>,无法直接获取路径。可通过以下命令确认:docker info | grep -i snapshotter若输出包含 snapshotter 信息,说明当前环境使用 containerd 管理存储层,本实验中”在宿主机查看容器存储位置”(步骤 5-8)将无法执行,但步骤 1-4 的容器隔离验证仍可正常演示。
# 1. 启动两个容器(基于相同镜像)
docker run -d --name container_a alpine sleep 3600
docker run -d --name container_b alpine sleep 3600
# 2. 在容器 A 中创建文件
docker exec container_a sh -c "echo 'Hello from Container A' > /data_a.txt"
docker exec container_a sh -c "echo 'Modified by A' > /etc/motd"
# /etc/motd 是 Message of the Day 的缩写,是 Linux 系统中用于显示登录欢迎信息的文件
# 它是系统自带文件 - 属于 Alpine 镜像的 lower 层(只读层)
# 修改会触发 Copy-on-Write - 原文件在 lower 层,修改时会复制到 upper 层
# 3. 在容器 B 中创建不同的文件
docker exec container_b sh -c "echo 'Hello from Container B' > /data_b.txt"
docker exec container_b sh -c "echo 'Modified by B' > /etc/motd"
docker exec container_b sh -c "rm /etc/alpine-release" # 删除一个镜像层的文件
# /etc/hostname、/etc/hosts、/etc/resolv.conf 是 Docker 动态挂载的文件
# 这些文件无法删除(会报 Resource busy),应选择真正来自镜像层的文件
# 4. 验证容器内的文件互相隔离
docker exec container_a cat /data_a.txt
# Hello from Container A
docker exec container_a cat /data_b.txt
# cat: can't open '/data_b.txt': No such file or directory ← A 看不到 B 的文件
docker exec container_b cat /data_b.txt
# Hello from Container B
# 5. 在宿主机查看容器的存储位置
# 获取容器 A 的 UpperDir 路径
UPPER_A=$(docker inspect container_a --format '{{.GraphDriver.Data.UpperDir}}')
echo "Container A UpperDir: $UPPER_A"
# 获取容器 B 的 UpperDir 路径
UPPER_B=$(docker inspect container_b --format '{{.GraphDriver.Data.UpperDir}}')
echo "Container B UpperDir: $UPPER_B"
# 6. 在宿主机查看各容器的文件变更
ls -la $UPPER_A
# 输出示例:
# -rw-r--r-- 1 root root 23 Jan 15 14:30 data_a.txt
# drwxr-xr-x 2 root root 26 Jan 15 14:29 etc
cat $UPPER_A/data_a.txt
# Hello from Container A
ls -la $UPPER_B
# 输出示例:
# -rw-r--r-- 1 root root 23 Jan 15 14:30 data_b.txt
# drwxr-xr-x 2 root root 52 Jan 15 14:39 etc
cat $UPPER_B/data_b.txt
# Hello from Container B
# 7. 查看 whiteout 文件(容器 B 删除了 /etc/alpine-release)
ls -la $UPPER_B/etc/
# c--------- 1 root root 0, 0 ... alpine-release ← whiteout 字符设备文件
# 8. 查看共享的镜像层(LowerDir)- 两个容器共享同一个只读层
LOWER_A=$(docker inspect container_a --format '{{.GraphDriver.Data.LowerDir}}')
LOWER_B=$(docker inspect container_b --format '{{.GraphDriver.Data.LowerDir}}')
echo "Container A LowerDir: $LOWER_A"
echo "Container B LowerDir: $LOWER_B"
# 两个容器的 LowerDir 是相同的(共享镜像层)
# init层不同,每个容器都有自己独立的 init 层来存放容器特定的配置文件
# 9. 清理
docker rm -f container_a container_b关键观察点:
| 观察项 | 说明 |
|---|---|
| UpperDir 不同 | 每个容器有独立的读写层,互不影响 |
| LowerDir 相同 | 基于同一镜像的容器共享只读层,节省空间 |
| Whiteout 文件 | 删除 lower 层文件时,upper 层创建特殊标记 |
| 文件隔离 | 容器 A 的修改对容器 B 不可见 |
存储结构示意图:
┌─────────────────────────────────────────────────────────────┐
│ 宿主机文件系统 │
├─────────────────────────────────────────────────────────────┤
│ │
│ Container A Container B │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │UpperDir (独立) │ │UpperDir (独立) │ │
│ │ - data_a.txt │ │ - data_b.txt │ │
│ │ - etc/motd │ │ - etc/motd │ │
│ │ │ │ - etc/alpine-release* │← whiteout│
│ └────────┬────────┘ └────────┬────────┘ │
│ │ │ │
│ └──────────┬──────────────────┘ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ LowerDir (共享) │ ← alpine 镜像层 │
│ │ - /bin, /lib, /etc │ │
│ │ - 只读,不可修改 │ │
│ └─────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘核心理解:这就是 Docker 镜像分层的核心优势 - 多个容器共享相同的镜像层(节省磁盘空间),同时各自拥有独立的可写层(保证隔离性)。
RootFS
实战:查看 RootFS 内容
方法 1:直接查看容器文件系统
# 运行Ubuntu容器
docker run -it --name test ubuntu:20.04 bash
# 在容器内查看RootFS
ls -la /
drwxr-xr-x 1 root root 4096 Jan 1 00:00 bin
drwxr-xr-x 2 root root 4096 Jan 1 00:00 boot ← 空目录(无BootFS)
drwxr-xr-x 5 root root 360 Jan 1 00:00 dev ← 虚拟设备
drwxr-xr-x 1 root root 4096 Jan 1 00:00 etc
drwxr-xr-x 2 root root 4096 Jan 1 00:00 home
drwxr-xr-x 1 root root 4096 Jan 1 00:00 lib
...
# 注意:/boot 目录是空的!
ls /boot/
# 输出为空,因为没有BootFS方法 2:对比宿主机内核
# 宿主机内核版本
uname -r
5.4.241-1-tlinux4-0023.2
# 容器内内核版本(与宿主机相同)
docker run ubuntu:20.04 uname -r
5.4.241-1-tlinux4-0023.2 ← 共享宿主机内核!
# 容器的RootFS版本
docker run ubuntu:20.04 cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.6 LTS (Focal Fossa)" ← 容器的RootFS实战:创建最小化 Docker 镜像
在/7_extended 目录下
# 使用 scratch(空镜像)
FROM scratch
# 只复制单个可执行文件(静态编译)
COPY hello /
# 运行
CMD ["/hello"]编译静态二进制:
# Go 语言示例(天然支持静态编译)
cat > hello.go <<EOF
package main
import "fmt"
func main() {
fmt.Println("Hello from minimal rootfs!")
}
EOF
# 静态编译
CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o hello hello.go
# 构建镜像
docker build -t minimal:v1 .
# 查看大小
docker images minimal
REPOSITORY TAG SIZE
minimal v1 2MB ← 只有可执行文件!这个镜像:
- 没有完整的 RootFS
- 没有/bin, /lib, /etc
- 只有一个可执行文件
- 依然共享宿主机 BootFS
为什么能做到最小?
1. FROM scratch - 从零开始
scratch 是 Docker 的特殊空镜像,它:
- 不包含任何文件:没有操作系统、没有 shell、没有任何库
- 大小为 0 字节:“空白画布”
- 对比普通基础镜像:
ubuntu:24.04 ≈ 78MB alpine:3.19 ≈ 7MB scratch = 0MB ← 完全空白
2. 静态编译 - 无外部依赖
普通编译 vs 静态编译的区别:
| 编译方式 | 依赖 | 能否在 scratch 运行 |
|---|---|---|
| 动态编译 | 需要 libc、libpthread 等共享库 | 否,缺少 /lib |
| 静态编译 | 所有依赖打包进二进制文件 | 独立运行 |
关键编译参数解释:
CGO_ENABLED=0 # 禁用 CGO,避免依赖 C 库
GOOS=linux # 目标操作系统
go build -a # 强制重新编译所有包
-installsuffix cgo # 使用独立的包缓存目录
-o hello # 输出文件名3. 为什么 Go 语言适合做最小镜像?
Go 语言的优势:
- 原生支持静态编译:不像 C/C++ 需要复杂配置
- 无运行时依赖:不需要 JVM、Python 解释器等
- 交叉编译简单:轻松构建不同平台的二进制
对比其他语言的最小镜像大小:
Go (scratch) ≈ 2MB ← 最小
Rust (scratch) ≈ 3MB
C (scratch+musl) ≈ 100KB ← 更小但配置复杂
Java (JRE) ≈ 200MB ← 需要运行时
Python ≈ 50MB ← 需要解释器
Node.js ≈ 100MB ← 需要运行时4. 这种最小镜像的优缺点
优点:
- 极小的镜像体积,传输快
- 攻击面最小,更安全(没有 shell、没有包管理器)
- 启动速度快
缺点:
- 无法进入容器调试(没有 shell)
- 无法使用常用命令(ls、cat、curl 等)
- 必须静态编译,某些场景不适用
实际应用:scratch 镜像常用于生产环境的微服务部署,而开发/调试阶段通常使用 alpine 或 distroless 镜像。
Docker Buildx
Docker Buildx 是 Docker 的官方扩展,用于构建多平台镜像。在实际场景中,同一个应用可能需要运行在不同 CPU 架构的服务器上(如 x86 的 amd64 和 ARM 的 arm64),Docker Buildx 可以一次构建出多个架构的镜像,并通过 Manifest List 统一管理。
本地使用
# 启用 Buildx
docker buildx create --name mybuilder --use
docker buildx inspect --bootstrap
# 构建多平台镜像并推送
docker buildx build --platform linux/amd64,linux/arm64 -t myapp:v1 . --push云原生构建使用
传统 Docker 构建时,BuildKit 可能需要依赖以 root 权限运行的 Docker 守护进程(dockerd),rootless 模式可以让 BuildKit 完全在普通用户权限下工作,不需要 root 权限。
main:
push:
- docker:
image: golang:1.24
services:
- name: docker
options:
rootlessBuildkitd:
enabled: true查看多平台镜像信息
docker manifest inspect docker.cnb.cool/docker-666/campus-academy-template/docker-buildx-multi-platform-example:latestManifest List 是一个包含了多个指向不同架构镜像的 manifest 的文件。当你拉取一个支持多架构的镜像时,Docker 会自动根据你当前的系统架构选择并拉取对应的镜像。
参考资料
Part 5 CNB NPC Playground 扩展(课程延伸)
这一部分更偏向云原生平台实践延伸,说明如何把 Docker 运行环境、流水线和 AI Agent 结合起来。它与前文的关系是:前面学的是容器本身,这里看到的是容器在平台能力中的实际落地。
🎮 NPC Playground
我替你上班,你替我自由 —— 让 NPC 帮你处理繁琐工作,把时间留给真正重要的事
目录
🤖 什么是 NPC?
NPC 是 CNB 开源平台推出的 AI 角色功能,基于 Docker 构建,与代码仓库同源共生 —— 代码在哪里,Agent 就在哪里。你不想做的事情,NPC 帮你做。
| 你不想做的事 | NPC 帮你做 |
|---|---|
| 😫 重复回答相似问题 | 🤖 自动回复 Issue 评论 |
| 😫 审查枯燥的代码 | 🤖 自动 PR 代码审查 |
| 😫 查找文档翻半天 | 🤖 基于知识库即时问答 |
| 😫 手动创建重复 Issue | 🤖 批量创建、分类管理 |
| 😫 记不住项目细节 | 🤖 记住一切,随问随答 |
| 😫 不想写的代码 | 🤖 NPC 帮你写 |
从技术角度看,NPC 是一个以 Issue / PR 事件驱动、以云原生为底座、以 Docker 为运行环境的 [AI] Agent。
📦 如何使用 NPC
CNB 提供了多种不同类型的 NPC:
| 类型 | 说明 | 运行镜像 | 配置成本 |
|---|---|---|---|
| 系统 NPC(CodeBuddy) | 平台内置,全局可用 | default-codebuddy-npc | 零配置 |
| 当前仓库默认 NPC | 在仓库中自定义的 NPC | default-npc-agent | 需配置 .cnb/settings.yml |
| 当前仓库自定义 NPC | 在仓库中自定义的 NPC | cnb.yml 中配置的镜像 | 需配置 .cnb/settings.yml + .cnb.yml |
| 别人的 NPC | 在当前仓库使用其他仓库的 NPC | 由其他仓库的 NPC 定义 | star 仓库即可 |
工作流程
无论哪种 NPC,工作流程都一样:
① 在 Issue / PR 中 @NPC → ② NPC 流水线自动启动 → ③ 结果反馈到评论区“替我上班”模式
开启 替我上班 后,NPC 流水线将获得更高的操作权限。未开启时,NPC 仅能以只读方式响应。
| 未开启 | 已开启 | |
|---|---|---|
| Token 权限 | 只读 | 读写(可推送代码、创建 PR) |
| 适用场景 | 问答、知识查询 | 写代码、自动提 PR、合并分支 |
📖 权限详情参见:CNB Token 权限说明
社区 优秀 NPC 示例
| NPC | 仓库 | 功能 |
|---|---|---|
| OpenClaw | Bring/AGI/OpenClaw | OpenClaw 是一个用于构建、运行和编排 AI Agent 的通用框架,支持对话、工具调用与多模型接入 |
| OpenCode | npc/open-code | 基于 OpenCode CLI 的 CNB 平台 AI Bot |
| 以鹅传鹅-Pro | npc/mtga | 在任意 CNB 仓库的 Issue 或合并请求(PR)评论中 @NPC 即可触发,AI 会自动分析上下文并完成任务。 |
| π | npc/pai | 随机召唤其他 NPC 回答问题 |
| 都闭嘴 | Anyexyz/Tools/kill-cnb-npc | 一键让其他 NPC 闭嘴 |
使用:
@npc/pai(π) 你帮我看看
@npc/open-code(OpenCode) 帮我根据当前的 issue 修改一下代码,修改完后提交个 pr 上来
@Bring/AGI/OpenClaw(OpenClaw) 帮我查看上海明天的天气
@Anyexyz/Tools/kill-cnb-npc(都闭嘴) 让他们都闭嘴💡 浏览更多社区 NPC:https://cnb.cool/explore
🛠️ 自定义 NPC
想要一个完全符合你需求的 NPC?两步搞定。
Step 1:定义 NPC 人设
在仓库创建 .cnb/settings.yml,设定 NPC 的身份和行为:
# .cnb/settings.yml
npc:
roles:
- name: 小助手
avatar:
src: https://cnb.cool/${your-repo}/-/git/raw/main/avatar.png
prompt: |
你是一个友好、专业的代码助手。
擅长回答代码、Git、CI/CD 相关问题。
回答简洁准确,必要时提供代码示例。这里的
https://cnb.cool/${your-repo}/-/git/raw/main/avatar.png是一个示例,在定义 NPC 的时候,需要填入正确的地址。例如:https://cnb.cool/cnb/feedback/-/git/raw/main/assets/feedmiao.jpg。图片地址也支持自己仓库中已存在的图片,例如.cnb/asset/lulu.jpg(仓库内的全局路径)。
Step 2:配置触发场景
创建 .cnb.yml,告诉 NPC 什么时候工作。本质上是运行一条 cnb 的流水线,所以这里兼容 cnb 流水线的所有语法。
如果不配置触发场景,默认走 default-npc-agent 镜像
# .cnb.yml
.npc_task: &npc_task
- stages:
- name: npc respond
image: docker.cnb.cool/npc/mtga:latest # 也可以替换成任意一个npc镜像
小助手:
issue.comment@npc: *npc_task # 有人在 Issue 评论中 @小助手
pull_request.comment@npc: *npc_task # 有人在 PR 评论中 @小助手
附:NPC 相关的环境变量
NPC 流水线运行时,以下 NPC 相关环境变量会自动注入, 完整的环境变量请参考 CNB 环境变量。
NPC 自身信息
| 环境变量 | 说明 |
|---|---|
CNB_NPC_SLUG | NPC 所属仓库路径(原始格式) |
CNB_NPC_SLUG_LOWERCASE | NPC 所属仓库路径(小写格式) |
CNB_NPC_NAME | NPC 角色名 |
CNB_NPC_SHA | NPC 仓库默认分支最新 SHA |
CNB_NPC_PROMPT | NPC 角色 Prompt |
CNB_NPC_AVATAR | NPC 角色头像 |
CNB_NPC_ENABLE_THINKING | NPC 是否开启思考 |
CNB_NPC_ENABLE_WORKMODE | NPC 是否开启工作模式 |
触发者信息
| 环境变量 | 说明 |
|---|---|
CNB_BUILD_USER_NPC_SLUG | 触发构建的 NPC 的 Slug |
CNB_BUILD_USER_NPC_NAME | 触发构建的 NPC 的名称 |
CNB_BUILD_USER | 触发构建的用户名 |
CNB_BUILD_USER_NICKNAME | 构建触发的用户昵称 |
CNB_COMMENT_BODY | 触发构建的评论内容 |
🎬 实战场景
场景 0:极简 Hello World
最简单的 NPC:用户 @NPC,固定回复 hello, world。无需 AI,无需复杂逻辑。
涉及的文件如下:
hello-world/
├── Dockerfile
└── entrypoint.sh
.cnb.yml
.cnb
└── settings.yml💡 NPC 核心工作原理:用户触发 → 流水线运行 → 结果回复到评论区
场景 1:自定义指令机器人
创建一个传统 NPC (without-AI),监听评论区的斜杠指令(如 /close、/reopen、/hidden),自动执行对应操作。
-
- NPC 角色注册
-
- NPC 角色镜像
-
- NPC 流水线配置
使用:
@your-repo/指令助手 /help指令助手会解析斜杠指令,调用 git-cnb CLI 完成操作,并回复执行结果。
场景 2:使用 NPC 来做代码 Review
每次提交 PR 时,NPC 自动审查代码质量。
流程:
每当有新 PR 创建,代码审查官会自动:
- 阅读 PR 的所有变更文件
- 逐文件给出审查意见
- 在 PR 评论中输出审查报告
场景 3:使用 NPC 持续写代码
NPC 不只能写一次代码——它可以根据 Review 意见持续迭代,形成 “提需求 → 写代码 → 审查 → 修改” 的自动化循环。
你提 Issue → 召唤写 NPC 代码提 PR → 召唤 NPC 自动 Review
↓
召唤修改代码推送更新
↓
代码审查官再次 Review
↓
✅ 通过 → 等你合并你只需要提一个 Issue,然后喝杯咖啡,回来看看 PR 是否满意即可。
NPC 增强
1. 添加 Skills
这里以默认 NPC 镜像 (基于 Codebuddy 实现) 为例,我们可以使用 Skills 来增加默认默认 NPC 的能, Codebuddy 的 Skills 分为用户级和项目级,路径分别为 ~/.codebuddy/skills 和 /workspace/.codebuddy/skills, 有两种办法可以通 Skills 来增加技能。
方式 1:在代码仓库中添加 Skills
直接在仓库中创建 .codebuddy/skills/ 目录,NPC 运行时会自动加载:
your-repo/
└── .codebuddy/
└── skills/
└── my-skill
└── SKILL.md方式 2:在 NPC 镜像中内置 Skills
FROM cnbcool/default-npc-agent:latest
# 方法 a: COPY 本地 skills 文件
COPY skills/ /root/.codebuddy/skills/
# 方法 b: git clone 远程仓库
RUN git clone https://cnb.cool/some/skill-repo.git /root/.codebuddy/skills/my-skill
# 方法 c: npx skills add
RUN npx skills add https://cnb.cool/some/skill-repo.git --agent codebuddy -y --copy2. 添加开发环境
默认 NPC 运行在基础 NodeJS 镜像中。如果你的项目需要特定的语言运行时、工具链或依赖,可以自定义 NPC 的开发环境。
Tip: 从你自定义的云原生开发环境的 DockerFile 中抄
自定义 Docker 镜像
需要更多工具?构建你自己的镜像:
FROM cnbcool/default-npc-agent:latest
ARG GO_VERSION=1.24.5
RUN wget -q https://go.dev/dl/go${GO_VERSION}.linux-amd64.tar.gz -O /tmp/go.tar.gz &&\
tar -C /usr/local -xzf /tmp/go.tar.gz && rm /tmp/go.tar.gz
ENV PATH=/usr/local/go/bin:/root/go/bin:${PATH}
RUN go install -v golang.org/x/tools/gopls@latest在 .cnb.yml 中使用:
码农go:
issues@npc:
- stages:
- name: write code
image: your-registry/your-npc-image:latest💬 使用感受
-
泡咖啡前 @NPC 提个需求,咖啡端回来代码已经写好了 —— 手机上就能指挥干活,对移动办公极其友好。
-
每一次对话、每一行代码、每一步思考过程都沉淀在 Issue 和 PR 中,全程可追溯,不怕丢上下文。
喜欢的话,留下你的评论吧~