
Redis 学习笔记
菜鸟教程:https://www.runoob.com/redis
黑马程序员: https://www.bilibili.com/video/BV1cr4y1671t
中文文档 1:https://redis.ac.cn/docs/latest/
中文文档 2:https://redis.com.cn/documentation.html
客户端指南:https://redis.ac.cn/docs/latest/develop/clients/
狂神之路:
基础篇-初识 Redis
01 认识 NoSQL
NoSQL = Not Only SQL 直译是:不仅仅是 SQL,本质是:非关系型数据库。
它是相对于传统关系型数据库(MySQL、Oracle、SQL Server) 提出的一类数据库统称,用来解决关系型数据库在高并发、大数据、分布式场景下的短板。
一、关系型数据库(SQL)是什么样?
关系型数据库特点:
- 数据存在表(Table)里,行+列结构
- 必须先定义表结构(Schema),字段固定
- 用 SQL 语言 统一查询
- 强事务(ACID),保证数据绝对可靠
- 横向扩展难,扛不住超高并发
典型场景:银行转账、订单支付、核心业务数据。
二、NoSQL 是什么?
NoSQL 不遵循传统表结构,不强制固定 Schema,更灵活、更快、更容易分布式扩展。
主要特点:
- 非关系型:没有表、行、列的严格约束
- 灵活结构:字段可随时增删,不用改表结构
- 高性能:大多基于内存或简单存储,读写极快
- 易扩展:天然支持分布式、集群、水平扩容
- 弱事务:大多不支持强事务,追求最终一致性
- 数据模型多样:键值、文档、列族、图等
三、NoSQL 四大主流类型
1. 键值数据库(Key-Value)
- 结构:
key → value - 特点:最简单、速度最快
- 代表:Redis、Memcached
- 用途:缓存、会话、分布式锁、计数器
2. 文档数据库
- 结构:类似 JSON/BSON 文档
- 特点:结构灵活,嵌套复杂数据
- 代表:MongoDB
- 用途:用户信息、文章、评论、大数据存储
3. 列族数据库(列存储)
- 结构:按列存储,适合海量数据
- 代表:HBase、Cassandra
- 用途:大数据、日志、埋点、海量历史数据
4. 图数据库
- 结构:节点+关系(图结构)
- 代表:Neo4j
- 用途:社交关系、推荐系统、知识图谱
四、SQL vs NoSQL 对比
| 对比项 | 关系型数据库(SQL) | NoSQL |
|---|---|---|
| 数据结构 | 表、行、列,固定 Schema | 灵活,无固定结构 |
| 数据关联 | 关联查询(JOIN) | 无关联查询,独立存储 |
| 查询语言 | 标准 SQL | 各自语法,无统一标准 |
| 事务 | 强事务 ACID | 大多弱事务,最终一致性 |
| 性能 | 高并发压力大 | 高并发、高性能 |
| 扩展 | 垂直扩展(升级机器) | 水平扩展(加机器集群) |
| 存储 | 基于磁盘存储 | 基于内存存储 |
| 典型代表 | MySQL、Oracle、PostgreSQL | Redis、MongoDB、HBase |
五、什么时候用 NoSQL?
- 需要超高并发读写(秒杀、首页缓存)
- 数据结构经常变化,不想频繁改表
- 需要快速开发、灵活存储
- 海量数据,需要分布式存储
- 对强事务要求不高,可以接受最终一致
02 认识 Redis
一、Redis 核心定义
Redis 诞生于 2009 年,由意大利开发者 Salvatore Sanfilippo 开发,全称是 Remote Dictionary Server(远程词典服务器),是一款开源的、高性能的键值型 NoSQL 数据库,核心定位是「基于内存存储,同时支持持久化」,也是目前最主流的键值数据库。
二、Redis 核心特征
- 键值型存储:Key 为字符串类型,Value 支持多种复杂数据结构(String、Hash、List、Set、ZSet 等),功能远超 Memcached 等简单键值数据库;
- 单线程模型:Redis 6.0 前完全单线程处理命令,6.0 引入多线程仅处理网络 IO,命令执行仍为单线程;每个命令具备原子性,无需担心并发问题;
- 极致性能:官方测试读写速度可达 10 万+/秒,核心原因:
- 数据基于内存存储,无磁盘 IO 瓶颈;
- 采用 IO 多路复用(epoll)处理网络请求;
- 底层用 C 语言开发,编码高效;
- 数据持久化:支持将内存数据落地到磁盘,避免重启后数据丢失(核心方案:RDB、AOF);
- 高可用架构:支持主从复制、哨兵(Sentinel)、分片集群(Cluster),保证服务不宕机、数据不丢失;
- 多语言支持:提供完善的客户端协议,支持 Go、Java、Python、PHP 等几乎所有主流编程语言;
- 功能扩展:内置发布订阅、Lua 脚本、分布式锁、过期策略、事务等扩展功能,适配更多场景。
三、Redis 核心数据结构
Redis 的核心优势之一是丰富的 Value 数据结构,以下是最常用的 5 种:
| 数据结构 | 核心特点 | 典型用途 |
|---|---|---|
| String(字符串) | 最基础类型,可存储文本、数字,支持自增/自减、批量操作 | 缓存、计数器(点赞数/阅读量)、分布式锁、会话存储 |
| Hash(哈希) | 键值对的集合,类似 JSON 对象,可单独操作字段 | 存储用户信息、商品详情(如 user:1 → {id:1, name:“张三”, age:20}) |
| List(列表) | 有序、可重复的字符串集合,支持头尾增删、范围查询 | 消息队列(LPUSH/RPOP)、最新消息列表、评论列表 |
| Set(集合) | 无序、不可重复的字符串集合,支持交集/并集/差集 | 去重(如用户点赞列表)、共同好友、抽奖活动 |
| ZSet(有序集合) | 基于 Set 扩展,每个元素关联分数(score),按分数排序 | 排行榜(如销量榜、积分榜)、延迟队列 |
四、Redis 典型应用场景
- 缓存:最核心场景,将数据库热点数据缓存到 Redis,减轻数据库压力(如商品详情、首页数据);
- 分布式锁:利用 Redis 的 SETNX 原子操作,解决多服务并发修改数据的问题(如秒杀下单、库存扣减);
- 计数器:基于 String 的 INCR/DECR 原子操作,实现点赞数、阅读量、接口限流计数;
- 排行榜:基于 ZSet 的排序功能,实现实时更新的销量榜、积分榜;
- 消息队列:基于 List 的 LPUSH/RPOP 或发布订阅(Pub/Sub),实现简单的消息通知、异步任务;
- 会话存储:替代传统 Cookie/Session,将用户登录态存储到 Redis,实现分布式系统的会话共享;
- 限流:基于 String 或 ZSet,实现接口防刷、秒杀限流(如令牌桶、漏桶算法)。
03 安装 Redis
WSL(Windows Subsystem for Linux)是 Windows 系统下的 Linux 子系统,可无缝运行 Redis(原生 Linux 版本),相比 Windows 版 Redis 更贴近生产环境,是开发调试的优选方案。
一、前置条件
- 已在 Windows 上安装 WSL(推荐 WSL2),并配置好 Ubuntu/Debian 等 Linux 发行版;
- 确保 WSL 已联网,可通过
ping www.baidu.com验证网络连通性。
二、安装 Redis(以 Ubuntu 为例)
步骤 1:更新系统包列表
打开 WSL 终端(如 Ubuntu),先更新本地包索引,确保安装最新版本:
sudo apt update && sudo apt upgrade -y步骤 2:安装 Redis
执行以下命令安装 Redis 官方稳定版:
sudo apt install redis-server -y安装完成后,Redis 会自动注册为系统服务,并默认启动。
步骤 3:验证安装状态
- 检查 Redis 服务是否运行:
sudo systemctl status redis-server输出中出现 active (running) 表示服务正常启动。
- 测试 Redis 连接:
redis-cli ping返回 PONG 则说明 Redis 安装并运行成功。
三、配置 Redis(可选)
Redis 默认配置文件路径为 /etc/redis/redis.conf,可按需修改核心配置:
步骤 1:编辑配置文件
sudo nano /etc/redis/redis.conf步骤 2:常用配置修改
| 配置项 | 默认值 | 推荐修改(按需) | 说明 |
|---|---|---|---|
bind | 127.0.0.1 ::1 | 注释该行或改为 0.0.0.0 | 允许 Windows 主机/局域网访问(仅开发环境) |
protected-mode | yes | no | 关闭保护模式(配合 bind 修改) |
port | 6379 | 保持默认或自定义 | Redis 监听端口 |
requirepass | 无 | requirepass yourpassword | 开启密码验证(增强安全性) |
appendonly | no | yes | 开启 AOF 持久化(数据更安全) |
步骤 3:重启 Redis 使配置生效
sudo systemctl restart redis-server四、Windows 主机访问 WSL 中的 Redis
默认情况下,WSL 与 Windows 主机共享网络,可直接通过 WSL 的 IP 访问 Redis:
步骤 1:获取 WSL 的 IP 地址
在 WSL 终端执行:
ip addr show eth0 | grep inet | awk '{print $2}' | cut -d/ -f1输出的 IP(如 172.17.0.2)即为 WSL 的内网地址。
步骤 2:Windows 端连接测试
- 打开 Windows CMD/PowerShell,安装 Redis 客户端(可选,如 Redis CLI for Windows);
- 执行连接命令:
redis-cli -h WSL的IP地址 -p 6379
# 若设置了密码,连接后执行 auth yourpassword- 执行
ping,返回PONG则表示 Windows 主机可正常访问 WSL 中的 Redis。
五、Redis 服务管理常用命令
| 功能 | 命令 |
|---|---|
| 启动 Redis | sudo systemctl start redis-server |
| 停止 Redis | sudo systemctl stop redis-server |
| 重启 Redis | sudo systemctl restart redis-server |
| 设置开机自启 | sudo systemctl enable redis-server |
| 关闭开机自启 | sudo systemctl disable redis-server |
| 查看日志 | sudo tail -f /var/log/redis/redis-server.log |
六、注意事项
- 生产环境建议:WSL 仅用于开发/测试,生产环境需部署在纯 Linux 服务器上;
- 端口占用:若 WSL 的 6379 端口被占用,可修改
redis.conf中的port配置,或关闭占用进程; - 权限问题:编辑配置文件需用
sudo,否则会提示权限不足; - WSL 重启后 Redis 状态:若设置了
enable,WSL 重启后 Redis 会自动启动;未设置则需手动start。
总结
- WSL 安装 Redis 的核心步骤:更新系统包 → 安装 redis-server → 验证服务 → 按需修改配置;
- Windows 主机访问 WSL Redis 需获取 WSL 的 IP,并确保 Redis 配置允许外部访问;
- 常用服务管理命令(start/stop/restart/status)可快速控制 Redis 运行状态。
04 Redis 命令行客户端和图形化界面客户端
Redis 的客户端分为命令行客户端(原生、轻量、功能完整)和图形化界面客户端(可视化、易操作、适合新手),以下详细讲解两者的使用方式,覆盖 Windows/WSL/Linux 环境。
一、Redis 命令行客户端(redis-cli)
redis-cli 是 Redis 官方自带的命令行工具,功能完整、无需额外安装,是运维/开发调试的首选。
1. 基础使用(本地连接)
(1)直接启动(默认配置)
打开终端(WSL/Linux)或 CMD(Windows),执行以下命令即可连接本地 Redis(默认地址 127.0.0.1,端口 6379):
# Linux/WSL
redis-cli
# Windows(Redis解压目录下)
redis-cli.exe启动后进入交互模式,提示符为 127.0.0.1:6379>,可直接执行 Redis 命令:
127.0.0.1:6379> SET name "Redis客户端" EX 60 # 设置键值对,过期60秒
OK
127.0.0.1:6379> GET name # 获取值
"Redis客户端"
127.0.0.1:6379> KEYS * # 查看所有key
1) "name"
127.0.0.1:6379> DEL name # 删除key
(integer) 1
127.0.0.1:6379> exit # 退出客户端(2)指定参数连接(远程/自定义配置)
若 Redis 不在本地、端口/密码自定义,可通过参数指定连接信息:
# 通用格式:redis-cli -h 地址 -p 端口 -a 密码
# 示例1:连接WSL中的Redis(假设WSL IP为172.17.0.2)
redis-cli -h 172.17.0.2 -p 6379 -a yourpassword
# 示例2:连接远程服务器Redis
redis-cli -h 192.168.1.100 -p 6380注意:
-a参数会明文显示密码,生产环境建议连接后用AUTH 密码认证:192.168.1.100:6380> AUTH yourpassword OK
2. 常用快捷功能
(1)批量执行命令
通过管道符 | 或文件执行批量命令,适合批量操作:
# 方式1:单行批量执行
echo -e "SET age 20\nGET age\nDEL age" | redis-cli
# 方式2:从文件读取命令(新建cmd.txt,写入Redis命令)
redis-cli < cmd.txt(2)查看命令帮助
对不熟悉的命令,可通过 help 查看用法:
127.0.0.1:6379> HELP SET # 查看SET命令用法
127.0.0.1:6379> HELP @string # 查看字符串类型所有命令(3)性能测试
redis-cli 内置性能测试工具,可测试 Redis 读写性能:
# 测试:100个并发连接,总共执行100000次SET命令
redis-benchmark -t set -c 100 -n 100000
# 测试所有命令性能
redis-benchmark -c 50 -n 500003. 核心命令速查(高频)
| 命令分类 | 常用命令 | 功能 |
|---|---|---|
| 通用命令 | KEYS *、DEL key、EXPIRE key 60、TTL key | 查看所有 key、删除 key、设置过期时间、查看剩余过期时间 |
| 字符串 | SET、GET、INCR、DECR、MSET、MGET | 设置、获取、自增、自减、批量设置/获取 |
| 哈希 | HSET、HGET、HGETALL、HDEL、HINCRBY | 设置哈希字段、获取字段、获取所有字段、删除字段、字段自增 |
| 列表 | LPUSH、RPOP、LRANGE、LLEN | 左加元素、右弹元素、查看范围元素、列表长度 |
| 集合 | SADD、SMEMBERS、SISMEMBER、SINTER | 添加元素、查看所有元素、判断元素是否存在、求交集 |
| 有序集合 | ZADD、ZRANGE、ZREM、ZSCORE | 添加元素(带分数)、按排名查看、删除元素、查看元素分数 |
二、Redis 图形化界面客户端
命令行客户端适合熟练使用,但图形化工具更直观,适合新手或日常管理。
1. Redis for VSCode
- 特点:轻量级 VSCode 插件,无需独立安装,集成在编辑器中,适合开发时快速调试,开源免费、跨平台。
- 使用:VSCode 扩展商店搜索安装→左侧 Redis 图标→Add Connection 填写地址/端口/密码→保存即可管理 Key、执行命令。
- 参考文档:https://redis.ac.cn/docs/latest/develop/tools/redis-for-vscode/
2. Redis Desktop Manager(RDM)
- 特点:经典独立客户端,功能完整(多连接管理、数据导入导出、命令控制台),跨平台;新版本收费,推荐 2022.04 前免费版本。
- 使用:下载安装→新建连接填写参数→测试连通后即可可视化管理 Redis 数据。
- 参考教程:


基础篇-Redis 命令
01 数据结构介绍
Redis 是一个 key-value 的数据库,key 一般是 string 类型,不过 value 的类型多种多样,不同数据类型适配不同的业务场景,是 Redis 核心能力之一。
一、常见数据类型
| 数据类型 | 核心特点 | 典型应用场景 |
|---|---|---|
| String(字符串) | 最基础类型,可存储文本/数字,支持自增/自减、批量操作、过期设置 | 缓存、计数器(点赞数/阅读量)、分布式锁、会话存储 |
| Hash(哈希) | 键值对集合,类似 JSON 对象,可单独操作字段,节省内存 | 存储用户信息、商品详情(如 user:1 → {id:1, name:“张三”}) |
| List(列表) | 有序、可重复的字符串集合,支持头尾增删、范围查询 | 消息队列、最新消息列表、评论列表 |
| Set(集合) | 无序、不可重复的字符串集合,支持交集/并集/差集 | 去重(点赞列表)、共同好友、抽奖活动 |
| ZSet(有序集合) | 基于 Set 扩展,元素关联分数(score),按分数排序 | 排行榜(销量榜/积分榜)、延迟队列 |
二、命令帮助文档查看方式
Redis 为了方便学习,将操作不同类型的命令按分组管理,可通过以下方式查看:
- 官方文档:访问 https://redis.io/docs/latest/commands,按数据类型/功能筛选命令;
- 命令行 help 命令:
- 查看指定命令用法:
HELP SET(示例:查看 SET 命令); - 查看某类数据结构所有命令:
HELP @string(示例:查看字符串类型命令); - 查看所有命令分组:
HELP(输出所有可用的 help 分类)。
- 查看指定命令用法:
02 通用命令
Redis 命令主要分为“通用命令”(对所有数据类型都有效)和“特定类型命令”(只对 String、Hash 等有效)。
对于初学者,掌握通用命令是管理 Redis 的基础。以下是最高频使用的通用命令详解:
1. 键的查询与管理
KEYS pattern
- 作用:查找所有符合给定模式的 key。
- 常用示例:
KEYS *:查看当前数据库所有的 key。KEYS user*:查看所有以user开头的 key(如user:1,user:2)。
- ⚠️ 警告:生产环境(线上环境)严禁使用
KEYS *!- 因为数据量巨大时,这个命令会阻塞 Redis 服务器,导致服务卡顿。生产环境查数据请使用
SCAN。
- 因为数据量巨大时,这个命令会阻塞 Redis 服务器,导致服务卡顿。生产环境查数据请使用
EXISTS key
- 作用:检查给定的 key 是否存在。
- 返回值:
1:存在。0:不存在。
- 示例:
EXISTS name # (integer) 1
TYPE key
- 作用:查看 key 存储的数据类型。
- 返回值:
string(字符串),hash(哈希),list(列表),set(集合),zset(有序集合),none(不存在)。 - 示例:
TYPE age # "string"
2. 删除与过期时间
DEL key [key ...]
- 作用:删除一个或多个 key。
- 返回值:被删除 key 的数量。
- 示例:
DEL age # (integer) 1 DEL name age address # 删除多个
EXPIRE key seconds
- 作用:为 key 设置生存时间(TTL),过期后自动删除。
- 场景:验证码缓存、Session 管理、限时优惠活动。
- 示例:
EXPIRE code 60 # 设置 code 这个 key 60秒后过期
TTL key
- 作用:查看 key 的剩余生存时间。
- 返回值:
- 正数:剩余秒数。
-1:永久存在(没有设置过期时间)。-2:key 不存在(已过期或被删除)。
- 示例:
TTL code # (integer) 55 (还剩55秒)
3. 修改键名与移动
RENAME key newkey
- 作用:将 key 重命名。
- 注意:如果 newkey 已经存在,会被覆盖!
- 示例:
RENAME username user:1001:name
MOVE key db_index
- 作用:将 key 从当前数据库移动到指定数据库(如 db0 移到 db1)。
- 示例:
MOVE age 1 # 将 age 移动到 1 号库
4. 数据库操作(危险!)
SELECT index
- 作用:切换数据库。默认有 16 个库(0-15)。
- 示例:
SELECT 1 # 切换到 1 号库 SELECT 0 # 切回默认库
FLUSHDB
- 作用:清空当前数据库的所有 key。
- ⚠️ 警告:不可恢复,慎用!
FLUSHALL
- 作用:清空所有数据库(0-15)的所有 key。
- ⚠️ 警告:相当于“删库跑路”,绝对不要在执行环境执行!
5. 高级操作
SCAN cursor [MATCH pattern] [COUNT count]
- 作用:迭代数据库中的键。用于替代
KEYS *。 - 特点:不阻塞服务器,分批返回结果。
- 原理:基于游标。第一次传
0,返回一个新的游标,直到返回游标为0表示遍历结束。 - 示例:
SCAN 0 MATCH user* COUNT 10 # 返回:下一个游标值 和 本次查到的 key 列表
OBJECT ENCODING key
- 作用:查看 key 底层存储的数据结构(如
embstr,int,raw等)。用于深度调优。
总结速记表
| 命令 | 作用 | 风险等级 |
|---|---|---|
KEYS * | 查所有 Key | 🔥 高危 (生产禁用) |
DEL | 删除 Key | ⚠️ 中危 |
EXISTS | 判断是否存在 | ✅ 安全 |
TYPE | 查看类型 | ✅ 安全 |
EXPIRE | 设置过期时间 | ✅ 常用 |
TTL | 查看过期时间 | ✅ 常用 |
SELECT | 切换数据库 | ✅ 常用 |
FLUSHDB | 清空当前库 | 🚫 极危 |
FLUSHALL | 清空所有库 | 🚫 极危 |
掌握这些命令,你就可以在 CLI 或图形化工具中自如地管理 Redis 的基础数据了。
03 String 类型
一、基本介绍
String 类型(字符串类型)是 Redis 中最简单、最常用的存储类型,也是所有数据类型的基础。
其 value 本质是字符串,根据字符串格式不同,可细分为 3 类:
string:普通字符串(如”Redis”、“用户 1001”);int:整数型字符串(如”100”、“999”,支持数值运算);float:浮点型字符串(如”3.14”、“9.9”,支持浮点运算)。
核心特性:
- 底层以字节数组形式存储,不同格式仅编码方式不同;
- 单个 String 类型 value 的最大存储空间不超过 512MB;
- 支持原子性操作,适合做计数器、分布式锁等场景。
二、常见命令
1. SET
- 语法:
SET key value [EX seconds | PX milliseconds] [NX | XX] - 作用:设置指定 key 的值。
- 示例:
SET name "muke" SET code "123456" EX 60 # 设置值并设置60秒过期时间 - 可选参数:
EX seconds:设置过期时间(秒)。PX milliseconds:设置过期时间(毫秒)。NX:键不存在时才设置。XX:键存在时才设置。
2. GET
- 语法:
GET key - 作用:获取指定 key 的值。如果 key 不存在,返回
nil。 - 示例:
GET name # "muke"
3. MSET
- 语法:
MSET key value [key value ...] - 作用:同时设置一个或多个 key-value 对。
- 优点:原子性操作,同时成功或同时失败,且减少网络传输次数,效率高于多次执行
SET。 - 示例:
MSET k1 "v1" k2 "v2" k3 "v3"
4. MGET
- 语法:
MGET key [key ...] - 作用:获取所有(一个或多个)给定 key 的值。
- 示例:
MGET k1 k2 k3 # 1) "v1" # 2) "v2" # 3) "v3"
5. INCR
- 语法:
INCR key - 作用:将 key 中储存的数字值增一。
- 注意:
- 如果 key 不存在,会先初始化为
0再增一。 - 如果 value 不是整数类型(如字符串 “hello”),会报错。
- 如果 key 不存在,会先初始化为
- 场景:文章阅读量计数、点赞数、分布式 ID 生成。
- 示例:
INCR read_count # (integer) 1
6. INCRBY
- 语法:
INCRBY key increment - 作用:将 key 所储存的值加上给定的增量。
- 示例:
INCRBY score 10 # (integer) 10
7. INCRBYFLOAT
- 语法:
INCRBYFLOAT key increment - 作用:将 key 所储存的值加上给定的浮点增量。
- 示例:
SET price 10.5 INCRBYFLOAT price 0.5 # "11"
8. SETNX
- 语法:
SETNX key value - 作用:仅在 key 不存在时设置值。
- 返回值:设置成功返回
1,失败返回0。 - 场景:分布式锁的简单实现。
- 示例:
SETNX lock "uuid_123" # (integer) 1 (成功) SETNX lock "uuid_456" # (integer) 0 (失败,lock已存在)
9. SETEX
- 语法:
SETEX key seconds value - 作用:设置值并设置过期时间(秒)。
- 等价于:
SET key value EX seconds。 - 场景:验证码存储(必须有过期时间)。
- 示例:
SETEX verify_code 60 "888888" # 存入验证码,60秒后过期
三、常用场景与注意事项
1. 典型场景
- 缓存:存储商品详情、用户信息等热点数据;
- 计数器:点赞数、阅读量、接口调用次数(基于
INCR/INCRBY); - 分布式锁:基于
SETNX/SET key value NX EX实现; - 临时数据:验证码、Session(基于
SETEX设置过期时间)。
2. 注意事项
- 非数值型字符串执行
INCR/INCRBY会报错(如SET name "张三"后执行INCR name); SETNX+EXPIRE非原子操作,生产环境优先用SET key value NX EX seconds(原子性设置+过期);- 单个 String 值建议控制在 100KB 以内,过大的 value 会影响 Redis 读写性能。
四、命令速记表
| 命令 | 核心作用 | 关键特性 |
|---|---|---|
SET | 设置单个 key-value | 支持过期、NX/XX 参数 |
GET | 获取单个 key 的 value | 不存在返回 nil |
MSET/MGET | 批量设置/获取 key-value | 原子性,减少网络交互 |
INCR/INCRBY | 整数自增/指定增量自增 | 原子操作,适合计数器 |
INCRBYFLOAT | 浮点数值自增 | 支持小数运算 |
SETNX | 不存在时设置 | 分布式锁核心 |
SETEX | 设置 value 并指定过期时间 | 简化 SET+EXPIRE 操作 |
04 Key 的层级结构
一、思考引入
核心问题:Redis 没有 MySQL 中「表(Table)」的概念,若直接用简单字符串(如1)作为 Key,不同业务的 Key 极易冲突(例如用户 ID=1 和商品 ID=1 会覆盖)。
典型场景:存储用户、商品信息时,用户 ID 和商品 ID 可能重复,直接用 ID 作为 Key 会导致数据覆盖,需通过规范的 Key 结构区分业务。
二、Key 的结构规范
Redis 的 Key 支持多单词组成层级结构,单词之间用冒号 : 分隔,推荐通用格式:
项目名:业务模块:数据类型:唯一标识核心说明:
- 格式非固定,可根据业务灵活调整层级(如新增「环境」层级:
heima:dev:user:1); - 层级命名在图形化客户端中会自动生成文件夹式目录树,大幅提升可读性;
- 层级划分需遵循「语义化、唯一化」原则,避免模糊命名(如避免
heima:data:1,无法区分是用户还是商品)。
三、Value 的存储建议
- 若 Value 是结构化对象(如 User、Product),优先序列化为JSON 字符串存储(跨语言兼容、易解析);
- 若需频繁修改对象单个字段,可改用 Hash 类型存储(详见 05 Hash 类型);
- 避免存储超大 JSON(建议单 Value≤100KB),过大的 Value 会降低 Redis 读写性能。
四、实战示例
以heima项目为例,存储用户和商品信息的规范命名:
1. 存储用户对象
- Key:
heima:user:1(项目名:业务模块:唯一标识) - Value:
{"id":1, "name":"Jack", "age":21}(JSON 字符串) - 命令:
SET heima:user:1 '{"id":1, "name":"Jack", "age":21}' EX 86400 # 附加过期时间(可选)
2. 存储商品对象
- Key:
heima:product:1(项目名:业务模块:唯一标识) - Value:
{"id":1, "name":"iPhone", "price":6999}(JSON 字符串) - 命令:
SET heima:product:1 '{"id":1, "name":"iPhone", "price":6999}'
五、图形化界面展示效果
层级结构命名后,Redis 图形化客户端(如 ARDM、Redis for VSCode)会自动生成目录树,直观易管理:
📂 heima
├── 📂 user # 业务模块:用户
│ └── 🔑 1 # 唯一标识:用户ID -> {"id":1, "name":"Jack", "age":21}
└── 📂 product # 业务模块:商品
└── 🔑 1 # 唯一标识:商品ID -> {"id":1, "name":"iPhone", "price":6999}六、扩展规范(生产环境建议)
| 层级扩展场景 | 示例 Key | 说明 |
|---|---|---|
| 多环境区分 | heima:dev:user:1 | dev(开发)/test(测试)/prod(生产) |
| 多字段分类 | heima:user:1:info | 区分用户基础信息/行为数据 |
| 分布式系统 | heima:user:1:node1 | 区分集群节点数据 |
05 Hash 类型
一、基本介绍
Hash 类型(散列)是 Redis 中的键值对集合,其 Value 是一个无序的「字段-值(field-value)」字典,类似 Java 中的HashMap、Python 中的dict。
核心优势(对比 String 存储 JSON)
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| String(JSON) | 存储简单、跨语言兼容 | 修改单个字段需全量读写,效率低 |
| Hash | 可单独操作单个字段 | 不支持嵌套结构,仅存储字符串 |
适用场景:用户信息、商品详情等需频繁修改单个字段的结构化数据存储。
二、直观示例
存储用户信息时,Hash 类型可将每个字段独立存储,无需序列化整个对象:
# String存储(JSON):修改age需重新序列化整个对象
heima:user:1 -> {"id":1, "name":"Jack", "age":21}
# Hash存储:可单独修改age字段
heima:user:1 -> {id:1, name:"Jack", age:21}三、常见命令
1. 单字段操作
HSET key field value
- 作用:为 Hash 类型的 key 设置指定字段(field)和值(value);
- 返回值:
1(字段不存在,设置成功)、0(字段已存在,覆盖成功); - 示例:
HSET heima:user:1 name "Jack" age 21 # (integer) 2 (2个新字段设置成功)
HGET key field
- 作用:获取 Hash 类型 key 中指定字段的值;
- 返回值:字段存在返回对应值,不存在返回
(nil); - 示例:
HGET heima:user:1 age # "21"
2. 多字段操作
HMSET key field value [field value ...]
- 作用:批量为 Hash 类型 key 设置多个字段和值;
- 示例:
HMSET heima:user:2 name "Rose" age 22 email "rose@test.com" # OK
HMGET key field [field ...]
- 作用:批量获取 Hash 类型 key 中多个字段的值;
- 返回值:按字段顺序返回值,不存在的字段返回
(nil); - 示例:
HMGET heima:user:2 name age phone # 1) "Rose" # 2) "22" # 3) (nil)
3. 全量操作
HGETALL key
- 作用:获取 Hash 类型 key 中所有字段和值;
- 返回值:字段和值交替的列表;
- 示例:
HGETALL heima:user:1 # 1) "name" # 2) "Jack" # 3) "age" # 4) "21"
HKEYS key
- 作用:获取 Hash 类型 key 中所有字段名;
- 示例:
HKEYS heima:user:1 # 1) "name" # 2) "age"
HVALS key
- 作用:获取 Hash 类型 key 中所有字段值;
- 示例:
HVALS heima:user:1 # 1) "Jack" # 2) "21"
4. 数值运算与条件设置
HINCRBY key field increment
- 作用:将 Hash 类型 key 中指定字段的值(整数型)自增指定增量;
- 场景:用户积分、商品库存修改;
- 示例:
HINCRBY heima:user:1 age 1 # age从21自增1 # (integer) 22
HSETNX key field value
- 作用:仅当字段不存在时,为 Hash 类型 key 设置字段和值;
- 返回值:
1(设置成功)、0(字段已存在,设置失败); - 示例:
HSETNX heima:user:1 name "Tom" # name已存在,失败 # (integer) 0 HSETNX heima:user:1 gender "male" # gender不存在,成功 # (integer) 1
四、实战案例
需求:存储并修改用户信息
# 1. 存储用户1的基础信息(Hash类型)
HMSET heima:user:1 id 1 name "Jack" age 21 score 100
# 2. 获取用户1的姓名和年龄
HMGET heima:user:1 name age
# 1) "Jack"
# 2) "21"
# 3. 给用户1的积分增加20
HINCRBY heima:user:1 score 20
# (integer) 120
# 4. 仅当邮箱字段不存在时设置
HSETNX heima:user:1 email "jack@test.com"
# (integer) 1五、注意事项
- Hash 类型的 field 和 value 均为字符串类型,不支持嵌套 JSON 或其他复杂结构;
- 单个 Hash 类型 key 最多支持 2^32-1 个字段,实际使用中建议控制在 1000 个以内;
- 若需存储嵌套对象(如用户的收货地址列表),优先用 String 存储 JSON,而非 Hash 嵌套。
六、命令速记表
| 命令 | 核心作用 | 关键特性 |
|---|---|---|
HSET | 设置单个字段值 | 覆盖已存在字段 |
HGET | 获取单个字段值 | 不存在返回 nil |
HMSET/HMGET | 批量设置/获取字段值 | 原子操作,减少网络交互 |
HGETALL | 获取所有字段和值 | 数据量大时阻塞 Redis,慎用 |
HKEYS/HVALS | 获取所有字段名/字段值 | 快速筛选 Hash 结构数据 |
HINCRBY | 字段值整数自增 | 原子操作,适合计数器 |
HSETNX | 字段不存在时设置 | 防止字段覆盖 |
06 List 类型
一、基本介绍
Redis 中的 List 类型与 Java 中的LinkedList底层逻辑一致,本质是双向链表结构,元素有序且可重复。
核心特征
- 双向检索:支持从表头(左侧)、表尾(右侧)双向操作元素,时间复杂度 O(1);
- 元素可重复:同一个元素可多次加入列表;
- 内存高效:链表结构无需连续内存,新增/删除元素性能高;
- 长度限制:单个 List 最多支持 2^32-1 个元素(约 42 亿)。
典型应用场景
- 消息队列:基于 LPUSH+RPOP 实现简单队列,BLPOP/BRPOP 实现阻塞队列;
- 最新消息列表:如朋友圈、评论区的最新动态(LPUSH+LRANGE);
- 栈/队列模拟:利用双向操作特性实现栈、普通队列、阻塞队列;
- 限流削峰:临时存储请求,缓慢消费避免后端过载。
二、常见命令
1. 基础增删操作
LPUSH key element [element ...]
- 作用:将一个/多个元素从列表左侧(表头) 插入;
- 返回值:插入后列表的长度;
- 示例:
LPUSH nums 1 2 3 # 列表变为 [3,2,1] # (integer) 3
LPOP key
- 作用:从列表左侧(表头) 弹出一个元素;
- 返回值:弹出的元素,列表为空返回
(nil); - 示例:
LPOP nums # 弹出3,列表变为 [2,1] # "3"
RPUSH key element [element ...]
- 作用:将一个/多个元素从列表右侧(表尾) 插入;
- 返回值:插入后列表的长度;
- 示例:
RPUSH nums 4 5 # 列表变为 [2,1,4,5] # (integer) 4
RPOP key
- 作用:从列表右侧(表尾) 弹出一个元素;
- 返回值:弹出的元素,列表为空返回
(nil); - 示例:
RPOP nums # 弹出5,列表变为 [2,1,4] # "5"
2. 范围查询
LRANGE key start end
- 作用:获取列表中
[start, end]范围内的元素(闭区间); - 参数说明:
start/end:索引从 0 开始,支持负数(-1 表示最后一个元素,-2 表示倒数第二个);
- 示例:
LRANGE nums 0 -1 # 获取所有元素,返回 ["2","1","4"] LRANGE nums 0 1 # 获取前2个元素,返回 ["2","1"]
3. 阻塞式弹出(核心)
BLPOP key [key ...] timeout / BRPOP key [key ...] timeout
- 作用:与 LPOP/RPOP 逻辑一致,但列表为空时阻塞等待(而非直接返回 nil);
- 参数说明:
timeout:阻塞超时时间(秒),0 表示永久阻塞;- 支持同时监听多个列表,有元素时优先弹出第一个非空列表的元素;
- 场景:阻塞队列(如消息消费),避免轮询消耗资源;
- 示例:
BLPOP empty_list 5 # 列表为空,阻塞5秒后返回nil # (nil) # (5.00s) BRPOP nums 0 # 永久阻塞,直到nums有元素弹出 # 若此时另一个客户端LPUSH nums 6,立即返回 ["nums","6"]
三、核心思考:基于 List 模拟栈/队列/阻塞队列
1. 模拟栈(先进后出,FILO)
栈的核心是「先进后出」,利用 List 的同一侧增删实现:
- 入栈:
LPUSH key element(左侧插入); - 出栈:
LPOP key(左侧弹出); - 示例:
LPUSH stack 1 2 3 # 入栈:[3,2,1] LPOP stack # 出栈:3 → 栈变为 [2,1] LPOP stack # 出栈:2 → 栈变为 [1]
2. 模拟普通队列(先进先出,FIFO)
队列的核心是「先进先出」,利用 List 的两侧增删实现:
- 入队:
LPUSH key element(左侧插入); - 出队:
RPOP key(右侧弹出); - 示例:
LPUSH queue 1 2 3 # 入队:[3,2,1] RPOP queue # 出队:1 → 队列变为 [3,2] RPOP queue # 出队:2 → 队列变为 [3]
3. 模拟阻塞队列(先进先出+空队列阻塞)
基于普通队列逻辑,将出队命令替换为阻塞式弹出:
- 入队:
LPUSH key element(左侧插入); - 出队:
BRPOP key 0(右侧阻塞弹出,0 表示永久等待); - 核心优势:消费者无需轮询,队列空时阻塞,有消息时立即消费,减少资源消耗;
- 示例:
# 生产者 LPUSH block_queue "order:1001" # 入队 # 消费者(永久阻塞等待) BRPOP block_queue 0 # 队列有元素时立即弹出"order:1001",无元素则阻塞
四、注意事项
LRANGE命令在获取超大范围(如 0 -1)时,若列表元素过多会阻塞 Redis,生产环境需控制返回长度;- 阻塞命令(BLPOP/BRPOP)会占用客户端连接,需合理设置超时时间,避免连接泄漏;
- List 作为消息队列仅适合简单场景,不支持消息确认、重试,复杂场景建议用 RabbitMQ/Kafka。
五、命令速记表
| 命令 | 核心作用 | 适用场景 |
|---|---|---|
LPUSH | 左侧插入元素 | 栈/队列入队 |
LPOP | 左侧弹出元素 | 栈出栈 |
RPUSH | 右侧插入元素 | 反向队列入队 |
RPOP | 右侧弹出元素 | 普通队列出队 |
LRANGE | 范围查询元素 | 查看列表内容 |
BLPOP/BRPOP | 阻塞式弹出元素 | 阻塞队列消费 |
总结
- Redis List 是双向链表结构,支持双向增删、范围查询,核心优势是增删性能高;
- 模拟栈用「LPUSH+LPOP」,模拟普通队列用「LPUSH+RPOP」,模拟阻塞队列用「LPUSH+BRPOP」;
- 阻塞命令(BLPOP/BRPOP)是实现阻塞队列的核心,可避免轮询消耗资源。
07 Set 类型
一、基本介绍
Redis 的 Set 类型与 Java 中的HashSet底层逻辑一致,本质是基于哈希表实现的无序集合,可看作是 value 为空的HashMap(仅存储 key,利用哈希表保证唯一性)。
核心特征
- 元素不可重复:向集合中添加已存在的元素会被自动忽略,天然支持去重;
- 无序性:元素存储无固定顺序,每次查询返回顺序可能不同;
- 查询高效:判断元素是否存在、获取元素的时间复杂度为 O(1);
- 集合运算:原生支持交集、并集、差集等集合操作,适合多维度数据筛选;
- 长度限制:单个 Set 最多支持 2^32-1 个元素(约 42 亿)。
典型应用场景
- 数据去重:如用户点赞列表、访问记录、抽奖名单(避免重复参与);
- 关系筛选:如共同好友、共同关注、商品标签交集;
- 随机抽取:如抽奖、随机推荐(SPOP/SRANDMEMBER);
- 权限控制:如用户角色集合、接口访问权限集合。
二、常见命令
1. 基础增删与查询
SADD key member [member ...]
- 作用:向集合中添加一个/多个元素;
- 返回值:新增元素的数量(已存在的元素不计入);
- 示例:
SADD user:1:likes post1 post2 post3 # 添加3个点赞帖子 # (integer) 3 SADD user:1:likes post1 # 重复添加,返回0 # (integer) 0
SREM key member [member ...]
- 作用:从集合中删除一个/多个元素;
- 返回值:成功删除的元素数量;
- 示例:
SREM user:1:likes post2 # 删除post2 # (integer) 1
SCARD key
- 作用:获取集合的元素数量(长度);
- 返回值:集合元素个数,集合不存在返回 0;
- 示例:
SCARD user:1:likes # 剩余post1、post3,返回2 # (integer) 2
SISMEMBER key member
- 作用:判断元素是否存在于集合中;
- 返回值:
1(存在)、0(不存在); - 场景:快速校验用户是否点赞、是否参与活动;
- 示例:
SISMEMBER user:1:likes post1 # 存在,返回1 # (integer) 1 SISMEMBER user:1:likes post4 # 不存在,返回0 # (integer) 0
SMEMBERS key
- 作用:获取集合中所有元素;
- ⚠️ 警告:集合元素过多时(如 10 万+),会阻塞 Redis,生产环境慎用;
- 示例:
SMEMBERS user:1:likes # 1) "post1" # 2) "post3"
2. 集合运算(核心)
SINTER key1 [key2 ...]
- 作用:求多个集合的交集(同时存在于所有集合的元素);
- 场景:共同好友、共同点赞、标签交集;
- 示例:
# 先初始化两个用户的点赞集合 SADD user:1:likes post1 post2 post3 SADD user:2:likes post2 post3 post4 # 求共同点赞的帖子(交集) SINTER user:1:likes user:2:likes # 1) "post2" # 2) "post3"
SDIFF key1 [key2 ...]
- 作用:求多个集合的差集(存在于 key1 但不存在于其他集合的元素);
- 场景:用户 A 点赞但用户 B 未点赞的内容、独有标签;
- 示例:
SDIFF user:1:likes user:2:likes # user1有但user2没有的帖子 # 1) "post1"
SUNION key1 [key2 ...]
- 作用:求多个集合的并集(所有集合的元素,去重);
- 场景:合并多个用户的点赞列表、汇总标签;
- 示例:
SUNION user:1:likes user:2:likes # 合并两个用户的点赞列表 # 1) "post1" # 2) "post2" # 3) "post3" # 4) "post4"
三、扩展常用命令(补充)
| 命令 | 核心作用 | 示例 |
|---|---|---|
SPOP key [count] | 随机弹出 count 个元素 | SPOP user:1:likes 1(随机抽 1 个) |
SRANDMEMBER key [count] | 随机获取 count 个元素(不弹出) | SRANDMEMBER user:1:likes 2 |
SINTERSTORE dest key1 key2 | 将交集结果存入 dest 集合 | SINTERSTORE common_likes user1 user2 |
四、实战案例:共同好友查询
# 1. 初始化两个用户的好友集合
SADD user:1001:friends 1002 1003 1004
SADD user:1002:friends 1001 1003 1005
# 2. 查询两人的共同好友
SINTER user:1001:friends user:1002:friends
# 1) "1003"
# 3. 查询user1001有但user1002没有的好友
SDIFF user:1001:friends user:1002:friends
# 1) "1004"
# 4. 统计user1001的好友数量
SCARD user:1001:friends
# (integer) 3五、注意事项
SMEMBERS命令在元素过多时会阻塞 Redis,生产环境优先用SSCAN(分批遍历)替代;- 集合运算(SINTER/SDIFF/SUNION)的性能与参与运算的集合大小相关,超大集合运算需谨慎;
- 如需有序的集合,可使用 ZSet(有序集合)替代 Set。
六、命令速记表
| 命令 | 核心作用 | 关键特性 |
|---|---|---|
SADD | 添加元素 | 自动去重,返回新增数量 |
SREM | 删除元素 | 返回删除数量 |
SCARD | 获取集合长度 | 快速统计,O(1)复杂度 |
SISMEMBER | 判断元素是否存在 | 核心去重校验,O(1)复杂度 |
SMEMBERS | 获取所有元素 | 大集合慎用,易阻塞 |
SINTER | 求交集 | 多集合共同元素筛选 |
SDIFF | 求差集 | 独有元素筛选 |
SUNION | 求并集 | 多集合元素合并去重 |
总结
- Redis Set 是基于哈希表的无序集合,核心特性是元素不可重复、查询高效、支持集合运算;
- 基础操作(SADD/SREM/SCARD/SISMEMBER)是日常使用核心,集合运算(SINTER/SDIFF/SUNION)是 Set 的特色能力;
- 适合数据去重、关系筛选(共同好友)、随机抽取等场景,大集合操作需避免阻塞 Redis。
08 SortedSet 类型(ZSet)
一、基本介绍
Redis 的 SortedSet(简称 ZSet)是可排序的无重复集合,与 Java 中的TreeSet功能相似,但底层实现完全不同(ZSet 基于「跳表+哈希表」实现,兼顾排序和查询性能)。
ZSet 中每个元素关联一个score(浮点型数值),核心基于score对元素排序,同时通过哈希表保证元素唯一性。
核心特性
- 有序性:基于
score排序,支持升序/降序查询,排序性能高; - 元素唯一:集合内元素不可重复,但
score可重复; - 查询高效:获取元素排名、范围查询的时间复杂度为 O(logN);
- 双结构加持:跳表保证排序,哈希表保证元素唯一性和快速查询;
- 长度限制:单个 ZSet 最多支持 2^32-1 个元素(约 42 亿)。
典型应用场景
- 排行榜:商品销量榜、用户积分榜、游戏战力榜;
- 延迟队列:基于
score存储时间戳,实现定时任务; - 范围筛选:按分数/排名筛选数据(如 TopN、分数区间查询);
- 权重排序:如搜索结果按相关性排序、评论按热度排序。
二、常见命令
1. 基础增删与查询
ZADD key score member [score member ...]
- 作用:向 ZSet 中添加一个/多个元素(指定 score);
- 返回值:新增元素的数量(已存在的元素仅更新 score,不计入返回值);
- 示例:
ZADD score:math 95 zhangsan 88 lisi 92 wangwu # 添加3个学生的数学成绩 # (integer) 3 ZADD score:math 90 lisi # 更新lisi的分数,返回0 # (integer) 0
ZREM key member [member ...]
- 作用:从 ZSet 中删除一个/多个元素;
- 返回值:成功删除的元素数量;
- 示例:
ZREM score:math lisi # 删除lisi的成绩 # (integer) 1
ZSCORE key member
- 作用:获取指定元素的 score 值;
- 返回值:score 的字符串形式,元素不存在返回
(nil); - 示例:
ZSCORE score:math zhangsan # "95"
ZRANK key member / ZREVRANK key member
- 作用:
ZRANK:获取元素的升序排名(从 0 开始);ZREVRANK:获取元素的降序排名(从 0 开始);
- 返回值:排名数值,元素不存在返回
(nil); - 示例:
ZRANK score:math zhangsan # 升序排名(92<95),返回1 # (integer) 1 ZREVRANK score:math zhangsan # 降序排名,返回0(第一名) # (integer) 0
ZCARD key
- 作用:获取 ZSet 的元素数量(长度);
- 返回值:元素个数,集合不存在返回 0;
- 示例:
ZCARD score:math # 剩余zhangsan、wangwu,返回2 # (integer) 2
ZCOUNT key min max
- 作用:统计
score在[min, max]范围内的元素数量; - 参数说明:
min/max支持(表示开区间(如(90表示>90); - 示例:
ZCOUNT score:math 90 100 # 分数≥90且≤100的元素数量 # (integer) 2 ZCOUNT score:math (90 95 # 分数>90且≤95的元素数量 # (integer) 2
ZINCRBY key increment member
- 作用:将指定元素的 score 自增
increment(可负数,即自减); - 场景:积分增减、销量更新;
- 示例:
ZINCRBY score:math 2 wangwu # 给wangwu加2分,score从92→94 # "94"
2. 范围查询(核心)
ZRANGE key start end [WITHSCORES] / ZREVRANGE key start end [WITHSCORES]
- 作用:
ZRANGE:按升序获取排名[start, end]的元素(0 开始,-1 表示最后一名);ZREVRANGE:按降序获取排名[start, end]的元素;WITHSCORES:可选参数,返回元素时附带 score;
- 场景:TopN 排行榜(如前 10 名);
- 示例:
# 升序获取所有元素(附带分数) ZRANGE score:math 0 -1 WITHSCORES # 1) "wangwu" # 2) "94" # 3) "zhangsan" # 4) "95" # 降序获取前1名(第一名) ZREVRANGE score:math 0 0 WITHSCORES # 1) "zhangsan" # 2) "95"
ZRANGEBYSCORE key min max [WITHSCORES] / ZREVRANGEBYSCORE key max min [WITHSCORES]
- 作用:
ZRANGEBYSCORE:按升序获取score在[min, max]的元素;ZREVRANGEBYSCORE:按降序获取score在[max, min]的元素;
- 场景:分数区间筛选(如 90 分以上的学生);
- 示例:
# 获取分数≥90且≤95的元素(附带分数) ZRANGEBYSCORE score:math 90 95 WITHSCORES # 1) "wangwu" # 2) "94" # 3) "zhangsan" # 4) "95"
3. 集合运算
ZDIFF numkeys key1 [key2 ...] / ZINTER numkeys key1 [key2 ...] / ZUNION numkeys key1 [key2 ...]
- 作用:
ZDIFF:求多个 ZSet 的差集(存在于第一个集合,不存在于其他集合);ZINTER:求多个 ZSet 的交集(同时存在于所有集合);ZUNION:求多个 ZSet 的并集(所有集合的元素,去重);
- 参数说明:
numkeys表示参与运算的集合数量; - 示例:
# 初始化两个学科的分数集合 ZADD score:math 95 zhangsan 92 wangwu ZADD score:english 90 zhangsan 88 wangwu # 求两科都有成绩的学生(交集) ZINTER 2 score:math score:english # 1) "wangwu" # 2) "zhangsan"
三、核心规则
所有排名/范围查询命令默认升序,如需降序,在命令的Z后添加REV:
- 升序排名:
ZRANK→ 降序排名:ZREVRANK; - 升序范围:
ZRANGE→ 降序范围:ZREVRANGE; - 升序分数范围:
ZRANGEBYSCORE→ 降序分数范围:ZREVRANGEBYSCORE。
四、实战示例:学生分数排行榜
需求:实现学生数学成绩的增删、排名查询、分数区间筛选
# 1. 新增/更新学生数学成绩
ZADD score:math 95 张三 88 李四 92 王五 85 赵六 98 钱七
# 2. 统计总人数
ZCARD score:math
# (integer) 5
# 3. 查询张三的分数
ZSCORE score:math 张三
# "95"
# 4. 查询张三的降序排名(第几名)
ZREVRANK score:math 张三
# (integer) 1 # 钱七98分第0名,张三95分第1名
# 5. 获取数学成绩前3名(降序)
ZREVRANGE score:math 0 2 WITHSCORES
# 1) "钱七"
# 2) "98"
# 3) "张三"
# 4) "95"
# 5) "王五"
# 6) "92"
# 6. 统计90分以上的学生数量
ZCOUNT score:math 90 +inf # +inf表示正无穷
# (integer) 3
# 7. 给李四加5分(分数从88→93)
ZINCRBY score:math 5 李四
# "93"
# 8. 获取90-95分的学生(升序)
ZRANGEBYSCORE score:math 90 95 WITHSCORES
# 1) "王五"
# 2) "92"
# 3) "李四"
# 4) "93"
# 5) "张三"
# 6) "95"
# 9. 删除赵六的成绩
ZREM score:math 赵六
# (integer) 1五、注意事项
score支持整数/浮点数,但浮点数运算可能有精度丢失,建议优先用整数(如分数乘以 100 存储);- 范围查询时,
ZRANGE按排名查,ZRANGEBYSCORE按分数查,需区分使用场景; - 超大 ZSet 的集合运算(ZINTER/ZUNION)会阻塞 Redis,生产环境建议异步执行或拆分数据。
六、命令速记表
| 命令 | 核心作用 | 关键特性 |
|---|---|---|
ZADD | 添加/更新元素及 score | 自动去重,更新 score 返回 0 |
ZREM | 删除元素 | 返回删除数量 |
ZSCORE | 获取元素 score | 不存在返回 nil |
ZRANK/ZREVRANK | 获取元素排名 | 升序/降序,从 0 开始 |
ZCARD | 获取元素数量 | O(1)复杂度 |
ZCOUNT | 统计分数区间元素数量 | 支持开区间( |
ZINCRBY | 元素 score 自增 | 原子操作,适合积分增减 |
ZRANGE/ZREVRANGE | 按排名范围查询 | 支持 WITHSCORES 返回分数 |
ZRANGEBYSCORE | 按分数范围查询 | 支持+inf/-inf 表示无穷 |
ZINTER/ZUNION | 集合交集/并集 | 需指定参与运算的集合数 |
总结
- Redis ZSet 基于跳表+哈希表实现,核心特性是「有序、唯一、查询高效」,是实现排行榜的最佳选择;
- 核心命令分三类:基础增删(ZADD/ZREM)、排名/分数查询(ZRANK/ZSCORE)、范围筛选(ZRANGE/ZRANGEBYSCORE);
- 所有排序默认升序,降序需加
REV前缀,WITHSCORES参数可返回元素对应的分数,是排行榜场景的常用参数。
基础篇-Redis 的 Go 客户端
01 goredis 快速入门
go-redis 是 Redis 官方推荐的 Go 语言客户端(v9 为最新稳定版),封装了 Redis 所有核心命令,支持上下文(Context)、连接池、集群等特性,是 Go 操作 Redis 的首选库。
一、安装
使用 go get 命令安装 go-redis/v9(需保证 Go 版本 ≥ 1.18):
go get github.com/redis/go-redis/v9二、连接 Redis
1. 基础连接(单机 Redis)
以下示例展示连接本地 Redis 的最简方式,包含核心配置项说明:
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 创建Redis客户端实例
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址(IP:端口)
Password: "", // 密码(无则为空)
DB: 0, // 使用默认数据库(0-15)
Protocol: 2, // Redis协议版本(2/3,默认2)
// 可选配置(生产环境建议添加)
PoolSize: 10, // 连接池大小
MinIdleConns: 5, // 最小空闲连接数
ReadTimeout: 1, // 读超时(秒)
WriteTimeout: 1, // 写超时(秒)
})
// 2. 测试连接是否正常
ctx := context.Background()
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("Redis连接失败: %v", err))
}
fmt.Println("✅ Redis连接成功")
}2. 其他连接场景(补充)
| 场景 | 核心配置调整 |
|---|---|
| 带密码连接 | Password: "your_password" |
| 远程 Redis | Addr: "192.168.1.100:6379" |
| WSL 中的 Redis | Addr: "WSL的IP:6379"(如 172.17.0.2:6379) |
三、基础操作示例
go-redis 提供两种操作方式:封装方法(推荐,类型安全)、原生命令(灵活,适配所有 Redis 命令)。
1. 封装方法(推荐)
封装方法与 Redis 命令一一对应,返回值已做类型处理,无需手动解析:
func main() {
// 初始化客户端(省略,同上文)
rdb := redis.NewClient(&redis.Options{Addr: "localhost:6379"})
ctx := context.Background()
// 1. 设置键值对(过期时间0表示永久)
err := rdb.Set(ctx, "test_key", "Hello from Windows!", 0).Err()
if err != nil {
fmt.Println("❌ 设置键失败:", err)
return
}
fmt.Println("✅ 设置键成功: test_key = Hello from Windows!")
// 2. 获取键值
val, err := rdb.Get(ctx, "test_key").Result()
if err != nil {
fmt.Println("❌ 获取键失败:", err)
return
}
fmt.Println("✅ 获取键成功:", val) // 输出:Hello from Windows!
// 3. 设置带过期时间的键(10秒过期)
err = rdb.Set(ctx, "expire_key", "10秒后过期", 10).Err()
if err != nil {
fmt.Println("❌ 设置过期键失败:", err)
return
}
// 4. 删除键
err = rdb.Del(ctx, "test_key").Err()
if err != nil {
fmt.Println("❌ 删除键失败:", err)
return
}
fmt.Println("✅ 删除键成功")
}2. 原生命令(Do 方法)
通过 rdb.Do() 执行原生 Redis 命令,适配所有命令(包括封装方法未覆盖的小众命令),需手动解析返回值:
func main() {
rdb := redis.NewClient(&redis.Options{Addr: "localhost:6379"})
ctx := context.Background()
// 执行原生SET命令:SET test_key "Hello from Windows!" EX 10
cmd := rdb.Do(ctx, "SET", "test_key", "Hello from Windows!", "EX", 10)
// 解析返回值(Text()适用于字符串结果,Result()返回interface{})
val, err := cmd.Text()
if err != nil {
fmt.Println("❌ 原生命令创建键失败:", err)
return
}
fmt.Println("✅ 原生命令创建键成功:", val) // 输出:OK
// 执行原生GET命令
getCmd := rdb.Do(ctx, "GET", "test_key")
getVal, err := getCmd.Text()
if err != nil {
fmt.Println("❌ 原生命令获取键失败:", err)
return
}
fmt.Println("✅ 原生命令获取键成功:", getVal) // 输出:Hello from Windows!
}四、核心 API 说明
| 方法/类型 | 作用 | 示例 |
|---|---|---|
redis.NewClient | 创建单机 Redis 客户端 | rdb := redis.NewClient(&redis.Options{}) |
rdb.Set(ctx, k, v, ttl) | 设置键值对,ttl 为过期时间(秒) | rdb.Set(ctx, "name", "张三", 0) |
rdb.Get(ctx, k) | 获取键值 | val, err := rdb.Get(ctx, "name").Result() |
rdb.Del(ctx, k) | 删除键 | rdb.Del(ctx, "name") |
rdb.Do(ctx, cmd, args...) | 执行原生命令 | rdb.Do(ctx, "HSET", "user:1", "age", 20) |
cmd.Result() | 获取原生命令结果(interface{}类型) | res, err := cmd.Result() |
cmd.Text() | 获取字符串类型结果(常用) | str, err := cmd.Text() |
cmd.Int() | 获取整数类型结果(如计数器、长度) | num, err := cmd.Int() |
五、错误处理最佳实践
go-redis 的错误主要分为两类,建议针对性处理:
// 示例:获取键时的错误处理
val, err := rdb.Get(ctx, "non_exist_key").Result()
switch {
case err == redis.Nil:
// 键不存在(最常见错误)
fmt.Println("❌ 键不存在")
case err != nil:
// 其他错误(如网络异常、Redis宕机)
fmt.Println("❌ 获取键失败:", err)
default:
// 成功
fmt.Println("✅ 键值:", val)
}六、注意事项
- 上下文(Context):所有操作都需传入
ctx,可用于设置超时、取消操作(如ctx, cancel := context.WithTimeout(ctx, 2*time.Second)); - 连接池:
go-redis自动管理连接池,生产环境建议配置PoolSize(默认 10)、MinIdleConns优化性能; - 数据类型转换:存储复杂结构(如结构体)时,需序列化为 JSON 字符串,读取后反序列化;
- 并发安全:
redis.Client实例是并发安全的,可在多个 goroutine 中共享。
总结
go-redis/v9是 Go 操作 Redis 的主流客户端,安装简单,支持单机/集群/哨兵等部署模式;- 推荐使用封装方法(类型安全、易维护),特殊场景用
Do()执行原生命令; - 核心操作流程:创建客户端 → 测试连接 → 执行命令 → 处理错误(重点区分
redis.Nil); - 上下文(Context)是必传参数,可用于控制操作超时和取消,生产环境建议合理设置超时时间。
02 String 类型操作
go-redis 对 Redis String 类型的所有核心命令提供了封装方法,接口简洁且类型安全。以下是 String 类型高频操作的完整示例,包含详细注释和最佳实践。
一、完整示例代码
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 初始化Redis客户端
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // 无密码
DB: 0, // 默认数据库
})
ctx := context.Background() // 上下文(可设置超时:context.WithTimeout(ctx, 2*time.Second))
// 2. 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("Redis连接失败: %v", err))
}
fmt.Println("✅ Redis连接成功")
// ==================== 核心操作 ====================
// 1. SET:设置单个键值对(永久有效)
err = rdb.Set(ctx, "gorediskey", "goredisvalue", 0).Err()
if err != nil {
panic(fmt.Sprintf("SET失败: %v", err))
}
fmt.Println("✅ SET成功: gorediskey = goredisvalue")
// 2. GET:获取单个键值
val, err := rdb.Get(ctx, "gorediskey").Result()
if err != nil {
panic(fmt.Sprintf("GET失败: %v", err))
}
fmt.Printf("✅ GET成功: gorediskey = %s\n", val)
// 3. GetSet:先获取旧值,再设置新值(原子操作)
oldVal, err := rdb.GetSet(ctx, "gorediskey", "goredisnewvalue").Result()
if err != nil {
panic(fmt.Sprintf("GetSet失败: %v", err))
}
fmt.Printf("✅ GetSet成功: 旧值=%s,新值=goredisnewvalue\n", oldVal)
// 4. SetNX:仅当键不存在时设置(分布式锁核心)
// 注意:SetNX返回bool类型,表示是否设置成功
ok, err := rdb.SetNX(ctx, "gorediskey", "goredisnxvalue", 0).Result()
if err != nil {
panic(fmt.Sprintf("SetNX失败: %v", err))
}
if ok {
fmt.Println("✅ SetNX成功: gorediskey = goredisnxvalue")
} else {
fmt.Println("❌ SetNX失败: gorediskey已存在,未覆盖")
}
// 5. MSet:批量设置多个键值对(原子操作)
err = rdb.MSet(ctx, "gorediskey", "goredismsvalue", "gorediskey2", "goredismsvalue2").Err()
if err != nil {
panic(fmt.Sprintf("MSet失败: %v", err))
}
fmt.Println("✅ MSet成功: gorediskey = goredismsvalue, gorediskey2 = goredismsvalue2")
// 6. MGet:批量获取多个键值
vals, err := rdb.MGet(ctx, "gorediskey", "gorediskey2").Result()
if err != nil {
panic(fmt.Sprintf("MGet失败: %v", err))
}
fmt.Println("✅ MGet结果:")
for i, key := range []string{"gorediskey", "gorediskey2"} {
fmt.Printf(" %s = %v\n", key, vals[i])
}
// 7. Incr/IncrBy:整数自增(需确保键值为整数)
// 先重置键值为整数1
err = rdb.Set(ctx, "gorediskey", "1", 0).Err()
if err != nil {
panic(fmt.Sprintf("SET整数失败: %v", err))
}
// IncrBy:自增100(Incr等价于IncrBy(..., 1))
newVal, err := rdb.IncrBy(ctx, "gorediskey", 100).Result()
if err != nil {
panic(fmt.Sprintf("IncrBy失败: %v", err))
}
fmt.Printf("✅ IncrBy成功: gorediskey = %d\n", newVal) // 输出101
// 8. Decr/DecrBy:整数自减
// Decr:自减1
newVal, err = rdb.Decr(ctx, "gorediskey").Result()
if err != nil {
panic(fmt.Sprintf("Decr失败: %v", err))
}
fmt.Printf("✅ Decr成功: gorediskey = %d\n", newVal) // 输出100
// DecrBy:自减100
newVal, err = rdb.DecrBy(ctx, "gorediskey", 100).Result()
if err != nil {
panic(fmt.Sprintf("DecrBy失败: %v", err))
}
fmt.Printf("✅ DecrBy成功: gorediskey = %d\n", newVal) // 输出0
// 9. Expire:设置键的过期时间(秒)
err = rdb.Expire(ctx, "gorediskey", 10).Err()
if err != nil {
panic(fmt.Sprintf("Expire失败: %v", err))
}
fmt.Println("✅ Expire成功: gorediskey 过期时间为10秒")
// 10. TTL:查看剩余过期时间(补充)
ttl, err := rdb.TTL(ctx, "gorediskey").Result()
if err != nil {
panic(fmt.Sprintf("TTL失败: %v", err))
}
fmt.Printf("✅ TTL成功: gorediskey 剩余过期时间 = %v\n", ttl)
}二、关键知识点解析
1. 核心方法说明
| 方法 | 作用 | 返回值/注意事项 |
|---|---|---|
Set(ctx, k, v, ttl) | 设置键值对 | ttl=0 表示永久,支持Set(ctx, k, v, 10*time.Second)设置过期 |
Get(ctx, k) | 获取键值 | 键不存在返回redis.Nil错误 |
GetSet(ctx, k, v) | 先获取旧值,再设置新值 | 返回旧值(原子操作,适合更新场景) |
SetNX(ctx, k, v, ttl) | 仅键不存在时设置 | 返回 bool:true=设置成功,false=键已存在 |
MSet/MGet | 批量设置/获取键值 | MGet 返回[]interface{},需按需类型转换 |
Incr/IncrBy | 整数自增 | 键值非整数会报错,返回自增后的值(int64) |
Decr/DecrBy | 整数自减 | 同上,返回自减后的值(int64) |
Expire(ctx, k, ttl) | 设置过期时间 | ttl 单位为秒,也可使用ExpireNX(仅未设置过期时生效) |
TTL(ctx, k) | 查看剩余过期时间 | 返回time.Duration,-1=永久,-2=键不存在 |
2. 错误处理最佳实践
// 推荐:区分“键不存在”和“其他错误”
val, err := rdb.Get(ctx, "non_exist_key").Result()
switch {
case err == redis.Nil:
fmt.Println("❌ 键不存在")
case err != nil:
fmt.Println("❌ GET失败:", err) // 网络异常、Redis宕机等
default:
fmt.Println("✅ 键值:", val)
}3. 原子操作说明
GetSet、SetNX、Incr/Decr均为原子操作,无需额外加锁,适合并发场景(如分布式锁、计数器);MSet/MGet是批量原子操作:要么所有键都设置/获取成功,要么都失败。
4. 类型注意事项
Incr/Decr仅支持整数类型的字符串,若键值为非整数(如”abc”),会返回ERR value is not an integer or out of range错误;- 存储浮点数自增需使用
IncrByFloat方法(补充):// 浮点数自增示例 rdb.Set(ctx, "float_key", "1.5", 0) newFloatVal, _ := rdb.IncrByFloat(ctx, "float_key", 0.5).Result() fmt.Println(newFloatVal) // 输出2.0
三、输出示例
✅ Redis连接成功
✅ SET成功: gorediskey = goredisvalue
✅ GET成功: gorediskey = goredisvalue
✅ GetSet成功: 旧值=goredisvalue,新值=goredisnewvalue
❌ SetNX失败: gorediskey已存在,未覆盖
✅ MSet成功: gorediskey = goredismsvalue, gorediskey2 = goredismsvalue2
✅ MGet结果:
gorediskey = goredismsvalue
gorediskey2 = goredismsvalue2
✅ IncrBy成功: gorediskey = 101
✅ Decr成功: gorediskey = 100
✅ DecrBy成功: gorediskey = 0
✅ Expire成功: gorediskey 过期时间为10秒
✅ TTL成功: gorediskey 剩余过期时间 = 10s总结
go-redis对 String 类型的封装完全对齐 Redis 原生命令,方法名和参数直观易记;- 核心注意点:
SetNX返回 bool 类型(是否设置成功)、Incr/Decr仅支持整数、Get需处理redis.Nil(键不存在); - 原子操作(
SetNX/Incr/GetSet)是 String 类型的核心优势,适合分布式锁、计数器等并发场景; - 过期时间可通过
Set的第三个参数(ttl)直接设置,也可通过Expire单独设置,推荐前者(减少一次网络请求)。
03 Hash 类型操作
go-redis 对 Redis Hash 类型(散列)的所有核心命令提供了简洁封装,支持单字段/多字段、数值运算、批量操作等场景,是存储结构化数据(如用户信息)的首选方式。以下是完整示例和关键知识点解析。
一、完整示例代码
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 初始化Redis客户端
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // 无密码
DB: 0, // 默认数据库
})
ctx := context.Background() // 上下文(可设置超时:context.WithTimeout(ctx, 2*time.Second))
// 2. 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("Redis连接失败: %v", err))
}
fmt.Println("✅ Redis连接成功")
// ==================== Hash核心操作 ====================
// 1. HSET:设置单个字段值
err = rdb.HSet(ctx, "user", "name", "张三").Err()
if err != nil {
panic(fmt.Sprintf("HSET失败: %v", err))
}
fmt.Println("✅ HSET成功: user -> name=张三")
// 2. HGET:获取单个字段值
name, err := rdb.HGet(ctx, "user", "name").Result()
if err != nil {
panic(fmt.Sprintf("HGET失败: %v", err))
}
fmt.Printf("✅ HGET成功: user.name = %s\n", name)
// 3. HGETALL:获取Hash中所有字段和值(返回map[string]string)
user, err := rdb.HGetAll(ctx, "user").Result()
if err != nil {
panic(fmt.Sprintf("HGETALL失败: %v", err))
}
fmt.Printf("✅ HGETALL成功: user = %v\n", user)
// 4. HINCRBY:字段值整数自增(自动初始化字段为0)
age, err := rdb.HIncrBy(ctx, "user", "age", 1).Result()
if err != nil {
panic(fmt.Sprintf("HINCRBY失败: %v", err))
}
fmt.Printf("✅ HINCRBY成功: user.age自增1后 = %d\n", age) // 输出1
// 5. HKEYS:获取Hash中所有字段名
keys, err := rdb.HKeys(ctx, "user").Result()
if err != nil {
panic(fmt.Sprintf("HKEYS失败: %v", err))
}
fmt.Printf("✅ HKEYS成功: user的字段列表 = %v\n", keys) // 输出[name age]
// 6. HLEN:获取Hash的字段数量
len, err := rdb.HLen(ctx, "user").Result()
if err != nil {
panic(fmt.Sprintf("HLEN失败: %v", err))
}
fmt.Printf("✅ HLEN成功: user的字段数量 = %d\n", len) // 输出2
// 7. HMGET:批量获取多个字段值(返回[]interface{})
values, err := rdb.HMGet(ctx, "user", "name", "age").Result()
if err != nil {
panic(fmt.Sprintf("HMGET失败: %v", err))
}
fmt.Printf("✅ HMGET成功: user[name,age] = %v\n", values) // 输出[张三 1]
// 8. HMSET:批量设置多个字段值(传入map)
data := make(map[string]interface{})
data["name"] = "李四"
data["age"] = 25
err = rdb.HMSet(ctx, "user2", data).Err()
if err != nil {
panic(fmt.Sprintf("HMSET失败: %v", err))
}
fmt.Println("✅ HMSET成功: user2 -> name=李四, age=25")
// 9. HSETNX:仅当字段不存在时设置(返回bool)
ok, err := rdb.HSetNX(ctx, "user", "name", "王五").Result()
if err != nil {
panic(fmt.Sprintf("HSETNX失败: %v", err))
}
if ok {
fmt.Println("✅ HSETNX成功: user.name设置为王五")
} else {
fmt.Println("❌ HSETNX失败: user.name已存在,未覆盖")
}
// 10. HDEL:删除Hash中的指定字段
delCount, err := rdb.HDel(ctx, "user", "age").Result()
if err != nil {
panic(fmt.Sprintf("HDEL失败: %v", err))
}
fmt.Printf("✅ HDEL成功: 删除user.age,删除字段数 = %d\n", delCount) // 输出1
// 补充:HVALS - 获取Hash中所有字段值(示例)
vals, err := rdb.HVals(ctx, "user").Result()
if err != nil {
panic(fmt.Sprintf("HVALS失败: %v", err))
}
fmt.Printf("✅ HVALS成功: user的字段值列表 = %v\n", vals) // 输出[张三]
}二、关键知识点解析
1. 核心方法说明
| 方法 | 作用 | 返回值/注意事项 |
|---|---|---|
HSet(ctx, key, field, value) | 设置单个字段值 | 支持链式调用,Err()获取错误 |
HGet(ctx, key, field) | 获取单个字段值 | 字段不存在返回redis.Nil |
HGetAll(ctx, key) | 获取所有字段和值 | 返回map[string]string,空 Hash 返回空 map |
HIncrBy(ctx, key, field, incr) | 字段值自增 | 字段不存在时自动初始化为 0,返回自增后的值(int64) |
HKeys(ctx, key) | 获取所有字段名 | 返回[]string |
HLen(ctx, key) | 获取字段数量 | 返回 int64,O(1)复杂度 |
HMGet(ctx, key, fields...) | 批量获取字段值 | 返回[]interface{},需手动类型转换 |
HMSet(ctx, key, data map) | 批量设置字段值 | 原子操作,支持任意类型 value(自动转字符串) |
HSetNX(ctx, key, field, value) | 字段不存在时设置 | 返回 bool:true=成功,false=字段已存在 |
HDel(ctx, key, fields...) | 删除指定字段 | 返回删除成功的字段数(int64) |
HVals(ctx, key) | 获取所有字段值 | 返回[]string |
2. 错误处理最佳实践
// 区分“字段不存在”和“其他错误”
val, err := rdb.HGet(ctx, "user", "gender").Result()
switch {
case err == redis.Nil:
fmt.Println("❌ 字段gender不存在")
case err != nil:
fmt.Println("❌ HGET失败:", err) // 网络异常等
default:
fmt.Println("✅ 字段值:", val)
}3. 实用技巧
- 结构化数据存储:将 Go 结构体序列化为 map 后通过
HMSet存储,读取后反序列化:// 示例:User结构体转map存储 type User struct { Name string Age int } u := User{Name: "张三", Age: 20} userMap := map[string]interface{}{ "name": u.Name, "age": u.Age, } rdb.HMSet(ctx, "user:1001", userMap) - 避免 HGETALL 阻塞:若 Hash 字段数量极多(如 1000+),优先用
HSCAN分批遍历,而非HGETALL。 - 数值字段初始化:
HIncrBy无需提前初始化字段,不存在时自动设为 0 后自增,简化代码。
三、输出示例
✅ Redis连接成功
✅ HSET成功: user -> name=张三
✅ HGET成功: user.name = 张三
✅ HGETALL成功: user = map[name:张三]
✅ HINCRBY成功: user.age自增1后 = 1
✅ HKEYS成功: user的字段列表 = [name age]
✅ HLEN成功: user的字段数量 = 2
✅ HMGET成功: user[name,age] = [张三 1]
✅ HMSET成功: user2 -> name=李四, age=25
❌ HSETNX失败: user.name已存在,未覆盖
✅ HDEL成功: 删除user.age,删除字段数 = 1
✅ HVALS成功: user的字段值列表 = [张三]总结
go-redis对 Hash 类型的封装完全对齐 Redis 原生命令,支持单/多字段、数值运算、条件设置等所有核心场景;- 核心优势:可单独操作字段,无需序列化整个对象,适合频繁修改结构化数据的场景(如用户信息、商品详情);
- 关键注意点:
HSetNX返回 bool(字段是否不存在)、HIncrBy自动初始化字段、HMGet返回[]interface{}需类型转换; - 性能建议:大 Hash 避免使用
HGETALL,优先用HSCAN分批读取,减少 Redis 阻塞。
04 List 类型操作
go-redis 对 Redis List 类型(双向链表)的核心命令提供了完整封装,支持头尾增删、范围查询、阻塞弹出等操作,是实现消息队列、栈、最新列表的核心方式。以下是完善后的示例代码和关键知识点解析。
一、完整示例代码
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 初始化Redis客户端
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // 无密码
DB: 0, // 默认数据库
})
ctx := context.Background() // 上下文(可设置超时:ctx, _ = context.WithTimeout(ctx, 3*time.Second))
// 2. 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("Redis连接失败: %v", err))
}
fmt.Println("✅ Redis连接成功")
// ==================== List核心操作 ====================
// 1. LPUSH:将一个/多个值推送到列表左侧(表头),返回新长度
lpushLen, err := rdb.LPush(ctx, "mylist", "item1", "item2", "item3").Result()
if err != nil {
panic(fmt.Sprintf("LPUSH失败: %v", err))
}
fmt.Printf("✅ LPUSH成功: 列表新长度 = %d\n", lpushLen) // 输出3
// 2. LPUSHX:仅当列表存在时,向左侧推送元素(返回新长度)
lpushxLen, err := rdb.LPushX(ctx, "mylist", "item4", "item5", "item6").Result()
if err != nil {
panic(fmt.Sprintf("LPUSHX失败: %v", err))
}
fmt.Printf("✅ LPUSHX成功: 列表新长度 = %d\n", lpushxLen) // 输出6
// 3. RPOP:从列表右侧(表尾)弹出一个元素
rpopVal, err := rdb.RPop(ctx, "mylist").Result()
if err != nil {
if err == redis.Nil {
fmt.Println("❌ RPOP失败: 列表为空")
} else {
panic(fmt.Sprintf("RPOP失败: %v", err))
}
} else {
fmt.Printf("✅ RPOP成功: 弹出元素 = %s\n", rpopVal) // 输出item1(LPUSH后列表是[item6,item5,item4,item3,item2,item1],RPOP弹出item1)
}
// 4. RPUSH:向列表右侧(表尾)推送元素(补充示例)
rpushLen, err := rdb.RPush(ctx, "mylist", "item7").Result()
if err != nil {
panic(fmt.Sprintf("RPUSH失败: %v", err))
}
fmt.Printf("✅ RPUSH成功: 列表新长度 = %d\n", rpushLen) // 输出6
// 5. LPOP:从列表左侧(表头)弹出元素(补充示例)
lpopVal, err := rdb.LPop(ctx, "mylist").Result()
if err != nil {
if err == redis.Nil {
fmt.Println("❌ LPOP失败: 列表为空")
} else {
panic(fmt.Sprintf("LPOP失败: %v", err))
}
} else {
fmt.Printf("✅ LPOP成功: 弹出元素 = %s\n", lpopVal) // 输出item6
}
// 6. LLEN:获取列表长度
len, err := rdb.LLen(ctx, "mylist").Result()
if err != nil {
panic(fmt.Sprintf("LLEN失败: %v", err))
}
fmt.Printf("✅ LLEN成功: 列表长度 = %d\n", len) // 输出5
// 7. LRANGE:获取列表指定范围元素(0=-1表示所有)
items, err := rdb.LRange(ctx, "mylist", 0, -1).Result()
if err != nil {
panic(fmt.Sprintf("LRANGE失败: %v", err))
}
fmt.Printf("✅ LRANGE成功: 列表所有元素 = %v\n", items) // 输出[item5,item4,item3,item2,item7]
// 8. LINDEX:获取列表指定索引的元素(索引从0开始,负数表示倒数)
indexVal, err := rdb.LIndex(ctx, "mylist", 0).Result()
if err != nil {
if err == redis.Nil {
fmt.Println("❌ LINDEX失败: 索引不存在")
} else {
panic(fmt.Sprintf("LINDEX失败: %v", err))
}
} else {
fmt.Printf("✅ LINDEX成功: 索引0的元素 = %s\n", indexVal) // 输出item5
}
// 9. LREM:删除列表中指定值的元素(count规则:0=删除所有,正数=从左删count个,负数=从右删count个)
remCount, err := rdb.LRem(ctx, "mylist", 0, "item2").Result()
if err != nil {
panic(fmt.Sprintf("LREM失败: %v", err))
}
fmt.Printf("✅ LREM成功: 删除item2的数量 = %d\n", remCount) // 输出1
// 10. LINSERT:在指定元素前/后插入新元素
insertLen, err := rdb.LInsert(ctx, "mylist", "before", "item3", "item1").Result()
if err != nil {
panic(fmt.Sprintf("LINSERT失败: %v", err))
}
fmt.Printf("✅ LINSERT成功: 插入后列表长度 = %d\n", insertLen) // 输出5
// 补充:阻塞弹出(BRPOP/BLPOP)- 消息队列核心
// brpopVal, err := rdb.BRPop(ctx, 0, "mylist").Result() // 0表示永久阻塞
// if err != nil {
// panic(fmt.Sprintf("BRPOP失败: %v", err))
// }
// fmt.Printf("✅ BRPOP成功: 弹出元素 = %v\n", brpopVal) // 返回[列表名, 元素值]
// 补充:清空列表(实战常用)
_, err = rdb.Del(ctx, "mylist").Result()
if err != nil {
panic(fmt.Sprintf("Del失败: %v", err))
}
fmt.Println("✅ Del成功: 清空mylist列表")
}二、关键知识点解析
1. 核心方法说明
| 方法 | 作用 | 返回值/注意事项 |
|---|---|---|
LPush(ctx, key, vals...) | 左侧(表头)插入元素 | 返回新列表长度(int64) |
LPushX(ctx, key, vals...) | 仅列表存在时左侧插入 | 返回新长度,列表不存在返回 0 |
RPush/RPushX | 右侧(表尾)插入/条件插入 | 同 LPush/LPushX,方向相反 |
LPop/RPop | 左侧/右侧弹出元素 | 元素不存在返回redis.Nil |
LLen(ctx, key) | 获取列表长度 | O(1)复杂度,空列表返回 0 |
LRange(ctx, key, start, end) | 范围查询元素 | start/end支持负数(-1=最后一个元素) |
LIndex(ctx, key, idx) | 获取指定索引元素 | 索引越界返回redis.Nil |
LRem(ctx, key, count, val) | 删除指定值元素 | count=0 删除所有,正数从左删,负数从右删 |
LInsert(ctx, key, op, pivot, val) | 插入元素 | op=“before”/“after”,pivot 为参考元素,返回新长度 |
BRPop/BLPop | 阻塞式弹出元素 | 第一个参数为超时时间(秒),0=永久阻塞 |
2. 常见错误处理
// 弹出/查询类操作的标准错误处理
val, err := rdb.RPop(ctx, "empty_list").Result()
switch {
case err == redis.Nil:
fmt.Println("❌ 列表为空/索引不存在")
case err != nil:
fmt.Println("❌ 命令执行失败:", err) // 网络异常、Redis宕机等
default:
fmt.Println("✅ 操作成功:", val)
}3. 实战场景示例
(1)模拟栈(先进后出)
// 入栈:LPush
rdb.LPush(ctx, "stack", "a", "b", "c")
// 出栈:LPop
val, _ := rdb.LPop(ctx, "stack").Result() // 弹出c(2)模拟普通队列(先进先出)
// 入队:LPush
rdb.LPush(ctx, "queue", "order1", "order2")
// 出队:RPop
val, _ := rdb.RPop(ctx, "queue").Result() // 弹出order1(3)模拟阻塞队列(消息消费)
// 消费者(永久阻塞等待)
for {
res, err := rdb.BRPop(ctx, 0, "block_queue").Result()
if err != nil {
fmt.Println("消费失败:", err)
continue
}
// res格式:[队列名, 消息内容]
fmt.Println("消费消息:", res[1])
}三、输出示例
✅ Redis连接成功
✅ LPUSH成功: 列表新长度 = 3
✅ LPUSHX成功: 列表新长度 = 6
✅ RPOP成功: 弹出元素 = item1
✅ RPUSH成功: 列表新长度 = 6
✅ LPOP成功: 弹出元素 = item6
✅ LLEN成功: 列表长度 = 5
✅ LRANGE成功: 列表所有元素 = [item5 item4 item3 item2 item7]
✅ LINDEX成功: 索引0的元素 = item5
✅ LREM成功: 删除item2的数量 = 1
✅ LINSERT成功: 插入后列表长度 = 5
✅ Del成功: 清空mylist列表四、注意事项
LRange查询超大列表(如百万级元素)会阻塞 Redis,生产环境需限制返回长度(如0 99仅查前 100 个);- 阻塞命令(
BRPop/BLPop)会占用客户端连接,需合理设置超时时间,避免连接泄漏; LInsert的参考元素(pivot)不存在时,会返回redis.Nil错误,需提前校验;- List 作为消息队列仅适合简单场景,不支持消息确认、重试,复杂场景建议用专业 MQ(如 RabbitMQ)。
总结
- Redis List 是双向链表结构,
go-redis封装的核心操作分为「增删(LPush/RPop)、查询(LLen/LRange)、修改(LRem/LInsert)」三类; - 方向是核心:
L开头为左侧(表头)操作,R开头为右侧(表尾)操作; - 阻塞弹出(
BRPop/BLPop)是实现阻塞队列的关键,避免轮询消耗资源; - 错误处理需区分
redis.Nil(列表为空/索引不存在)和其他运行时错误。
05 Set 类型操作
go-redis 对 Redis Set 类型(无序无重复集合)的核心命令提供了完整封装,支持元素增删、成员校验、随机抽取、集合运算等操作,是实现数据去重、共同好友、随机抽奖的核心方式。以下是完善后的示例代码和关键知识点解析。
一、完整示例代码
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 初始化Redis客户端
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // 无密码
DB: 0, // 默认数据库
})
ctx := context.Background() // 上下文(可设置超时:ctx, _ = context.WithTimeout(ctx, 3*time.Second))
// 2. 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("Redis连接失败: %v", err))
}
fmt.Println("✅ Redis连接成功")
// ==================== Set核心操作 ====================
// 1. SADD:向集合添加一个/多个元素(自动去重),返回新增元素数量
addCount, err := rdb.SAdd(ctx, "myset", "item1", "item2", "item3", "item2").Result()
if err != nil {
panic(fmt.Sprintf("SADD失败: %v", err))
}
fmt.Printf("✅ SADD成功: 新增元素数量 = %d\n", addCount) // 输出3(item2重复,不计入)
// 2. SCARD:获取集合的元素数量(长度)
card, err := rdb.SCard(ctx, "myset").Result()
if err != nil {
panic(fmt.Sprintf("SCARD失败: %v", err))
}
fmt.Printf("✅ SCARD成功: 集合元素数量 = %d\n", card) // 输出3
// 3. SIsMember:判断元素是否存在于集合中(返回bool)
isMember, err := rdb.SIsMember(ctx, "myset", "item1").Result()
if err != nil {
panic(fmt.Sprintf("SIsMember失败: %v", err))
}
fmt.Printf("✅ SIsMember成功: item1是否在集合中 = %v\n", isMember) // 输出true
// 4. SREM:删除集合中指定元素,返回删除成功的数量
remCount, err := rdb.SRem(ctx, "myset", "item1").Result()
if err != nil {
panic(fmt.Sprintf("SREM失败: %v", err))
}
fmt.Printf("✅ SREM成功: 删除item1的数量 = %d\n", remCount) // 输出1
// 5. SMEMBERS:获取集合中所有元素(⚠️ 大集合慎用,易阻塞Redis)
members, err := rdb.SMembers(ctx, "myset").Result()
if err != nil {
panic(fmt.Sprintf("SMEMBERS失败: %v", err))
}
fmt.Printf("✅ SMEMBERS成功: 集合元素 = %v\n", members) // 输出[item2 item3]
// 6. SPOP:随机弹出集合中的1个元素
popItem, err := rdb.SPop(ctx, "myset").Result()
if err != nil {
if err == redis.Nil {
fmt.Println("❌ SPOP失败: 集合为空")
} else {
panic(fmt.Sprintf("SPOP失败: %v", err))
}
} else {
fmt.Printf("✅ SPOP成功: 随机弹出元素 = %s\n", popItem) // 随机输出item2或item3
}
// 7. SPopN:随机弹出集合中的N个元素(返回切片)
// 先补充元素,避免集合为空
rdb.SAdd(ctx, "myset", "item4", "item5", "item6")
popNItems, err := rdb.SPopN(ctx, "myset", 2).Result()
if err != nil {
panic(fmt.Sprintf("SPopN失败: %v", err))
}
fmt.Printf("✅ SPopN成功: 随机弹出2个元素 = %v\n", popNItems) // 如[item4 item5]
// 补充:SRANDMEMBER - 随机获取N个元素(不弹出,仅查询)
randomItems, err := rdb.SRandMemberN(ctx, "myset", 1).Result()
if err != nil {
panic(fmt.Sprintf("SRandMemberN失败: %v", err))
}
fmt.Printf("✅ SRandMemberN成功: 随机获取1个元素(不弹出) = %v\n", randomItems)
// 补充:集合运算(交集/并集/差集)- 核心场景
// 初始化两个测试集合
rdb.SAdd(ctx, "set1", "a", "b", "c")
rdb.SAdd(ctx, "set2", "b", "c", "d")
// 交集(同时存在于set1和set2的元素)
inter, err := rdb.SInter(ctx, "set1", "set2").Result()
if err != nil {
panic(fmt.Sprintf("SInter失败: %v", err))
}
fmt.Printf("✅ SInter成功: set1和set2的交集 = %v\n", inter) // 输出[b c]
// 并集(set1和set2的所有元素,去重)
union, err := rdb.SUnion(ctx, "set1", "set2").Result()
if err != nil {
panic(fmt.Sprintf("SUnion失败: %v", err))
}
fmt.Printf("✅ SUnion成功: set1和set2的并集 = %v\n", union) // 输出[a b c d]
// 差集(存在于set1但不存在于set2的元素)
diff, err := rdb.SDiff(ctx, "set1", "set2").Result()
if err != nil {
panic(fmt.Sprintf("SDiff失败: %v", err))
}
fmt.Printf("✅ SDiff成功: set1相对set2的差集 = %v\n", diff) // 输出[a]
// 清空测试集合(实战常用)
rdb.Del(ctx, "myset", "set1", "set2")
fmt.Println("✅ Del成功: 清空所有测试集合")
}二、关键知识点解析
1. 核心方法说明
| 方法 | 作用 | 返回值/注意事项 |
|---|---|---|
SAdd(ctx, key, vals...) | 添加元素到集合 | 返回新增元素数量(int64),重复元素不计入 |
SCard(ctx, key) | 获取集合元素数量 | O(1)复杂度,空集合返回 0 |
SIsMember(ctx, key, val) | 判断元素是否在集合中 | 返回 bool,O(1)复杂度(核心去重校验) |
SRem(ctx, key, vals...) | 删除集合中指定元素 | 返回删除成功的数量(int64) |
SMembers(ctx, key) | 获取集合所有元素 | 返回[]string,大集合(10 万+)慎用,易阻塞 |
SPop(ctx, key) | 随机弹出 1 个元素 | 集合为空返回redis.Nil |
SPopN(ctx, key, n) | 随机弹出 n 个元素 | 返回[]string,n 超过集合长度则返回所有元素 |
SRandMemberN(ctx, key, n) | 随机获取 n 个元素(不弹出) | 非破坏性查询,适合随机推荐/抽奖 |
SInter/SUnion/SDiff | 集合交集/并集/差集 | 支持多个集合运算,返回[]string |
2. 错误处理最佳实践
// 弹出/查询类操作的标准错误处理
val, err := rdb.SPop(ctx, "empty_set").Result()
switch {
case err == redis.Nil:
fmt.Println("❌ 操作失败: 集合为空")
case err != nil:
fmt.Println("❌ 命令执行失败:", err) // 网络异常、Redis宕机等
default:
fmt.Println("✅ 操作成功:", val)
}3. 实战场景示例
(1)用户点赞去重
// 点赞(添加元素,自动去重)
rdb.SAdd(ctx, "user:1001:likes", "post:2001")
// 取消点赞(删除元素)
rdb.SRem(ctx, "user:1001:likes", "post:2001")
// 校验是否点赞
isLike, _ := rdb.SIsMember(ctx, "user:1001:likes", "post:2001").Result()(2)随机抽奖
// 初始化抽奖名单
rdb.SAdd(ctx, "lottery", "user1", "user2", "user3", "user4", "user5")
// 抽取1名一等奖
firstPrize, _ := rdb.SPop(ctx, "lottery").Result()
// 抽取2名二等奖(不弹出,可重复抽)
secondPrize, _ := rdb.SRandMemberN(ctx, "lottery", 2).Result()
fmt.Printf("一等奖: %s,二等奖: %v\n", firstPrize, secondPrize)(3)共同好友查询
// 初始化两个用户的好友集合
rdb.SAdd(ctx, "user:1001:friends", "1002", "1003", "1004")
rdb.SAdd(ctx, "user:1002:friends", "1001", "1003", "1005")
// 查询共同好友
commonFriends, _ := rdb.SInter(ctx, "user:1001:friends", "user:1002:friends").Result()
fmt.Println("共同好友:", commonFriends) // 输出[1003]三、输出示例
✅ Redis连接成功
✅ SADD成功: 新增元素数量 = 3
✅ SCARD成功: 集合元素数量 = 3
✅ SIsMember成功: item1是否在集合中 = true
✅ SREM成功: 删除item1的数量 = 1
✅ SMEMBERS成功: 集合元素 = [item2 item3]
✅ SPOP成功: 随机弹出元素 = item2
✅ SPopN成功: 随机弹出2个元素 = [item6 item4]
✅ SRandMemberN成功: 随机获取1个元素(不弹出) = [item5]
✅ SInter成功: set1和set2的交集 = [b c]
✅ SUnion成功: set1和set2的并集 = [a b c d]
✅ SDiff成功: set1相对set2的差集 = [a]
✅ Del成功: 清空所有测试集合四、注意事项
SMembers命令在元素过多时会阻塞 Redis,生产环境优先用SScan分批遍历(替代方案):// SScan分批遍历集合(避免阻塞) var cursor uint64 var allMembers []string for { var members []string cursor, members, err = rdb.SScan(ctx, "myset", cursor, "", 10).Result() if err != nil { panic(err) } allMembers = append(allMembers, members...) if cursor == 0 { break } } fmt.Println("分批遍历结果:", allMembers)SPop/SPopN是破坏性操作(弹出元素),SRandMemberN是非破坏性操作(仅查询),根据场景选择;- 集合运算(
SInter/SUnion/SDiff)的性能与集合大小正相关,超大集合运算需异步执行。
总结
- Redis Set 是无序无重复集合,
go-redis封装的核心操作分为「增删(SAdd/SRem)、校验(SIsMember)、查询(SCard/SMembers)、随机操作(SPop/SRandMemberN)、集合运算(SInter)」五类; - 核心优势:元素自动去重、成员校验 O(1)复杂度、原生支持集合运算,适合去重、抽奖、共同好友等场景;
- 性能注意:大集合避免使用
SMembers,优先用SScan分批遍历; - 错误处理需区分
redis.Nil(集合为空)和其他运行时错误。
06 SortedSet (ZSet) 类型操作
go-redis 对 Redis SortedSet(有序集合) 提供完整封装,它是可排序、无重复、带分数的集合类型,结合了 Set 的去重特性 + 有序排序特性,是实现排行榜、热度排序、延时队列、范围筛选的核心数据结构。
SortedSet 核心特点:
- 每个元素绑定一个分数(Score),Redis 根据分数自动排序
- 元素唯一,分数可重复
- 支持正序/倒序查询、范围查询、分数增减、排名查询
- 时间复杂度低,高性能排序场景首选
一、完整示例代码
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 初始化Redis客户端
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // Redis地址
Password: "", // 无密码
DB: 0, // 默认数据库
})
ctx := context.Background() // 上下文(可设置超时)
// 2. 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("Redis连接失败: %v", err))
}
fmt.Println("✅ Redis连接成功")
// ==================== SortedSet 核心操作 ====================
// 1. ZADD:向有序集合添加元素(指定分数+成员,自动去重+排序)
err = rdb.ZAdd(ctx, "rank:user",
redis.Z{Score: 90, Member: "user01"},
redis.Z{Score: 85, Member: "user02"},
redis.Z{Score: 95, Member: "user03"},
redis.Z{Score: 90, Member: "user04"}, // 分数可重复
).Err()
if err != nil {
panic(fmt.Sprintf("ZADD失败: %v", err))
}
fmt.Println("✅ ZADD成功:添加用户分数")
// 2. ZCARD:获取有序集合元素总数
card, err := rdb.ZCard(ctx, "rank:user").Result()
if err != nil {
panic(fmt.Sprintf("ZCARD失败: %v", err))
}
fmt.Printf("✅ ZCARD成功:集合总元素数 = %d\n", card)
// 3. ZCOUNT:统计指定分数区间内的元素数量
count, err := rdb.ZCount(ctx, "rank:user", "90", "100").Result()
if err != nil {
panic(fmt.Sprintf("ZCOUNT失败: %v", err))
}
fmt.Printf("✅ ZCOUNT成功:90-100分的用户数 = %d\n", count)
// 4. ZINCRBY:给指定元素增加/减少分数(加分/减分)
newScore, err := rdb.ZIncrBy(ctx, "rank:user", 5, "user01").Result()
if err != nil {
panic(fmt.Sprintf("ZINCRBY失败: %v", err))
}
fmt.Printf("✅ ZINCRBY成功:user01加分后分数 = %.0f\n", newScore)
// 5. ZRANGE:正序获取元素(分数从低到高)0~-1代表全部
ascMembers, err := rdb.ZRange(ctx, "rank:user", 0, -1).Result()
if err != nil {
panic(fmt.Sprintf("ZRANGE失败: %v", err))
}
fmt.Printf("✅ ZRANGE成功:正序(低→高) = %v\n", ascMembers)
// 6. ZRANGE 带分数(新版推荐,替代旧方法)
withScore, err := rdb.ZRangeWithScores(ctx, "rank:user", 0, -1).Result()
if err != nil {
panic(fmt.Sprintf("ZRANGEWithScores失败: %v", err))
}
fmt.Println("✅ ZRANGEWithScores成功:正序+分数")
for _, z := range withScore {
fmt.Printf(" 用户:%s,分数:%.0f\n", z.Member, z.Score)
}
// 7. ZRangeArgs:全能查询(支持倒序、按分数范围、分页等,官方推荐)
// 倒序查询(高→低,排行榜常用)
descMembers, err := rdb.ZRangeArgs(ctx, redis.ZRangeArgs{
Key: "rank:user",
Start: 0,
Stop: -1,
ByScore: false, // 按索引排序
Rev: true, // 倒序
}).Result()
if err != nil {
panic(fmt.Sprintf("ZRangeArgs失败: %v", err))
}
fmt.Printf("✅ ZRangeArgs成功:倒序(高→低) = %v\n", descMembers)
// 8. ZRANK:获取元素正序排名(从0开始,分数越低排名越靠前)
rank, err := rdb.ZRank(ctx, "rank:user", "user03").Result()
if err != nil {
panic(fmt.Sprintf("ZRANK失败: %v", err))
}
fmt.Printf("✅ ZRANK成功:user03正序排名 = %d\n", rank)
// 9. ZREVRANK:获取元素倒序排名(排行榜第一名=0)
revRank, err := rdb.ZRevRank(ctx, "rank:user", "user03").Result()
if err != nil {
panic(fmt.Sprintf("ZREVRANK失败: %v", err))
}
fmt.Printf("✅ ZREVRANK成功:user03倒序排名(排行榜) = %d\n", revRank)
// 10. ZSCORE:查询指定元素的分数
score, err := rdb.ZScore(ctx, "rank:user", "user01").Result()
if err != nil {
panic(fmt.Sprintf("ZSCORE失败: %v", err))
}
fmt.Printf("✅ ZSCORE成功:user01当前分数 = %.0f\n", score)
// 11. ZREM:删除指定元素
remCount, err := rdb.ZRem(ctx, "rank:user", "user02").Result()
if err != nil {
panic(fmt.Sprintf("ZREM失败: %v", err))
}
fmt.Printf("✅ ZREM成功:删除元素数量 = %d\n", remCount)
// 12. ZREMRANGEBYRANK:按排名范围删除
delRankCount, err := rdb.ZRemRangeByRank(ctx, "rank:user", 0, 0).Result()
if err != nil {
panic(fmt.Sprintf("ZREMRANGEBYRANK失败: %v", err))
}
fmt.Printf("✅ ZREMRANGEBYRANK成功:按排名删除数量 = %d\n", delRankCount)
// 13. ZREMRANGEBYSCORE:按分数范围删除
delScoreCount, err := rdb.ZRemRangeByScore(ctx, "rank:user", "0", "80").Result()
if err != nil {
panic(fmt.Sprintf("ZREMRANGEBYSCORE失败: %v", err))
}
fmt.Printf("✅ ZREMRANGEBYSCORE成功:按分数删除数量 = %d\n", delScoreCount)
// 清空测试数据
rdb.Del(ctx, "rank:user")
fmt.Println("✅ 清空测试集合成功")
}二、关键知识点解析
1. 核心方法说明
| 方法 | 作用 | 核心说明 |
|---|---|---|
ZAdd | 添加带分数的元素 | 自动去重,按分数排序 |
ZCard | 获取元素总数 | O(1) 复杂度 |
ZCount | 统计指定分数区间的元素数量 | 分数参数为字符串 |
ZIncrBy | 增减元素分数 | 支持负数减分,返回最新分数 |
ZRange | 正序获取元素(低→高) | 0~-1 查全部 |
ZRangeWithScores | 正序获取元素+分数 | 排行榜展示必备 |
ZRangeArgs | 全能查询(倒序/分数范围/分页) | Redis 6.2+ 推荐,替代所有旧范围命令 |
ZRank/ZRevRank | 查询正序/倒序排名 | 排名从 0 开始 |
ZScore | 查询元素分数 | 不存在返回 redis.Nil |
ZRem | 删除指定元素 | 返回删除数量 |
ZRemRangeByRank | 按排名范围删除 | 清理垫底数据 |
ZRemRangeByScore | 按分数范围删除 | 清理低分/过期数据 |
2. 重要说明
- 排名规则
ZRank:分数从小到大排名,第一名(最低分)= 0ZRevRank:分数从大到小排名,排行榜第一名 = 0
- 废弃命令
ZRevRange/ZRangeByScore已弃用- 统一使用
ZRangeArgs实现所有排序/范围需求
- 错误处理
- 查询不存在的元素会返回
redis.Nil,必须做判断
- 查询不存在的元素会返回
三、实战场景示例
(1)游戏/积分排行榜(最常用场景)
ctx := context.Background()
key := "game:rank"
// 1. 上传分数
rdb.ZAdd(ctx, key, redis.Z{Score: 1200, Member: "player_1001"})
// 2. 加分(连胜奖励)
rdb.ZIncrBy(ctx, key, 100, "player_1001")
// 3. 获取前10名排行榜(倒序)
top10, _ := rdb.ZRevRangeWithScores(ctx, key, 0, 9).Result()
fmt.Println("🏆 排行榜前10:")
for i, item := range top10 {
fmt.Printf("第%d名:%s 分数:%.0f\n", i+1, item.Member, item.Score)
}
// 4. 查询个人排名
rank, _ := rdb.ZRevRank(ctx, key, "player_1001").Result()
fmt.Printf("你的排名:%d\n", rank+1)(2)延时任务队列
利用分数=时间戳,按时间自动排序,实现延时执行:
// 添加延时任务(5秒后执行)
delayTime := time.Now().Unix() + 5
rdb.ZAdd(ctx, "delay:task", redis.Z{Score: float64(delayTime), Member: "task_001"})
// 轮询查询到期任务
now := time.Now().Unix()
tasks, _ := rdb.ZRangeByScore(ctx, "delay:task", redis.ZRangeBy{
Min: "0",
Max: fmt.Sprintf("%d", now),
}).Result()(3)按分数筛选数据
// 筛选 80~100 分的用户
users, _ := rdb.ZRangeByScore(ctx, "score:user", redis.ZRangeBy{
Min: "80",
Max: "100",
}).Result()四、输出示例
✅ Redis连接成功
✅ ZADD成功:添加用户分数
✅ ZCARD成功:集合总元素数 = 4
✅ ZCOUNT成功:90-100分的用户数 = 3
✅ ZINCRBY成功:user01加分后分数 = 95
✅ ZRANGE成功:正序(低→高) = [user02 user04 user01 user03]
✅ ZRANGEWithScores成功:正序+分数
用户:user02,分数:85
用户:user04,分数:90
用户:user01,分数:95
用户:user03,分数:95
✅ ZRangeArgs成功:倒序(高→低) = [user01 user03 user04 user02]
✅ ZRANK成功:user03正序排名 = 3
✅ ZREVRANK成功:user03倒序排名(排行榜) = 1
✅ ZSCORE成功:user01当前分数 = 95
✅ ZREM成功:删除元素数量 = 1
✅ ZREMRANGEBYRANK成功:按排名删除数量 = 1
✅ ZREMRANGEBYSCORE成功:按分数删除数量 = 0
✅ 清空测试集合成功五、注意事项
- 大数据量性能
ZRange/ZRevRange性能极高,适合分页查询- 避免一次性查询全量超大集合,搭配
Limit使用
- 分数类型
- 支持整数/浮点数,内部以浮点数存储
- 成员唯一性
- 同 Key 下成员唯一,重复添加会覆盖分数
- 排名展示
- Redis 排名从 0 开始,前端展示需 +1
总结
- SortedSet = 有序 + 无重复 + 带分数,是 Redis 最实用的数据结构之一
- 核心操作:增(ZAdd)、删(ZRem)、查(ZRange/ZRank)、改(ZIncrBy)、统计(ZCount)
- 最佳实战场景:排行榜、延时队列、热度排序、范围筛选
- 新版统一使用
ZRangeArgs实现复杂排序/查询,代码更规范 - 错误处理必须判断
redis.Nil(元素不存在)
07 Redis 发布订阅
Redis 发布订阅是消息传输/消息通知的核心机制,由三个核心角色组成:
- 发布者:Redis 客户端,负责发送消息
- 订阅者:Redis 客户端,负责接收消息
- Channel(频道):Redis 服务端,消息的中转通道
工作流程:发布者向指定频道发送消息 → 所有订阅了该频道的订阅者实时接收消息。
1. Subscribe 普通订阅
作用:订阅固定名称的频道,精准接收该频道的消息。
提供两种接收消息方式:
- 遍历 Go Channel(推荐)
- 循环接收消息
// 1. 订阅固定频道:channel1
sub := rdb.Subscribe(ctx, "channel1")
// 方式一:遍历 Go Channel 接收消息(简洁常用)
for msg := range sub.Channel() {
fmt.Println("频道名:", msg.Channel) // 消息所属频道
fmt.Println("消息内容:", msg.Payload) // 消息正文
}
// 方式二:循环接收消息(可处理错误)
for {
msg, err := sub.ReceiveMessage(ctx)
if err != nil {
panic(err) // 接收失败处理
}
fmt.Println(msg.Channel, msg.Payload)
}2. Publish 发布消息
作用:向指定频道发送消息,所有订阅者都会收到。
// 参数:上下文、目标频道、消息内容
rdb.Publish(ctx, "channel1", "这是一条测试消息")3. PSubscribe 模式订阅
作用:支持通配符模式匹配订阅,一次性订阅多个符合规则的频道。
- 区别:
Subscribe订阅固定频道,PSubscribe支持模糊匹配
// 订阅所有以 ch_user_ 开头的频道(如 ch_user_1、ch_user_2 都能收到消息)
sub := rdb.PSubscribe(ctx, "ch_user_*")
// 接收消息方式和 Subscribe 完全一致
for msg := range sub.Channel() {
fmt.Println(msg.Channel, msg.Payload)
}4. Unsubscribe 取消订阅
作用:主动取消对指定频道的订阅,不再接收该频道消息。
// 先订阅频道
sub := rdb.Subscribe(ctx, "channel1")
// 取消订阅 channel1
sub.Unsubscribe(ctx, "channel1")5. PubSubNumSub 查询订阅者数量
作用:查看指定频道当前有多少个订阅者。
// 查询 channel_1 的订阅者数量
result, err := rdb.PubSubNumSub(ctx, "channel_1").Result()
if err != nil {
panic(err)
}
// 遍历结果:key=频道名,value=订阅者数量
for channel, count := range result {
fmt.Println("频道:", channel)
fmt.Println("订阅者数量:", count)
}核心总结
- Subscribe:订阅固定名称频道
- Publish:向频道发送消息
- PSubscribe:模式匹配订阅(通配符*)
- Unsubscribe:取消订阅
- PubSubNumSub:查询频道订阅者数量
08 事务处理
Redis 事务是将多个命令打包、一次性顺序执行的机制,解决多命令执行的原子性、隔离性问题,核心是命令批量执行 + 防并发干扰。
核心特性
Redis 事务有两个核心保证,同时有特殊机制需要注意:
- 隔离性 事务内的命令会序列化、按顺序执行,执行过程中不会被其他客户端的命令打断,完全独占执行权。 ✘ 注意:Redis 事务不支持回滚,若事务中某条命令执行失败(如语法错误),后续命令仍会正常执行,不会停止。
- 原子性 事务中的命令要么全部入队等待执行,要么全部不执行(入队阶段报错则直接放弃整个事务)。
1. TxPipeline 事务流水线(批量原子操作)
核心概念
- Pipeline:流水线,把多个命令打包一次性发送给 Redis,减少多次网络请求的开销。
- TxPipeline:带事务的流水线,自动包裹
MULTI(开启事务)和EXEC(执行事务),保证打包的命令原子执行。
适用场景
不需要依赖旧值计算新值,单纯批量执行命令:批量设置缓存、批量过期、简单计数增减。
执行逻辑
- 开启 TxPipeline,命令先存在本地队列,不发送给 Redis;
- 批量添加要执行的命令;
- 调用
Exec()一次性发送所有命令,Redis 原子执行。
// 1. 开启事务流水线
pipe := rdb.TxPipeline()
// 2. 命令入队(本地缓存,未执行)
// 计数器+1
incrCmd := pipe.Incr(ctx, "tx_pipeline_counter")
// 设置1小时过期
pipe.Expire(ctx, "tx_pipeline_counter", time.Hour)
// 3. 执行事务(发送MULTI+所有命令+EXEC)
_, err := pipe.Exec(ctx)
if err != nil {
panic(err)
}
// 4. 获取执行结果(必须在Exec之后调用)
fmt.Println("当前计数值:", incrCmd.Val())关键点
- 调用
Exec()前,命令只在本地,不会发给 Redis; - 命令结果必须在
Exec()执行成功后才能获取。
2. Watch 监听(乐观锁核心机制)
前置概念
-
乐观锁 假设并发冲突很少发生,不加锁,仅在最终更新时检查数据是否被修改:
- 若没被改 → 执行更新
- 若被改 → 放弃执行,重新尝试 对比:悲观锁(全程加锁阻塞),乐观锁无阻塞、高性能。
-
Watch 作用 监控一个/多个 Key,事务执行前如果被监控的 Key 被其他客户端修改,整个事务直接拒绝执行。
-
回调函数 传给
Watch的业务逻辑函数,Redis 框架会自动管理:- 监控 Key
- 执行业务逻辑
- 冲突时自动重试回调函数
适用场景
需要先查旧值 → 计算新值 → 再更新的场景:秒杀库存扣减、抢红包、余额变更、版本控制。
完整执行流程
- 开启 Watch,监听指定 Key;
- 在回调中读取最新值;
- 本地执行业务计算(如库存 -1);
- 打包更新命令,尝试提交事务;
- 校验:监控的 Key 没变化 → 执行成功;Key 被修改 → 事务失败,自动重新执行回调。
ctx := context.Background()
// 回调函数:封装事务业务逻辑
fn := func(tx *redis.Tx) error {
// 1. 读取最新值(事务上下文内查询)
currentNum, err := tx.Get(ctx, "stock").Int()
// 非空值异常直接返回
if err != nil && err != redis.Nil {
return err
}
// 2. 业务逻辑:库存扣减(依赖旧值计算新值)
if currentNum <= 0 {
return fmt.Errorf("库存不足")
}
newNum := currentNum - 1
// 3. 事务内批量执行更新
_, err = tx.Pipelined(ctx, func(pipe redis.Pipeliner) error {
pipe.Set(ctx, "stock", newNum, 0)
return nil
})
return err
}
// 4. 启动Watch:监听 stock key,自动执行/重试回调
err := rdb.Watch(ctx, fn, "stock")
if err != nil {
fmt.Println("事务执行失败:", err)
}总结对比
| 方式 | 核心机制 | 特点 | 适用场景 |
|---|---|---|---|
| TxPipeline | MULTI+EXEC 批量执行 | 命令本地打包,无锁,不依赖旧值 | 批量写入、简单计数、批量设置缓存 |
| Watch + 事务 | WATCH + 乐观锁 + 自动重试 | 监控 Key 变化,检查再更新,解决并发冲突 | 库存扣减、余额变更、抢单、CAS 操作 |
核心关键词说明
- Pipeline:命令打包发送,降低网络开销;
- 回调函数:Watch 的业务载体,冲突自动重试;
- Watch:监控 Key,防止事务执行中数据被篡改;
- 乐观锁:无阻塞并发控制,Watch 是 Redis 乐观锁的实现方式。
Redis 实战篇-验证码登录
一、业务场景分析
1.1 需求描述
用户通过手机号和验证码登录系统,需要实现以下功能:
- 发送验证码:用户输入手机号,系统生成验证码并发送到用户手机
- 验证码存储:将验证码存储到 Redis,设置过期时间
- 验证码验证:用户输入验证码,系统验证是否正确
- 防刷机制:防止用户频繁请求验证码
- 自动注册:验证码验证成功后,如果用户不存在则自动注册
- Token 生成:登录成功后生成 JWT Token 返回给前端
1.2 技术选型
为什么选择 Redis?
- 过期时间:验证码需要自动过期,Redis 支持精确的过期时间
- 高性能:验证码请求频繁,Redis 读写速度快(基于内存)
- 防刷机制:可以通过 TTL 查询剩余时间,防止频繁请求
- 分布式支持:多服务器环境下共享验证码
- 原子操作:Redis 的命令是原子的,无需担心并发问题
数据结构选择
- String:存储验证码,简单直接
- Key 格式:
dianping:user:login:phone:{手机号} - 过期时间:5 分钟(300 秒)
二、Redis + JWT vs Session 对比
2.1 Session 的局限性
传统 Session 机制
用户登录 → 服务器创建 Session → SessionID 存储在 Cookie 中
↓
Session 存储在服务器内存
↓
每次请求携带 SessionID
↓
服务器从内存中查找 SessionSession 的问题
- 服务器依赖:Session 存储在服务器内存,服务器重启后丢失
- 分布式困难:多服务器环境下,Session 无法共享
- 内存占用:大量用户登录时,占用大量服务器内存
- 扩展性差:水平扩展时,需要 Session 共享方案(如 Redis、数据库)
- 性能瓶颈:每次请求都需要从内存中查找 Session
2.2 Redis+ JWT 的优势
机制
用户登录 → 验证码存储在 Redis → 生成 JWT Token
↓
Token 返回给前端(存储在 localStorage)
↓
每次请求携带 Token
↓
服务器解析 Token,验证签名Redis 的优势
| 对比项 | Session | Redis + JWT |
|---|---|---|
| 存储位置 | 服务器内存 | Redis(内存数据库) |
| 分布式支持 | 需要额外方案 | 天然支持 |
| 服务器重启 | Session 丢失 | 数据持久化(RDB/AOF) |
| 内存占用 | 服务器内存 | 独立的 Redis 服务器 |
| 扩展性 | 需要共享方案 | 无缝扩展 |
| 性能 | 内存查找 | 高性能读写 |
| 过期时间 | 手动管理 | 自动过期 |
| 防刷机制 | 难以实现 | TTL 查询 |
2.3 为什么选择 JWT+redis 而不是 Session?
- 无状态设计:JWT Token 包含用户信息,服务器无需存储 Session
- 分布式友好:多服务器环境下,Token 可以在任何服务器上验证
- 高性能:Redis 读写速度极快,支持高并发
- 自动过期:验证码自动过期,无需手动清理
- 防刷机制:通过 TTL 查询剩余时间,防止频繁请求
- 持久化:Redis 支持数据持久化,服务器重启不丢失
三、JWT 知识详解
3.1 JWT 是什么?
JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在各方之间安全地传输信息。
JWT 结构
JWT 由三部分组成,用点(.)分隔:
Header.Payload.Signature示例
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
eyJ1c2VySWQiOjEsImV4cCI6MTYzNDU2Nzg5MCwiaWF0IjoxNjM0NTY0MjkwfQ.
SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c3.2 JWT 三部分详解
1. Header(头部)
{
"alg": "HS256",
"typ": "JWT"
}alg:签名算法(如 HS256、RS256)typ:令牌类型(通常是 JWT)
2. Payload(载荷)
{
"userId": 1,
"exp": 1634567890,
"iat": 1634564290
}userId:用户 ID(自定义字段)exp:过期时间(时间戳)iat:签发时间(时间戳)
3. Signature(签名)
HMACSHA256(
base64UrlEncode(header) + "." + base64UrlEncode(payload),
secret
)- 使用密钥(secret)对 Header 和 Payload 进行签名
- 防止 Token 被篡改
3.3 JWT 工作流程
┌─────────────────────────────────────────────────────────────┐
│ JWT 认证流程 │
└─────────────────────────────────────────────────────────────┘
1. 用户登录
↓
2. 服务器验证用户身份
↓
3. 服务器生成 JWT Token
- Header: {"alg": "HS256", "typ": "JWT"}
- Payload: {"userId": 1, "exp": 1634567890}
- Signature: 使用密钥签名
↓
4. 服务器返回 Token 给前端
↓
5. 前端存储 Token(localStorage)
↓
6. 前端每次请求携带 Token(Header: Authorization: Bearer {token})
↓
7. 服务器解析 Token
- 验证签名
- 检查过期时间
- 提取用户信息
↓
8. 服务器处理请求3.4 JWT 代码实现
文件:utils/jwt.go
package utils
import (
"errors"
"hm-dianping-go/config"
"time"
"github.com/golang-jwt/jwt/v4"
)
// Claims JWT声明
type Claims struct {
UserID uint `json:"userId"`
jwt.RegisteredClaims
}
// GenerateToken 生成JWT token
func GenerateToken(userID uint) (string, error) {
cfg := config.GetConfig()
if cfg == nil {
return "", errors.New("config not loaded")
}
claims := Claims{
UserID: userID,
RegisteredClaims: jwt.RegisteredClaims{
ExpiresAt: jwt.NewNumericDate(time.Now().Add(time.Duration(cfg.JWT.ExpireTime) * time.Second)),
IssuedAt: jwt.NewNumericDate(time.Now()),
NotBefore: jwt.NewNumericDate(time.Now()),
Issuer: "hm-dianping",
},
}
token := jwt.NewWithClaims(jwt.SigningMethodHS256, claims)
return token.SignedString([]byte(cfg.JWT.Secret))
}
// ParseToken 解析JWT token
func ParseToken(tokenString string) (*Claims, error) {
cfg := config.GetConfig()
if cfg == nil {
return nil, errors.New("config not loaded")
}
token, err := jwt.ParseWithClaims(tokenString, &Claims{}, func(token *jwt.Token) (interface{}, error) {
return []byte(cfg.JWT.Secret), nil
})
if err != nil {
return nil, err
}
if claims, ok := token.Claims.(*Claims); ok && token.Valid {
return claims, nil
}
return nil, errors.New("invalid token")
}JWT 中间件
// AuthMiddleware JWT认证中间件
func AuthMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
// 1. 获取 Token
token := c.GetHeader("Authorization")
if token == "" {
utils.ErrorResponse(c, http.StatusUnauthorized, "未登录")
c.Abort()
return
}
// 2. 去掉 "Bearer " 前缀
if strings.HasPrefix(token, "Bearer ") {
token = token[7:]
}
// 3. 解析 Token
claims, err := utils.ParseToken(token)
if err != nil {
utils.ErrorResponse(c, http.StatusUnauthorized, "Token无效或已过期")
c.Abort()
return
}
// 4. 将用户ID存入上下文
c.Set("userID", claims.UserID)
c.Next()
}
}3.5 JWT 优缺点
优点
- 无状态:服务器不需要存储 Session
- 跨域友好:适合前后端分离和移动端
- 性能好:无需查询数据库验证
- 可扩展:可以在 Payload 中存储自定义信息
- 标准化:基于开放标准,多语言支持
缺点
- Token 无法撤销:一旦签发,在过期前无法撤销
- Token 大小:比 SessionID 大,增加网络传输
- 敏感信息:不要在 Payload 中存储敏感信息(如密码)
- 过期时间:需要合理设置过期时间
四、验证码登录完整流程
4.1 发送验证码流程
前端 → Handler 层 → Service 层 → DAO 层 → Redis流程图
用户输入手机号: 13800138000
↓
前端调用: POST /api/user/code
↓
┌─────────────────────────────────────────────────────────────────┐
│ Handler 层: SendCode(c *gin.Context) │
│ - c.ShouldBindJSON(&req): 解析 JSON 请求体 │
│ - utils.IsPhoneValid(req.Phone): 验证手机号格式 │
│ - service.SendCode(req.Phone): 调用服务层 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Service 层: SendCode(phone string) │
│ - dao.CheckLoginCodeExists(phone): 检查验证码是否存在 │
│ - dao.GetLoginCodeTTL(phone): 获取剩余时间(防刷) │
│ - utils.GenerateRandomCode(6): 生成6位随机验证码 │
│ - dao.SetLoginCode(phone, code, 0): 存储到 Redis │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ DAO 层: SetLoginCode(phone, code, expiration) │
│ - Redis.Exists(ctx, key): 检查 key 是否存在 │
│ - Redis.TTL(ctx, key): 获取剩余时间 │
│ - Redis.Set(ctx, key, code, 300s): 存储验证码,5分钟过期 │
└─────────────────────────────────────────────────────────────────┘
↓
Redis: SET dianping:user:login:phone:13800138000 "123456" EX 300
↓
返回: "验证码发送成功"代码实现
1. Handler 层
// SendCode 发送验证码
func SendCode(c *gin.Context) {
var req struct {
Phone string `json:"phone" binding:"required"`
}
// 1. 使用 ShouldBindJSON 解析 JSON 请求体
if err := c.ShouldBindJSON(&req); err != nil {
utils.ErrorResponse(c, http.StatusBadRequest, "参数错误: "+err.Error())
return
}
// 2. 校验手机号格式
if !utils.IsPhoneValid(req.Phone) {
utils.ErrorResponse(c, http.StatusBadRequest, "手机号格式不正确")
return
}
// 3. 调用服务层发送验证码
result := service.SendCode(req.Phone)
// 4. 返回结果
utils.Response(c, result)
}使用的函数:
c.ShouldBindJSON(&req):Gin 框架函数,解析 JSON 请求体utils.IsPhoneValid():自定义函数,验证手机号格式service.SendCode():调用服务层函数utils.Response():自定义函数,返回响应
2. Service 层
// SendCode 发送验证码服务
func SendCode(phone string) *utils.Result {
// 1. 检查是否已存在未过期的验证码
exists, err := dao.CheckLoginCodeExists(phone)
if err != nil {
return utils.ErrorResult("系统错误,请稍后重试")
}
// 2. 防止频繁请求
if exists {
// 获取剩余时间
ttl, _ := dao.GetLoginCodeTTL(phone)
if ttl > 0 {
return utils.ErrorResult(fmt.Sprintf("验证码已发送,请%d秒后重试", int(ttl.Seconds())))
}
}
// 3. 生成6位随机验证码
code := utils.GenerateRandomCode(6)
// 4. 将验证码存储到Redis,设置5分钟过期
err = dao.SetLoginCode(phone, code, 0) // 0表示使用默认过期时间
if err != nil {
return utils.ErrorResult("验证码发送失败,请稍后重试")
}
// 5. TODO: 实现发送短信验证码功能
fmt.Printf("[开发模式] 手机号 %s 的验证码是: %s\n", phone, code)
return utils.SuccessResult("验证码发送成功")
}使用的函数:
dao.CheckLoginCodeExists():检查验证码是否存在dao.GetLoginCodeTTL():获取验证码剩余时间utils.GenerateRandomCode():生成随机验证码dao.SetLoginCode():存储验证码到 Redis
3. DAO 层
package dao
import (
"context"
"fmt"
"log"
"time"
"github.com/go-redis/redis/v8"
)
// Redis验证码相关常量
const (
// LoginCodePrefix 登录验证码Redis key前缀
LoginCodePrefix = "dianping:user:login:phone:"
// DefaultCodeExpiration 默认验证码过期时间(5分钟)
DefaultCodeExpiration = 5 * time.Minute
)
// CheckLoginCodeExists 检查登录验证码是否存在
func CheckLoginCodeExists(phone string) (bool, error) {
if Redis == nil {
return false, fmt.Errorf("Redis client not initialized")
}
key := LoginCodePrefix + phone
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 使用 Redis EXISTS 命令
exists, err := Redis.Exists(ctx, key).Result()
if err != nil {
return false, fmt.Errorf("failed to check login code existence for phone %s: %w", phone, err)
}
return exists > 0, nil
}
// GetLoginCodeTTL 获取登录验证码的剩余过期时间
func GetLoginCodeTTL(phone string) (time.Duration, error) {
if Redis == nil {
return 0, fmt.Errorf("Redis client not initialized")
}
key := LoginCodePrefix + phone
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 使用 Redis TTL 命令
ttl, err := Redis.TTL(ctx, key).Result()
if err != nil {
return 0, fmt.Errorf("failed to get TTL for login code of phone %s: %w", phone, err)
}
return ttl, nil
}
// SetLoginCode 设置登录验证码到Redis
func SetLoginCode(phone, code string, expiration time.Duration) error {
if Redis == nil {
return fmt.Errorf("Redis client not initialized")
}
if expiration == 0 {
expiration = DefaultCodeExpiration
}
key := LoginCodePrefix + phone
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 使用 Redis SET 命令,设置过期时间
err := Redis.Set(ctx, key, code, expiration).Err()
if err != nil {
return fmt.Errorf("failed to set login code for phone %s: %w", phone, err)
}
log.Printf("Login code set for phone: %s, expiration: %v", phone, expiration)
return nil
}使用的 Redis 函数:
Redis.Exists(ctx, key):检查 key 是否存在Redis.TTL(ctx, key):获取 key 的剩余过期时间Redis.Set(ctx, key, value, expiration):设置 key-value,并设置过期时间
4.2 验证码登录流程
前端 → Handler 层 → Service 层 → DAO 层 → Redis流程图
用户输入: 手机号 13800138000, 验证码 123456
↓
前端调用: POST /api/user/login
↓
┌─────────────────────────────────────────────────────────────────┐
│ Handler 层: UserLogin(c *gin.Context) │
│ - c.ShouldBindJSON(&req): 解析 JSON 请求体 │
│ - utils.IsPhoneValid(req.Phone): 验证手机号格式 │
│ - service.UserLogin(phone, code, password): 调用服务层 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Service 层: UserLogin(phone, code, password) │
│ - 判断使用验证码登录还是密码登录 │
│ - loginWithCode(phone, code): 验证码登录 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Service 层: loginWithCode(phone, code) │
│ - dao.GetLoginCode(phone): 从 Redis 获取验证码 │
│ - 验证验证码是否正确 │
│ - dao.DeleteLoginCode(phone): 删除验证码 │
│ - dao.GetUserByPhone(phone): 查询用户 │
│ - dao.CreateUser(&newUser): 不存在则自动注册 │
│ - utils.GenerateToken(user.ID): 生成 JWT Token │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ DAO 层: GetLoginCode(phone) / DeleteLoginCode(phone) │
│ - Redis.Get(ctx, key): 获取验证码 │
│ - Redis.Del(ctx, key): 删除验证码 │
└─────────────────────────────────────────────────────────────────┘
↓
Redis: GET dianping:user:login:phone:13800138000
Redis: DEL dianping:user:login:phone:13800138000
↓
返回: {token: "xxx", user: {...}}代码实现
1. Handler 层
// UserLogin 用户登录
func UserLogin(c *gin.Context) {
var req struct {
Phone string `json:"phone" binding:"required"`
Code string `json:"code"`
Password string `json:"password"`
}
// 1. 使用 ShouldBindJSON 解析 JSON 请求体
if err := c.ShouldBindJSON(&req); err != nil {
utils.ErrorResponse(c, http.StatusBadRequest, "参数错误: "+err.Error())
return
}
// 2. 校验手机号格式
if ok := utils.IsPhoneValid(req.Phone); !ok {
utils.ErrorResponse(c, http.StatusBadRequest, "手机号格式不正确")
return
}
// 3. 调用服务层登录
result := service.UserLogin(req.Phone, req.Code, req.Password)
// 4. 返回结果
utils.Response(c, result)
}使用的函数:
c.ShouldBindJSON(&req):Gin 框架函数,解析 JSON 请求体utils.IsPhoneValid():验证手机号格式service.UserLogin():调用服务层登录函数utils.Response():返回响应
2. Service 层
// UserLogin 用户登录服务
func UserLogin(phone, code, password string) *utils.Result {
// 判断使用验证码登录还是密码登录
if code != "" {
return loginWithCode(phone, code) // 验证码登录
}
if password != "" {
return loginWithPassword(phone, password) // 密码登录
}
return utils.ErrorResult("请提供验证码或密码")
}
// loginWithCode 使用验证码登录
func loginWithCode(phone, code string) *utils.Result {
// 1. 从 Redis 获取验证码
storedCode, err := dao.GetLoginCode(phone)
if err != nil {
return utils.ErrorResult("验证码已过期或不存在,请重新获取")
}
// 2. 验证验证码
if storedCode != code {
return utils.ErrorResult("验证码错误")
}
// 3. 删除验证码(防止重复使用)
_ = dao.DeleteLoginCode(phone)
// 4. 查询用户,不存在则自动注册
user, err := dao.GetUserByPhone(phone)
if err != nil {
newUser := models.User{
Phone: phone,
NickName: "用户" + phone[7:], // 使用手机号后4位作为昵称
}
if err = dao.CreateUser(&newUser); err != nil {
return utils.ErrorResult("登录失败")
}
user = &newUser
}
// 5. 生成 JWT Token
token, err := utils.GenerateToken(user.ID)
if err != nil {
return utils.ErrorResult("登录失败")
}
// 6. 返回 Token 和用户信息
return utils.SuccessResultWithData(map[string]interface{}{
"token": token,
"user": map[string]interface{}{
"id": user.ID,
"phone": user.Phone,
"nickName": user.NickName,
"icon": user.Icon,
},
})
}使用的函数:
dao.GetLoginCode():从 Redis 获取验证码dao.DeleteLoginCode():删除 Redis 中的验证码dao.GetUserByPhone():从数据库查询用户dao.CreateUser():创建新用户utils.GenerateToken():生成 JWT Token
3. DAO 层
// GetLoginCode 从Redis获取登录验证码
func GetLoginCode(phone string) (string, error) {
if Redis == nil {
return "", fmt.Errorf("Redis client not initialized")
}
key := LoginCodePrefix + phone
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 使用 Redis GET 命令
code, err := Redis.Get(ctx, key).Result()
if err == redis.Nil {
return "", fmt.Errorf("login code not found or expired for phone: %s", phone)
}
if err != nil {
return "", fmt.Errorf("failed to get login code for phone %s: %w", phone, err)
}
return code, nil
}
// DeleteLoginCode 删除Redis中的登录验证码
func DeleteLoginCode(phone string) error {
if Redis == nil {
return fmt.Errorf("Redis client not initialized")
}
key := LoginCodePrefix + phone
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 使用 Redis DEL 命令
err := Redis.Del(ctx, key).Err()
if err != nil {
return fmt.Errorf("failed to delete login code for phone %s: %w", phone, err)
}
log.Printf("Login code deleted for phone: %s", phone)
return nil
}使用的 Redis 函数:
Redis.Get(ctx, key):获取 key 的值Redis.Del(ctx, key):删除 key
五、Redis 在验证码登录中的应用
5.1 Redis 的核心作用
| 功能 | Redis 命令 | 作用 |
|---|---|---|
| 存储验证码 | SET key value EX seconds | 存储验证码并设置过期时间 |
| 获取验证码 | GET key | 获取验证码进行验证 |
| 删除验证码 | DEL key | 验证成功后删除验证码 |
| 检查是否存在 | EXISTS key | 检查验证码是否存在(防刷) |
| 获取剩余时间 | TTL key | 获取验证码剩余时间(防刷) |
5.2 Redis 命令详解
1. SET 命令(存储验证码)
# 语法
SET key value [EX seconds] [PX milliseconds] [NX|XX]
# 示例
SET dianping:user:login:phone:13800138000 "123456" EX 300参数说明:
EX seconds:设置过期时间(秒)PX milliseconds:设置过期时间(毫秒)NX:只在 key 不存在时设置XX:只在 key 存在时设置
应用场景:
- 存储验证码,5 分钟后自动过期
- 防止验证码被重复使用
2. GET 命令(获取验证码)
# 语法
GET key
# 示例
GET dianping:user:login:phone:13800138000
# 返回: "123456"应用场景:
- 获取存储的验证码
- 验证用户输入的验证码是否正确
3. DEL 命令(删除验证码)
# 语法
DEL key [key ...]
# 示例
DEL dianping:user:login:phone:13800138000应用场景:
- 验证成功后立即删除验证码
- 防止验证码被重复使用
4. EXISTS 命令(检查是否存在)
# 语法
EXISTS key [key ...]
# 示例
EXISTS dianping:user:login:phone:13800138000
# 返回: (integer) 1 (存在) 或 0 (不存在)应用场景:
- 检查验证码是否存在
- 实现防刷机制
5. TTL 命令(获取剩余时间)
# 语法
TTL key
# 示例
TTL dianping:user:login:phone:13800138000
# 返回: (integer) 250 (剩余250秒)返回值:
- 正数:剩余秒数
- -1:永久存在(没有设置过期时间)
- -2:key 不存在(已过期或被删除)
应用场景:
- 获取验证码剩余时间
- 实现防刷机制(提示用户等待剩余时间)
六、Key 命名规范
6.1 推荐格式
{业务}:{模块}:{唯一标识}6.2 验证码 Key 格式
dianping:user:login:phone:{手机号}6.3 示例
dianping:user:login:phone:13800138000
dianping:user:login:phone:13900139000
dianping:user:login:phone:186001860006.4 命名规范的优势
- 清晰易懂:通过 key 名称就能知道数据的用途
- 便于管理:可以批量操作某个业务的数据
- 避免冲突:不同业务使用不同的前缀
- 便于监控:可以按业务维度监控 Redis 使用情况
七、完整流程总结
7.1 发送验证码流程
用户输入手机号
↓
前端调用: POST /api/user/code
↓
Handler 层: SendCode()
- 解析 JSON 请求体
- 验证手机号格式
- 调用服务层
↓
Service 层: SendCode(phone)
- 检查验证码是否存在(防刷)
- 获取剩余时间(防刷)
- 生成随机验证码
- 存储到 Redis
↓
DAO 层: SetLoginCode()
- Redis.SET(key, code, 300s)
↓
Redis: SET dianping:user:login:phone:13800138000 "123456" EX 300
↓
返回: "验证码发送成功"7.2 验证码登录流程
用户输入手机号和验证码
↓
前端调用: POST /api/user/login
↓
Handler 层: UserLogin()
- 解析 JSON 请求体
- 验证手机号格式
- 调用服务层
↓
Service 层: UserLogin(phone, code)
- 判断登录方式
- loginWithCode(phone, code)
↓
Service 层: loginWithCode()
- 从 Redis 获取验证码
- 验证验证码
- 删除验证码
- 查询用户
- 自动注册(不存在)
- 生成 JWT Token
↓
DAO 层: GetLoginCode() / DeleteLoginCode()
- Redis.GET(key)
- Redis.DEL(key)
↓
Redis: GET dianping:user:login:phone:13800138000
Redis: DEL dianping:user:login:phone:13800138000
↓
返回: {token: "xxx", user: {...}}7.3 JWT 认证流程
前端携带 Token 请求
↓
中间件: AuthMiddleware()
- 获取 Authorization Header
- 去掉 "Bearer " 前缀
- 解析 Token
- 验证签名
- 检查过期时间
- 提取用户 ID
- 存入上下文
↓
Handler 层处理请求
- 从上下文获取用户 ID
- 执行业务逻辑
↓
返回结果八、核心要点
8.1 Redis 核心要点
- String 数据结构:存储验证码,支持过期时间
- 防刷机制:通过 TTL 查询剩余时间
- 验证后删除:防止验证码重复使用
- 自动过期:验证码 5 分钟后自动过期
- 高性能:基于内存,读写速度快
- 分布式支持:多服务器环境下共享验证码
8.2 JWT 核心要点
- 无状态设计:服务器无需存储 Session
- Token 包含信息:Payload 中包含用户 ID
- 签名验证:防止 Token 被篡改
- 过期时间:Token 自动过期
- 跨域友好:适合前后端分离和移动端
8.3 架构设计要点
- 分层架构:Handler → Service → DAO,职责清晰
- 错误处理:区分验证码过期和验证码错误
- 自动注册:验证成功后自动创建用户
- 防刷机制:防止用户频繁请求验证码
- Key 命名规范:使用冒号分隔的层级结构
九、最佳实践
9.1 Redis 最佳实践
- Key 命名规范:使用冒号分隔的层级结构
- 过期时间设置:验证码 5 分钟过期
- 防刷机制:检查验证码是否存在和剩余时间
- 验证后删除:防止验证码重复使用
- 错误处理:区分验证码过期和验证码错误
- 连接池配置:合理配置连接池大小
- 监控和告警:监控 Redis 性能和内存占用
9.2 JWT 最佳实践
- 密钥安全:密钥不要泄露,定期更换
- 过期时间:合理设置过期时间(如 7 天)
- Payload 安全:不要在 Payload 中存储敏感信息
- Token 刷新:实现 Token 刷新机制
- HTTPS 传输:使用 HTTPS 传输 Token
- 存储位置:前端存储在 localStorage 或 sessionStorage
9.3 安全建议
- 验证码复杂度:使用 6 位数字验证码
- 验证码有效期:5 分钟过期
- 防刷机制:限制单个手机号请求频率
- IP 限流:限制单个 IP 请求频率
- 短信发送:集成短信服务商 API
- 日志记录:记录验证码发送和验证日志
十、总结
10.1 Redis 在验证码登录中的价值
- 高性能:基于内存,读写速度快
- 自动过期:验证码自动过期,无需手动清理
- 防刷机制:通过 TTL 查询剩余时间
- 分布式支持:多服务器环境下共享验证码
- 原子操作:Redis 的命令是原子的,无需担心并发问题
10.2 Redis vs Session
| 对比项 | Session | Redis + JWT |
|---|---|---|
| 存储位置 | 服务器内存 | Redis(内存数据库) |
| 分布式支持 | 需要额外方案 | 天然支持 |
| 服务器重启 | Session 丢失 | 数据持久化 |
| 内存占用 | 服务器内存 | 独立的 Redis 服务器 |
| 扩展性 | 需要共享方案 | 无缝扩展 |
| 性能 | 内存查找 | 高性能读写 |
| 过期时间 | 手动管理 | 自动过期 |
| 防刷机制 | 难以实现 | TTL 查询 |
10.3 JWT 的优势
- 无状态:服务器不需要存储 Session
- 跨域友好:适合前后端分离和移动端
- 性能好:无需查询数据库验证
- 可扩展:可以在 Payload 中存储自定义信息
- 标准化:基于开放标准,多语言支持
10.4 完整流程回顾
- 发送验证码:前端 → Handler → Service → DAO → Redis
- 验证码登录:前端 → Handler → Service → DAO → Redis + JWT
- JWT 认证:前端 → 中间件 → Handler
- 业务处理:Handler → Service → DAO → Database
十一、附录
11.1 Redis 命令速查表
| 命令 | 作用 | 示例 |
|---|---|---|
| SET | 设置键值对 | SET key value EX 300 |
| GET | 获取值 | GET key |
| DEL | 删除键 | DEL key |
| EXISTS | 检查键是否存在 | EXISTS key |
| TTL | 获取剩余时间 | TTL key |
| EXPIRE | 设置过期时间 | EXPIRE key 300 |
11.2 项目结构
hm-dianping-go/
├── handler/
│ └── user_handler.go # Handler 层
├── service/
│ └── user_service.go # Service 层
├── dao/
│ └── verification_code.go # DAO 层
└── utils/
└── jwt.go # JWT 工具Redis 实战篇-商户查询缓存
一、什么是缓存
1.1 缓存的定义
缓存(Cache)是一种高速数据存储层,位于应用程序和永久数据存储(如数据库)之间,用于存储频繁访问的数据,以减少对永久数据存储的访问次数,从而提高系统性能。
1.2 缓存的工作原理
┌─────────────────────────────────────────────────────────────┐
│ 缓存工作流程 │
└─────────────────────────────────────────────────────────────┘
用户请求
↓
┌─────────────────────────────────────────────────────────────┐
│ 1. 查询缓存 │
│ - 缓存命中 → 直接返回数据(速度快) │
│ - 缓存未命中 → 继续下一步 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 2. 查询数据库 │
│ - 从数据库获取数据 │
│ - 数据库查询速度慢(磁盘IO) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 3. 写入缓存 │
│ - 将数据写入缓存 │
│ - 设置过期时间 │
└─────────────────────────────────────────────────────────────┘
↓
返回数据给用户1.3 缓存的优势
| 优势 | 说明 |
|---|---|
| 高性能 | Redis 基于内存,读写速度比数据库快 10-100 倍 |
| 低延迟 | 减少数据库访问,降低响应时间 |
| 高并发 | 缓存可以承受更高的并发访问 |
| 减轻数据库压力 | 减少数据库查询次数,降低数据库负载 |
| 提升用户体验 | 页面加载更快,用户体验更好 |
1.4 缓存的适用场景
- 读多写少:数据读取频率远高于写入频率
- 热点数据:某些数据被频繁访问(如热门商品、热门店铺)
- 计算结果:复杂计算的结果可以缓存
- 静态数据:不经常变化的数据(如商品分类、店铺信息)
二、为什么需要商户缓存
2.1 商户查询的特点
业务场景
- 高频访问:用户频繁浏览店铺信息
- 读多写少:店铺信息更新频率低,查询频率高
- 热点数据:热门店铺会被大量用户访问
- 关联查询:店铺信息可能关联其他数据(如店铺类型、优惠券)
性能瓶颈
无缓存的情况:
1000 用户同时查询店铺 → 1000 次数据库查询 → 数据库压力大 → 响应慢
有缓存的情况:
1000 用户同时查询店铺 → 1 次数据库查询(缓存未命中) + 999 次缓存查询 → 数据库压力小 → 响应快2.2 商户缓存的价值
| 指标 | 无缓存 | 有缓存 | 提升 |
|---|---|---|---|
| 响应时间 | 100-500ms | 1-10ms | 10-100 倍 |
| 数据库查询 | 1000 次/秒 | 10 次/秒 | 减少 99% |
| 并发能力 | 100 QPS | 10000 QPS | 100 倍 |
| 数据库 CPU | 80% | 10% | 降低 70% |
2.3 商户数据特点
相对稳定
- 店铺基本信息(名称、地址、电话)不经常变化
- 店铺类型、评分等数据更新频率低
- 适合缓存,过期时间可以设置较长(如 1 小时)
关联数据多
- 店铺详情可能包含:店铺信息、店铺类型、优惠券列表
- 一次性查询多个表,数据库压力大
- 缓存可以缓存完整的店铺信息,减少数据库查询
三、商户缓存实现
3.1 缓存数据结构选择
String 类型:存储店铺详情
为什么选择 String?
- 简单直接:店铺信息可以序列化为 JSON 字符串
- 易于操作:GET、SET、DEL 命令简单高效
- 过期时间:支持精确的过期时间
- 内存占用:相比 Hash 类型,String 类型内存占用更小
GEO 类型:存储店铺位置
为什么选择 GEO?
- 地理位置查询:支持附近店铺查询
- 高效计算:Redis 内置地理位置计算
- 距离排序:可以按距离排序返回结果
- 范围查询:支持半径范围内的查询
3.2 Redis Key 设计
店铺详情缓存
cache:shop:description:{shopId}示例:
cache:shop:description:1:ID 为 1 的店铺详情cache:shop:description:100:ID 为 100 的店铺详情
店铺位置缓存
cache:shop:location:{typeId}示例:
cache:shop:location:1:类型为 1 的店铺位置信息cache:shop:location:2:类型为 2 的店铺位置信息
3.3 缓存过期时间
| 数据类型 | 过期时间 | 原因 |
|---|---|---|
| 店铺详情 | 1 小时 | 店铺信息相对稳定,1 小时内变化概率低 |
| 店铺位置 | 永久 | 店铺位置不经常变化,手动更新 |
四、商户查询缓存流程
4.1 完整查询流程
用户查询商铺: GET /api/shop/1
↓
┌─────────────────────────────────────────────────────────────┐
│ 1. 布隆过滤器检查(防止缓存穿透) │
│ - 检查商铺ID是否存在 │
│ - 不存在 → 直接返回"商铺不存在" │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 2. 查询缓存 │
│ - GET cache:shop:description:1 │
│ - 缓存命中 → 直接返回商铺信息 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 3. 缓存未命中,获取互斥锁(防止缓存击穿) │
│ - 尝试获取锁: lock:shop:1 │
│ - 获取失败 → 等待50ms后重新查询缓存 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 4. 双重检查缓存 │
│ - 再次查询缓存 │
│ - 缓存命中 → 直接返回商铺信息 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 5. 查询数据库 │
│ - SELECT * FROM tb_shop WHERE id = 1 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 6. 设置缓存 │
│ - SET cache:shop:description:1 "{...}" EX 3600 │
│ - 过期时间: 1小时 │
└─────────────────────────────────────────────────────────────┘
↓
返回商铺信息4.2 代码实现
Service 层:商铺查询(带完整缓存逻辑)
// GetShopById 根据ID获取商铺
func GetShopById(ctx context.Context, id uint) *utils.Result {
// 1. 布隆过滤器检查,防止缓存穿透
flag, err := utils.CheckIDExistsWithRedis(ctx, dao.Redis, "shop", id)
if err != nil {
log.Fatalf("检查布隆过滤器失败: %v", err)
}
if !flag {
// 布隆过滤器判断商铺不存在,直接返回
return utils.ErrorResult("商铺不存在")
}
// 2. 先从缓存查询
shop, err := dao.GetShopCacheById(ctx, dao.Redis, id)
if err == nil && shop != nil {
// 缓存命中,直接返回
return utils.SuccessResultWithData(shop)
}
// 3. 缓存未命中,使用互斥锁防止缓存击穿
lockKey := fmt.Sprintf("lock:shop:%d", id)
// 尝试获取锁
if !utils.TryLock(ctx, dao.Redis, lockKey) {
// 获取锁失败,等待一段时间后重新查询缓存
time.Sleep(50 * time.Millisecond)
shop, err = dao.GetShopCacheById(ctx, dao.Redis, id)
if err == nil && shop != nil {
return utils.SuccessResultWithData(shop)
}
// 如果缓存仍然没有数据,返回错误
return utils.ErrorResult("服务繁忙,请稍后重试")
}
// 获取锁成功,确保释放锁
defer utils.UnLock(ctx, dao.Redis, lockKey)
// 再次检查缓存(双重检查锁定模式)
shop, err = dao.GetShopCacheById(ctx, dao.Redis, id)
if err == nil && shop != nil {
// 缓存命中,直接返回
return utils.SuccessResultWithData(shop)
}
// 4. 查询数据库
shop, err = dao.GetShopById(ctx, dao.DB, id)
if err != nil {
// 数据库查询失败
return utils.ErrorResult("查询失败: " + err.Error())
}
// 5. 设置缓存
err = dao.SetShopCacheById(ctx, dao.Redis, id, shop)
if err != nil {
// 缓存设置失败,记录日志但不影响返回结果
log.Printf("设置缓存失败: %v", err)
}
// 6. 返回结果
return utils.SuccessResultWithData(shop)
}DAO 层:缓存操作函数
文件:dao/shop.go
const (
ShopCache = "cache:shop:description:"
ShopLocationCache = "cache:shop:location:"
)
// GetShopCacheById 从缓存获取商铺信息
func GetShopCacheById(ctx context.Context, rds *redis.Client, shopId uint) (*models.Shop, error) {
key := ShopCache + strconv.Itoa(int(shopId))
result := rds.Get(ctx, key)
// 1. 先判断 Redis 是否返回错误
if result.Err() != nil {
// 区分"缓存未命中"和"其他错误"
if errors.Is(result.Err(), redis.Nil) {
return nil, nil // 缓存未命中:返回 nil, nil
}
// 其他错误(如连接失败):返回 nil + 具体错误
return nil, fmt.Errorf("redis query failed: %w", result.Err())
}
// 2. Redis 键存在,获取JSON字符串
jsonStr, err := result.Result()
if err != nil {
return nil, fmt.Errorf("failed to get cache result: %w", err)
}
// 3. JSON反序列化
shop := &models.Shop{}
if err := json.Unmarshal([]byte(jsonStr), shop); err != nil {
// 缓存数据损坏:返回 nil + 反序列化错误
return nil, fmt.Errorf("cache data unmarshal failed: %w", err)
}
// 4. 反序列化成功:返回有效 shop 对象
return shop, nil
}
// SetShopCacheById 设置商铺缓存
func SetShopCacheById(ctx context.Context, rds *redis.Client, shopId uint, shop *models.Shop) error {
// JSON序列化
jsonData, err := json.Marshal(shop)
if err != nil {
return fmt.Errorf("failed to marshal shop to json: %w", err)
}
// 存储到Redis,过期时间1小时
err = rds.Set(ctx, ShopCache+strconv.Itoa(int(shopId)), jsonData, time.Hour).Err()
if err != nil {
return fmt.Errorf("failed to set cache: %w", err)
}
return nil
}
// DelShopCacheById 删除商铺缓存
func DelShopCacheById(ctx context.Context, rds *redis.Client, shopId uint) error {
err := rds.Del(ctx, ShopCache+strconv.Itoa(int(shopId))).Err()
if err != nil {
return err
}
return nil
}五、缓存更新策略
5.1 缓存更新策略对比
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Cache Aside | 实现简单,数据一致性好 | 每次更新都要删除缓存 | 通用场景 |
| Write Through | 缓存和数据库同步更新 | 写入性能差 | 读多写少 |
| Write Behind | 写入性能高 | 数据一致性差 | 写多读少 |
| Refresh Ahead | 缓存命中率高 | 实现复杂 | 热点数据 |
5.2 Cache Aside 策略(推荐)
策略说明
Cache Aside 是最常用的缓存更新策略,也称为 Lazy Loading。
更新流程
更新商铺信息
↓
┌─────────────────────────────────────────────────────────────┐
│ 1. 先更新数据库 │
│ - UPDATE tb_shop SET name = '新名称' WHERE id = 1 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 2. 提交事务 │
│ - 确保数据库更新成功 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 3. 删除缓存 │
│ - DEL cache:shop:description:1 │
│ - 下次查询时重新加载缓存 │
└─────────────────────────────────────────────────────────────┘为什么选择 Cache Aside?
- 实现简单:不需要复杂的同步逻辑
- 数据一致性好:先更新数据库,再删除缓存
- 性能好:不需要每次更新都写缓存
- 容错性强:缓存删除失败不影响业务
为什么不先删缓存再更数据库?
这是一个经典的并发问题,会导致数据不一致。
问题场景:
1. 线程 A 删除缓存
2. 线程 B 查询数据(缓存未命中,读数据库,得到旧数据)
3. 线程 B 将旧数据写入缓存
4. 线程 A 更新数据库(新数据)
结果:缓存里永远是旧数据 ❌正确做法:先更新数据库,再删除缓存。这样即使删除缓存失败,数据库也是新数据,下次查询时会重新加载。
为什么删除而不是更新缓存?
原因 1:避免并发问题
两个线程同时更新同一数据时,可能出现:数据库是 B(正确),但缓存是 A(错误),数据不一致。
原因 2:节省资源
如果短时间内多次更新,但期间无人查询,更新缓存就是浪费。删除缓存,等下次有人查询时再加载(懒加载)。
对比总结:
| 方式 | 并发问题 | 资源浪费 | 性能 | 一致性 |
|---|---|---|---|---|
| 更新缓存 | ❌ 可能不一致 | ❌ 浪费 | 慢 | 差 |
| 删除缓存 | ✅ 不会不一致 | ✅ 懒加载 | 快 | 好 |
5.3 代码实现
Service 层:更新商铺(删除缓存)
// UpdateShopById 根据ID更新商铺
func UpdateShopById(ctx context.Context, shop *models.Shop) *utils.Result {
// 0. 启动事务
tx := dao.DB.Begin()
defer func() { // 捕获异常
if r := recover(); r != nil {
tx.Rollback()
}
}()
// 1. 更新数据库
err := dao.UpdateShop(ctx, tx, shop)
// 2. 更新失败
if err != nil {
tx.Rollback()
return utils.ErrorResult("更新失败: " + err.Error())
}
// 3. 提交事务
if err = tx.Commit().Error; err != nil {
tx.Rollback()
return utils.ErrorResult("更新失败: " + err.Error())
}
// 4. 事务成功后删除缓存(最终一致性)
err = dao.DelShopCacheById(ctx, dao.Redis, shop.ID)
if err != nil {
// 记录日志但不影响业务结果
log.Printf("警告: 删除缓存失败,商铺ID=%d, 错误=%v", shop.ID, err)
}
// 5. 返回结果
return utils.SuccessResult("更新成功")
}六、数据库与缓存双写一致性
6.1 一致性问题
什么是数据一致性?
数据一致性是指数据库和缓存中的数据保持同步,避免出现数据不一致的情况。
不一致的场景
场景1:更新数据库成功,删除缓存失败
数据库: 店铺名称 = "新名称"
缓存: 店铺名称 = "旧名称" ❌ 不一致
场景2:并发更新
线程1: 更新数据库 → 删除缓存
线程2: 更新数据库 → 删除缓存
如果线程2先删除缓存,线程1后删除缓存,最终一致
但如果线程1先删除缓存,线程2后删除缓存,最终也一致
场景3:缓存过期
数据库: 店铺名称 = "新名称"
缓存: 已过期,下次查询时重新加载 ✓ 最终一致6.2 保证一致性的策略
策略 1:先更新数据库,再删除缓存(推荐)
// 1. 更新数据库
err := dao.UpdateShop(ctx, tx, shop)
if err != nil {
tx.Rollback()
return err
}
// 2. 提交事务
tx.Commit()
// 3. 删除缓存
dao.DelShopCacheById(ctx, rds, shop.ID)优点:
- 实现简单
- 数据一致性好
- 容错性强
缺点:
- 删除缓存失败时,数据可能不一致
- 需要监控缓存删除失败的情况
策略 2:先删除缓存,再更新数据库
// 1. 删除缓存
dao.DelShopCacheById(ctx, rds, shop.ID)
// 2. 更新数据库
err := dao.UpdateShop(ctx, tx, shop)
if err != nil {
tx.Rollback()
return err
}
// 3. 提交事务
tx.Commit()优点:
- 避免脏数据(旧数据被查询到)
缺点:
- 并发时可能出现不一致
- 实现复杂
策略 3:延迟双删
// 1. 先删除缓存
dao.DelShopCacheById(ctx, rds, shop.ID)
// 2. 更新数据库
err := dao.UpdateShop(ctx, tx, shop)
if err != nil {
tx.Rollback()
return err
}
tx.Commit()
// 3. 延迟删除缓存(异步)
go func() {
time.Sleep(1 * time.Second)
dao.DelShopCacheById(ctx, rds, shop.ID)
}()优点:
- 解决并发问题
- 数据一致性好
缺点:
- 实现复杂
- 延迟删除可能影响性能
6.3 最终一致性 vs 强一致性
| 一致性类型 | 说明 | 实现难度 | 适用场景 |
|---|---|---|---|
| 强一致性 | 数据库和缓存实时一致 | 高 | 金融、支付等关键业务 |
| 最终一致性 | 数据库和缓存在短时间内一致 | 低 | 一般业务(如店铺信息) |
推荐:对于商户信息这类非关键业务,使用最终一致性即可。
七、缓存三大问题及解决方案
7.1 缓存穿透
什么是缓存穿透?
缓存穿透是指查询一个不存在的数据,由于缓存中没有数据,每次请求都会穿透到数据库。
场景示例
恶意请求: 查询ID为999999的商铺(不存在)
↓
查询缓存: cache:shop:description:999999 → 未命中
↓
查询数据库: SELECT * FROM tb_shop WHERE id = 999999 → 未找到
↓
返回: "商铺不存在"
↓
重复请求1000次 → 数据库压力增大解决方案 1:布隆过滤器(推荐)
原理: 布隆过滤器是一种空间效率极高的概率型数据结构,用于判断一个元素是否在一个集合中。
特点:
- 空间效率高:比 Hash 表节省 90% 以上空间
- 查询速度快:O(1) 时间复杂度
- 有误判率:可能误判存在,但不会误判不存在
原理:
- 布隆过滤器通过多个哈希函数将元素映射到一个固定大小的位数组中。
- 当查询一个元素是否存在,通过多个哈希函数检查位数组中对应位置的位是否为 1。
- 如果所有位都为 1,则该元素可能存在于集合中;如果有一个位为 0,则该元素不存在于集合中。
实现:
// 1. 初始化布隆过滤器
bf := utils.CreateShopBloomFilter(dao.Redis)
// 2. 添加所有商铺ID到布隆过滤器
shopIds, _ := dao.GetAllShopIDs(ctx, dao.DB)
bf.AddIDs(ctx, shopIds)
// 3. 查询时先检查布隆过滤器
flag, _ := bf.ExistsID(ctx, shopId)
if !flag {
return utils.ErrorResult("商铺不存在")
}// BloomFilter 布隆过滤器
type BloomFilter struct {
config BloomFilterConfig
rdb *redis.Client
}
// ExistsID 检查数字ID是否存在于布隆过滤器中
func (bf *BloomFilter) ExistsID(ctx context.Context, id uint) (bool, error) {
return bf.Exists(ctx, strconv.FormatUint(uint64(id), 10))
}
// AddIDs 批量添加数字ID到布隆过滤器
func (bf *BloomFilter) AddIDs(ctx context.Context, ids []uint) ([]bool, error) {
items := make([]string, len(ids))
for i, id := range ids {
items[i] = strconv.FormatUint(uint64(id), 10)
}
return bf.AddMulti(ctx, items)
}解决方案 2:缓存空值
原理: 当查询的数据不存在时,将空值缓存起来,避免重复查询数据库。
实现:
// 查询数据库
shop, err := dao.GetShopById(ctx, db, shopId)
if err != nil {
// 数据不存在,缓存空值
dao.SetShopCacheById(ctx, rds, shopId, nil)
return utils.ErrorResult("商铺不存在")
}缺点:
- 占用缓存空间
- 需要设置较短的过期时间
解决方案 3:请求限流
原理: 对同一 IP 或同一用户的请求进行限流,防止恶意请求。
实现:
// 使用 Redis 计数器限流
key := fmt.Sprintf("rate:limit:shop:%s:%d", ip, shopId)
count, _ := rds.Incr(ctx, key).Result()
rds.Expire(ctx, key, time.Minute)
if count > 10 {
return utils.ErrorResult("请求过于频繁,请稍后重试")
}7.2 缓存雪崩
什么是缓存雪崩?
缓存雪崩是指大量的缓存同时失效,导致大量请求同时穿透到数据库,造成数据库压力过大甚至宕机。
场景示例
场景1:批量设置缓存时过期时间相同
SET cache:shop:description:1 "{...}" EX 3600
SET cache:shop:description:2 "{...}" EX 3600
SET cache:shop:description:3 "{...}" EX 3600
...
↓
1小时后,所有缓存同时失效
↓
大量请求同时穿透到数据库 → 数据库宕机解决方案 1:过期时间加随机值(推荐)
原理: 在设置缓存过期时间时,加上一个随机值,避免所有缓存同时失效。
实现:
// 设置缓存时,过期时间加随机值
baseExpire := time.Hour
randomExpire := time.Duration(rand.Intn(300)) * time.Second // 0-5分钟随机
totalExpire := baseExpire + randomExpire
err = rds.Set(ctx, key, value, totalExpire).Err()效果:
- 基础过期时间:1 小时
- 随机过期时间:0-5 分钟
- 实际过期时间:1 小时 0 分 - 1 小时 5 分
- 避免所有缓存同时失效
解决方案 2:缓存预热
原理: 在系统启动或低峰期,提前加载热点数据到缓存。
实现:
// 系统启动时预热缓存
func WarmUpCache(ctx context.Context) {
// 1. 查询热门店铺
hotShops, _ := dao.GetHotShops(ctx, db, 100)
// 2. 批量加载到缓存
for _, shop := range hotShops {
dao.SetShopCacheById(ctx, rds, shop.ID, &shop)
}
log.Printf("缓存预热完成,加载了%d个热门店铺", len(hotShops))
}解决方案 3:互斥锁(防止击穿)
原理: 当缓存失效时,只允许一个线程查询数据库,其他线程等待并查询缓存。
实现:
// 尝试获取锁
if !utils.TryLock(ctx, rds, lockKey) {
// 获取锁失败,等待后重新查询缓存
time.Sleep(50 * time.Millisecond)
shop, err = dao.GetShopCacheById(ctx, rds, shopId)
if err == nil && shop != nil {
return utils.SuccessResultWithData(shop)
}
return utils.ErrorResult("服务繁忙,请稍后重试")
}// TryLock 尝试获取锁(无TTL)
func TryLock(ctx context.Context, rds *redis.Client, key string) bool {
// 使用 SETNX 命令设置锁
result := rds.SetNX(ctx, key, "1", 0).Val()
return result
}
// UnLock 释放锁
func UnLock(ctx context.Context, rds *redis.Client, key string) {
rds.Del(ctx, key)
}解决方案 4:高可用架构
原理: 使用 Redis 集群或哨兵模式,避免单点故障。
架构:
┌─────────────────────────────────────────────────────────────┐
│ Redis 集群架构 │
└─────────────────────────────────────────────────────────────┘
应用服务器1
↓
Redis Master 1 ← Redis Slave 1
↓
Redis Master 2 ← Redis Slave 2
↓
应用服务器27.3 缓存击穿
什么是缓存击穿?
缓存击穿是指热点数据的缓存失效,大量请求同时穿透到数据库。
场景示例
场景1:热门店铺缓存失效
热门店铺ID: 1(缓存过期时间: 1小时)
↓
1000个用户同时查询店铺1
↓
查询缓存: cache:shop:description:1 → 已过期
↓
1000个请求同时穿透到数据库 → 数据库压力过大与缓存雪崩的区别
| 问题 | 触发条件 | 影响范围 | 解决方案 |
|---|---|---|---|
| 缓存穿透 | 查询不存在的数据 | 单个请求 | 布隆过滤器 |
| 缓存雪崩 | 大量缓存同时失效 | 所有请求 | 过期时间加随机值 |
| 缓存击穿 | 热点数据缓存失效 | 单个热点数据 | 互斥锁 |
解决方案 1:互斥锁(推荐)
原理: 当缓存失效时,只允许一个线程查询数据库,其他线程等待并查询缓存。
实现:
// 尝试获取锁
lockKey := fmt.Sprintf("lock:shop:%d", shopId)
if !utils.TryLock(ctx, rds, lockKey) {
// 获取锁失败,等待后重新查询缓存
time.Sleep(50 * time.Millisecond)
shop, err = dao.GetShopCacheById(ctx, rds, shopId)
if err == nil && shop != nil {
return utils.SuccessResultWithData(shop)
}
return utils.ErrorResult("服务繁忙,请稍后重试")
}
// 获取锁成功,确保释放锁
defer utils.UnLock(ctx, rds, lockKey)解决方案 2:逻辑过期
原理: 在缓存中存储逻辑过期时间,即使 Redis 缓存未过期,也可以判断数据是否需要更新。
实现:
type ShopCache struct {
Shop *models.Shop
ExpireAt time.Time
}
// 设置缓存时,添加逻辑过期时间
cache := &ShopCache{
Shop: shop,
ExpireAt: time.Now().Add(time.Hour),
}
jsonData, _ := json.Marshal(cache)
rds.Set(ctx, key, jsonData, 2*time.Hour)
// 查询缓存时,检查逻辑过期时间
cacheData, _ := rds.Get(ctx, key).Result()
var cache ShopCache
json.Unmarshal([]byte(cacheData), &cache)
if time.Now().After(cache.ExpireAt) {
// 逻辑过期,重新查询数据库
return getShopFromDB(ctx, shopId)
}解决方案 3:热点数据永不过期
原理: 对于热点数据,不设置过期时间,通过后台任务定期更新。
实现:
// 热点数据不设置过期时间
if isHotShop(shopId) {
rds.Set(ctx, key, value, 0) // 永不过期
} else {
rds.Set(ctx, key, value, time.Hour)
}
// 后台任务定期更新热点数据
func UpdateHotShopsCache() {
hotShops := getHotShops()
for _, shop := range hotShops {
dao.SetShopCacheById(ctx, rds, shop.ID, &shop)
}
}八、地理位置缓存(GEO)
8.1 GEO 数据结构
什么是 GEO?
GEO(Geospatial)是 Redis 提供的地理位置数据结构,用于存储和查询地理位置信息。
GEO 的特点
- 高效计算:内置地理位置计算算法
- 距离排序:可以按距离排序返回结果
- 范围查询:支持半径范围内的查询
- 类型查询:支持按类型分组存储
8.2 GEO 命令
| 命令 | 作用 | 示例 |
|---|---|---|
| GEOADD | 添加地理位置 | GEOADD key longitude latitude member |
| GEOSEARCH | 查询附近位置 | GEOSEARCH key FROMLONLAT x y BYRADIUS 10 km |
| GEODIST | 计算两点距离 | GEODIST key member1 member2 |
| GEOPOS | 获取位置坐标 | GEOPOS key member |
| GEORADIUS | 查询半径内的位置 | GEORADIUS key x y radius km |
8.3 代码实现
DAO 层:地理位置缓存
文件:dao/shop.go
// LoadShopData 加载店铺地理位置数据到缓存
func LoadShopData(ctx context.Context, db *gorm.DB, rds *redis.Client) error {
// 1. 查询所有的店铺
var shops []models.Shop
err := db.WithContext(ctx).Model(&models.Shop{}).Find(&shops).Error
if err != nil {
return fmt.Errorf("failed to query shops: %w", err)
}
// 2. 遍历店铺,根据类型进行缓存
for _, shop := range shops {
// 2.1 使用 GEOADD 存储店铺位置信息
err = rds.GeoAdd(ctx, ShopLocationCache+strconv.Itoa(int(shop.TypeID)), &redis.GeoLocation{
Name: strconv.Itoa(int(shop.ID)),
Latitude: shop.Y,
Longitude: shop.X,
}).Err()
if err != nil {
return fmt.Errorf("failed to set geo cache: %w", err)
}
}
return nil
}
// GetNearbyShops 获取某个店铺的附近某个距离的所有点
func GetNearbyShops(ctx context.Context, rds *redis.Client, shop *models.Shop, radius float64, unit string, count int) ([]uint, error) {
key := ShopLocationCache + strconv.Itoa(int(shop.TypeID))
result, err := rds.GeoSearch(ctx, key, &redis.GeoSearchQuery{
Latitude: shop.Y,
Longitude: shop.X,
Radius: radius,
RadiusUnit: unit,
Count: count,
}).Result()
if err != nil {
return nil, fmt.Errorf("failed to get geo cache: %w", err)
}
// 2. 解析结果,提取店铺ID
var shopIds []uint
for _, loc := range result {
id, _ := strconv.Atoi(loc)
shopIds = append(shopIds, uint(id))
}
return shopIds, nil
}Service 层:附近店铺查询
// GetNearbyShops 获取某个店铺的附近某个距离的所有点
func GetNearbyShops(ctx context.Context, shopId uint, radius float64, count int) *utils.Result {
// 1. 查询店铺
shop, err := dao.GetShopById(ctx, dao.DB, shopId)
if err != nil {
return utils.ErrorResult("查询店铺失败: " + err.Error())
}
// 2. 查询附近的同类型商铺
shopIds, err := dao.GetNearbyShops(ctx, dao.Redis, shop, radius, "km", count)
if err != nil {
return utils.ErrorResult("查询附近商铺失败: " + err.Error())
}
// 3. 返回结果
return utils.SuccessResultWithData(shopIds)
}九、Redis 命令速查表
9.1 String 命令
| 命令 | 作用 | 示例 |
|---|---|---|
| SET | 设置键值对 | SET cache:shop:description:1 "{...}" EX 3600 |
| GET | 获取值 | GET cache:shop:description:1 |
| DEL | 删除键 | DEL cache:shop:description:1 |
| EXISTS | 检查键是否存在 | EXISTS cache:shop:description:1 |
| TTL | 获取剩余时间 | TTL cache:shop:description:1 |
| EXPIRE | 设置过期时间 | EXPIRE cache:shop:description:1 3600 |
9.2 GEO 命令
| 命令 | 作用 | 示例 |
|---|---|---|
| GEOADD | 添加地理位置 | GEOADD cache:shop:location:1 116.404 39.915 1 |
| GEOSEARCH | 查询附近位置 | GEOSEARCH cache:shop:location:1 FROMLONLAT 116.404 39.915 BYRADIUS 5 km COUNT 10 |
| GEODIST | 计算两点距离 | GEODIST cache:shop:location:1 1 2 |
| GEOPOS | 获取位置坐标 | GEOPOS cache:shop:location:1 1 |
| GEORADIUS | 查询半径内的位置 | GEORADIUS cache:shop:location:1 116.404 39.915 5 km |
9.3 布隆过滤器命令
| 命令 | 作用 | 示例 |
|---|---|---|
| BF.RESERVE | 创建布隆过滤器 | BF.RESERVE shop:bloom:filter 0.01 100000 |
| BF.ADD | 添加元素 | BF.ADD shop:bloom:filter 1 |
| BF.MADD | 批量添加元素 | BF.MADD shop:bloom:filter 1 2 3 |
| BF.EXISTS | 检查元素是否存在 | BF.EXISTS shop:bloom:filter 1 |
| BF.MEXISTS | 批量检查元素 | BF.MEXISTS shop:bloom:filter 1 2 3 |
| BF.INFO | 获取布隆过滤器信息 | BF.INFO shop:bloom:filter |
十、总结
10.1 核心要点
- 缓存的价值:提高性能、降低数据库压力、提升用户体验
- 数据结构选择:String 存储详情、GEO 存储位置
- 缓存更新策略:Cache Aside(先更新数据库,再删除缓存)
- 数据一致性:最终一致性即可,无需强一致性
- 防止缓存穿透:布隆过滤器 + 缓存空值 + 请求限流
- 防止缓存雪崩:过期时间加随机值 + 缓存预热 + 互斥锁
- 防止缓存击穿:互斥锁 + 逻辑过期 + 热点数据永不过期
10.2 最佳实践
- Key 命名规范:使用冒号分隔的层级结构
- 过期时间设置:基础时间 + 随机时间
- 错误处理:区分缓存未命中和其他错误
- 监控和告警:监控缓存命中率、数据库压力
- 日志记录:记录缓存操作,便于排查问题
- 性能优化:使用 Pipeline 批量操作
- 高可用:使用 Redis 集群或哨兵模式
10.3 性能指标
| 指标 | 目标值 | 说明 |
|---|---|---|
| 缓存命中率 | > 80% | 缓存命中占总查询的比例 |
| 响应时间 | < 100ms | 缓存查询的平均响应时间 |
| 数据库查询 | < 20% | 数据库查询占总查询的比例 |
| 缓存穿透率 | < 1% | 查询不存在数据的比例 |
十一、附录
11.1 项目结构
hm-dianping-go/
├── service/
│ └── shop_service.go # Service 层
├── dao/
│ └── shop.go # DAO 层
└── utils/
├── bloom.go # 布隆过滤器
└── lock.go # 分布式锁11.2 相关文件链接
11.3 参考文档
Redis 实战篇-秒杀系统实现
一、全局 ID 生成器:UUID、Redis 自增、雪花算法
1.1 为什么需要全局唯一 ID
在秒杀场景中,订单量巨大,如果使用数据库自增 ID,会存在以下问题:
| 问题 | 说明 |
|---|---|
| 安全性问题 | 自增 ID 可预测,暴露业务量,容易被爬虫遍历 |
| 分库分表问题 | 多个数据库实例会产生 ID 冲突 |
| 性能瓶颈 | 单点数据库生成 ID 成为瓶颈 |
1.2 常见 ID 生成方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| UUID | 简单、无依赖 | 无序、太长、无业务含义 | 非主键场景 |
| Redis 自增 | 简单、有序、高性能 | 依赖 Redis、需要持久化 | 中等规模 |
| 雪花算法 | 高性能、分布式、有序 | 依赖时钟、需要机器 ID | 大规模分布式 |
1.3 Redis 自增 ID 生成器
原理:利用 Redis 的 INCR 命令实现原子自增。
// utils/redis_id_worker.go
type RedisIdWorker struct {
rdb *redis.Client
beginTimestamp int64 // 起始时间戳
countBits uint8 // 序列号位数
}
func (w *RedisIdWorker) NextId(ctx context.Context, key string) (int64, error) {
// 1. 生成时间戳部分
now := time.Now().UTC().UnixMilli()
timestamp := now - w.beginTimestamp
// 2. 生成序列号部分(按日期分组,每天重新计数)
date := time.Now().UTC().Format("2006:01:02")
seq, err := w.rdb.Incr(ctx, "icr:"+key+":"+date).Result()
if err != nil {
return 0, err
}
// 3. 拼接:时间戳左移 + 序列号
return (timestamp << w.countBits) | seq, nil
}ID 结构:
| 符号位(1bit) | 时间戳(41bit) | 序列号(22bit) |使用示例:
idWorker := utils.NewRedisIdWorker(dao.Redis, 32)
orderId, _ := idWorker.NextId(ctx, "order")1.4 雪花算法(Snowflake)
ID 结构(64 位):
| 符号位(1bit) | 时间戳(41bit) | 机器ID(10bit) | 序列号(12bit) |项目实现:utils/snowflake.go
const (
epoch = 1577836800000 // 起始时间戳 2020-01-01
workerIDBits = 10 // 机器ID位数
sequenceBits = 12 // 序列号位数
maxWorkerID = -1 ^ (-1 << 10) // 最大机器ID: 1023
maxSequence = -1 ^ (-1 << 12) // 最大序列号: 4095
)
type Snowflake struct {
mu sync.Mutex
workerID int64 // 机器ID (0-1023)
sequence int64 // 序列号
lastTime int64 // 上次生成时间
}
func (s *Snowflake) NextID() (int64, error) {
s.mu.Lock()
defer s.mu.Unlock()
now := time.Now().UnixMilli()
// 时钟回拨检测
if now < s.lastTime {
return 0, errors.New("clock moved backwards")
}
// 同一毫秒内序列号递增
if now == s.lastTime {
s.sequence = (s.sequence + 1) & maxSequence
if s.sequence == 0 {
now = s.waitNextMillis(s.lastTime)
}
} else {
s.sequence = 0
}
s.lastTime = now
// 组装ID
return ((now - epoch) << 22) | (s.workerID << 12) | s.sequence, nil
}使用示例:
sf, _ := utils.NewSnowflake(1) // 机器ID为1
id, _ := sf.NextID()二、实现优惠券秒杀下单:初步实现
2.1 秒杀业务流程
用户请求秒杀
↓
检查秒杀券是否存在
↓
检查秒杀时间(开始时间、结束时间)
↓
检查库存是否充足
↓
检查是否重复购买(一人一单)
↓
扣减库存
↓
创建订单
↓
返回结果2.2 数据库设计
秒杀券表 tb_seckill_voucher:
| 字段 | 类型 | 说明 |
|---|---|---|
| voucher_id | bigint | 优惠券 ID(主键,关联 tb_voucher) |
| stock | bigint | 库存 |
| begin_time | datetime | 开始时间 |
| end_time | datetime | 结束时间 |
订单表 tb_voucher_order:
| 字段 | 类型 | 说明 |
|---|---|---|
| id | bigint | 订单 ID |
| user_id | bigint | 用户 ID |
| voucher_id | bigint | 优惠券 ID |
| voucher_type | int | 券类型(1:普通券 2:秒杀券) |
唯一约束:确保一人一单
CREATE UNIQUE INDEX uk_seckill_user_voucher
ON tb_voucher_order (user_id, voucher_id)
WHERE voucher_type = 2;2.3 初步实现代码
func SeckillVoucher(ctx context.Context, userId, voucherId uint) *utils.Result {
// 1. 检查秒杀券是否存在
seckillVoucher, err := dao.GetSeckillVoucherByID(voucherId)
if err != nil {
return utils.ErrorResult("秒杀券不存在")
}
// 2. 检查秒杀时间
now := time.Now()
if now.Before(seckillVoucher.BeginTime) {
return utils.ErrorResult("秒杀尚未开始")
}
if now.After(seckillVoucher.EndTime) {
return utils.ErrorResult("秒杀已结束")
}
// 3. 检查库存
if seckillVoucher.Stock <= 0 {
return utils.ErrorResult("库存不足")
}
// 4. 检查是否重复购买
exists, _ := dao.CheckSeckillVoucherOrderExists(ctx, dao.DB, userId, voucherId)
if exists {
return utils.ErrorResult("不能重复购买")
}
// 5. 扣减库存
err = dao.UpdateSeckillVoucherStock(voucherId, 1)
if err != nil {
return utils.ErrorResult("库存不足")
}
// 6. 创建订单
order := &models.VoucherOrder{
UserID: userId,
VoucherID: voucherId,
VoucherType: 2,
}
dao.CreateVoucherOrder(ctx, dao.DB, order)
return utils.SuccessResultWithData(order.ID)
}2.4 存在的问题
| 问题 | 说明 |
|---|---|
| 超卖问题 | 库存检查和扣减不是原子操作 |
| 一人一单失效 | 检查和创建订单不是原子操作 |
| 性能问题 | 直接操作数据库,无法承受高并发 |
三、库存超卖问题:乐观锁实现
3.1 超卖问题分析
场景:库存只剩 1 件,两个用户同时购买
时间线:
T1: 用户A查询库存 = 1
T2: 用户B查询库存 = 1
T3: 用户A扣减库存 → 库存 = 0
T4: 用户B扣减库存 → 库存 = -1(超卖!)3.2 乐观锁方案
核心思想:在更新时检查数据是否被修改过。
CAS 方式:检查库存的同时扣减
// 扣减库存(乐观锁CAS操作)
// 来源:dao/seckill_voucher.go
func UpdateSeckillVoucherStock(voucherID uint, stock int) error {
result := DB.Model(&models.SeckillVoucher{}).
Where("voucher_id = ? AND stock >= ?", voucherID, stock).
Update("stock", gorm.Expr("stock - ?", stock))
if result.RowsAffected == 0 {
return gorm.ErrRecordNotFound // 库存不足或并发冲突
}
return nil
}SQL 等价于:
UPDATE tb_seckill_voucher
SET stock = stock - 1
WHERE voucher_id = ? AND stock >= ?3.3 项目中的完整实现(版本 1)
来源:service/voucher_order_service.go
这是项目中的第一个版本实现,使用乐观锁 + 数据库事务:
// SeckillVoucher 秒杀优惠券(使用乐观锁)
// 版本1:数据库事务 + 乐观锁方案
func SeckillVoucher(ctx context.Context, userId, voucherId uint) *utils.Result {
// 1. 检查秒杀券是否存在
seckillVoucher, err := dao.GetSeckillVoucherByID(voucherId)
if err != nil {
log.Printf("查询秒杀券失败: %v", err)
return utils.ErrorResult("秒杀券不存在")
}
// 2. 检查秒杀时间
now := time.Now()
if now.Before(seckillVoucher.BeginTime) {
return utils.ErrorResult("秒杀尚未开始")
}
if now.After(seckillVoucher.EndTime) {
return utils.ErrorResult("秒杀已结束")
}
// 3. 检查库存
if seckillVoucher.Stock <= 0 {
return utils.ErrorResult("库存不足")
}
// 4. 检查用户是否已经购买过该秒杀券(一人一单限制)
exists, err := dao.CheckSeckillVoucherOrderExists(ctx, dao.DB, userId, voucherId)
if err != nil {
log.Printf("检查秒杀券订单是否存在失败: %v", err)
return utils.ErrorResult("系统错误")
}
if exists {
return utils.ErrorResult("不能重复购买")
}
// 5. 使用乐观锁重试机制进行库存扣减和订单创建
const maxRetries = 3
for i := 0; i < maxRetries; i++ {
// 开始事务
tx := dao.DB.Begin()
if tx.Error != nil {
log.Printf("开始事务失败: %v", tx.Error)
return utils.ErrorResult("系统错误")
}
// 扣减库存(乐观锁CAS操作)
err = dao.UpdateSeckillVoucherStock(voucherId, 1)
if err != nil {
tx.Rollback()
if errors.Is(err, gorm.ErrRecordNotFound) {
// 库存不足或并发冲突,重试
if i == maxRetries-1 {
return utils.ErrorResult("库存不足")
}
// 短暂等待后重试(指数退避)
time.Sleep(time.Duration(i+1) * 10 * time.Millisecond)
continue
}
log.Printf("扣减库存失败: %v", err)
return utils.ErrorResult("系统错误")
}
// 6. 创建秒杀券订单
now = time.Now()
order := &models.VoucherOrder{
UserID: userId,
VoucherID: voucherId,
PayType: 1,
Status: 1,
CreateTime: &now,
VoucherType: 2, // 秒杀券类型
}
err = dao.CreateVoucherOrder(ctx, tx, order)
if err != nil {
tx.Rollback()
log.Printf("创建订单失败: %v", err)
return utils.ErrorResult("创建订单失败")
}
// 7. 提交事务
if err := tx.Commit().Error; err != nil {
tx.Rollback()
log.Printf("提交事务失败: %v", err)
return utils.ErrorResult("系统错误")
}
// 8. 成功,返回订单ID
return utils.SuccessResultWithData(order.ID)
}
// 重试次数用完,返回失败
return utils.ErrorResult("服务繁忙,请稍后重试")
}关键点说明:
| 步骤 | 说明 |
|---|---|
| 1-4 | 前置检查:秒杀券存在性、时间、库存、一人一单 |
| 5 | 乐观锁重试机制,最多重试 3 次 |
| 6 | 创建订单,依赖数据库唯一索引保证一人一单 |
| 7 | 事务提交,确保原子性 |
一人一单的数据库约束:
-- 只对秒杀券创建唯一约束
-- 来源:models/voucher_order.go
CREATE UNIQUE INDEX uk_seckill_user_voucher
ON tb_voucher_order (user_id, voucher_id)
WHERE voucher_type = 2;
-- 普通券只创建普通索引用于查询优化
CREATE INDEX idx_normal_user_voucher
ON tb_voucher_order (user_id, voucher_id, voucher_type);3.4 乐观锁的优缺点
| 优点 | 缺点 |
|---|---|
| 无锁等待,性能好 | 冲突时需要重试 |
| 适合读多写少 | 写多时成功率低 |
| 实现简单 | 需要额外字段或条件 |
3.5 版本 1 存在的问题
| 问题 | 说明 |
|---|---|
| 性能瓶颈 | 所有操作都在数据库事务中,高并发时数据库压力大 |
| 一人一单失效 | 集群环境下,不同服务实例的本地锁无法互斥 |
| 重试开销 | 冲突时需要多次重试,浪费数据库连接 |
四、一人一单问题:悲观锁实现
4.1 问题分析
场景:同一用户快速点击两次秒杀
时间线:
T1: 请求A检查用户是否购买 → false
T2: 请求B检查用户是否购买 → false
T3: 请求A创建订单 → 成功
T4: 请求B创建订单 → 成功(重复购买!)4.2 悲观锁方案
核心思想:使用数据库事务 + 唯一索引
func SeckillVoucher(ctx context.Context, userId, voucherId uint) *utils.Result {
// 使用用户ID加锁,确保同一用户串行执行
tx := dao.DB.Begin()
// 加锁查询(SELECT FOR UPDATE)
var order models.VoucherOrder
tx.Set("gorm:query_option", "FOR UPDATE").
Where("user_id = ? AND voucher_id = ? AND voucher_type = 2",
userId, voucherId).
First(&order)
if order.ID != 0 {
tx.Rollback()
return utils.ErrorResult("不能重复购买")
}
// 扣减库存...
// 创建订单...
order := &models.VoucherOrder{...}
tx.Create(order)
tx.Commit()
return utils.SuccessResultWithData(order.ID)
}4.3 唯一索引兜底
即使代码层面有并发问题,数据库唯一索引也能保证数据一致性:
-- 秒杀券订单唯一约束
CREATE UNIQUE INDEX uk_seckill_user_voucher
ON tb_voucher_order (user_id, voucher_id)
WHERE voucher_type = 2;当重复插入时,数据库会报唯一键冲突错误。
4.4 集群下的并发安全问题
问题:单机锁在集群环境下失效
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 服务实例1 │ │ 服务实例2 │ │ 服务实例3 │
│ synchronized│ │ synchronized│ │ synchronized│
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└───────────────────┼───────────────────┘
│
┌──────▼──────┐
│ 数据库 │
└─────────────┘
问题:实例1的锁无法阻止实例2的并发请求!解决方案:使用分布式锁
五、分布式锁
5.1 分布式锁的基本原理
核心要求:
- 互斥性:任意时刻只有一个客户端持有锁
- 防死锁:锁必须有超时时间
- 安全性:只能释放自己持有的锁
- 高可用:锁服务要高可用
5.2 不同实现方式对比
| 实现方式 | 优点 | 缺点 | 实现原理 |
|---|---|---|---|
| MySQL | 简单、可靠 | 性能差、有单点问题 | 利用数据库的行锁或乐观锁机制,通过SELECT ... FOR UPDATE或版本号实现互斥 |
| Zookeeper | 强一致性、可靠性高 | 性能一般、部署复杂 | 创建临时有序节点,最小节点获得锁,利用 Watch 机制监听前序节点 |
| Redis | 性能高、实现简单 | 需要处理主从同步问题 | 使用SETNX命令原子性设置键值,配合过期时间实现互斥锁 |
5.3 Redis 实现分布式锁
基本实现(SETNX)
// 获取锁
func TryLock(ctx context.Context, rds *redis.Client, key string) bool {
ok, _ := rds.SetNX(ctx, key, "1", 0).Result()
return ok
}
// 释放锁
func UnLock(ctx context.Context, rds *redis.Client, key string) {
rds.Del(ctx, key)
}锁误删问题
场景:
T1: 客户端A获取锁,设置过期时间10秒
T2: 客户端A执行业务超过10秒,锁自动过期
T3: 客户端B获取锁
T4: 客户端A执行完毕,释放锁(释放了B的锁!)解决方案:锁值设为唯一标识,释放时检查
建议格式:UUID + 线程ID(在 Go 中可以是 UUID + Goroutine ID 或直接生成一个随机字符串)。
// 获取锁(带唯一标识)
func TryLockWithTTL(ctx context.Context, rds *redis.Client, key string, ttl time.Duration) (bool, string) {
lockValue := generateLockValue() // 生成唯一值
result, _ := rds.SetNX(ctx, key, lockValue, ttl).Result()
if result {
return true, lockValue
}
return false, ""
}
// 安全释放锁
func UnLockSafe(ctx context.Context, rds *redis.Client, key, value string) bool {
// 问题:GET + DEL 不是原子操作!
val, _ := rds.Get(ctx, key).Result()
if val == value {
rds.Del(ctx, key)
return true
}
return false
}5.4 Lua 脚本详解
5.4.1 为什么需要 Lua 脚本
在 Redis 中,多个命令的执行不是原子的。例如释放锁时需要先 GET 判断再 DEL:
客户端A: GET lock_key → 返回 "uuid-A"
↓ 此时锁过期
客户端B: SETNX lock_key → 获取锁成功
↓
客户端A: DEL lock_key → 删除了B的锁!Lua 脚本的核心优势:
- 原子性:整个脚本作为一个整体执行,中间不会被其他命令打断
- 高性能:减少网络开销,多条命令一次发送
- 复用性:脚本可以被缓存,通过 SHA1 摘要重复调用
5.4.2 Lua 脚本基础语法
Lua 语言简介: Lua 是一种轻量级脚本语言,Redis 内置了 Lua 5.1 解释器。
基本数据类型:
-- Lua基本数据类型
local num = 100 -- 数字
local str = "hello" -- 字符串
local bool = true -- 布尔
local nil_val = nil -- nil(类似null)
local table = {} -- 表(数组和字典的统称)
-- 表的使用
local arr = {1, 2, 3} -- 数组形式
local dict = {name = "test", age = 20} -- 字典形式
print(dict.name) -- 访问: test条件语句:
-- if-else语句
local score = 85
if score >= 90 then
print("优秀")
elseif score >= 60 then
print("及格")
else
print("不及格")
end循环语句:
-- for循环
for i = 1, 10 do
print(i)
end
-- while循环
local count = 0
while count < 5 do
count = count + 1
end
-- 遍历表
local t = {a = 1, b = 2, c = 3}
for k, v in pairs(t) do
print(k, v)
end函数定义:
-- 函数定义
function add(a, b)
return a + b
end
-- 匿名函数
local multiply = function(a, b)
return a * b
end5.4.3 Redis 中的 Lua 脚本
在 Redis 中调用 Lua 脚本的方式:
| 命令 | 说明 | 示例 |
|---|---|---|
EVAL | 直接执行脚本 | EVAL "return redis.call('get', KEYS[1])" 1 mykey |
EVALSHA | 通过 SHA1 摘要执行缓存脚本 | EVALSHA "abc123..." 1 mykey |
SCRIPT LOAD | 缓存脚本并返回 SHA1 | SCRIPT LOAD "return 1" |
SCRIPT EXISTS | 检查脚本是否缓存 | SCRIPT EXISTS "abc123..." |
SCRIPT FLUSH | 清除所有缓存脚本 | SCRIPT FLUSH |
KEYS 和 ARGV 的区别:
-- KEYS数组:存放Redis的键名
-- ARGV数组:存放其他参数
-- 格式: EVAL "script" numkeys key1 key2 ... arg1 arg2 ...
-- 示例:EVAL "script" 2 key1 key2 arg1 arg2
-- KEYS[1] = key1
-- KEYS[2] = key2
-- ARGV[1] = arg1
-- ARGV[2] = arg2重要规则:
numkeys指定 KEYS 数组的长度- KEYS 用于传递键名,遵循 Redis 集群规则
- ARGV 用于传递值参数
- 建议:键名通过 KEYS 传递,其他参数通过 ARGV 传递
redis.call vs redis.pcall:
-- redis.call:出错时直接返回错误给客户端
local val = redis.call('get', 'nonexistent')
-- redis.pcall:出错时返回错误对象,脚本继续执行
local result = redis.pcall('get', 'nonexistent')
if result.err then
-- 处理错误
return "error occurred"
end5.4.4 Lua 脚本原子性原理
为什么 Lua 脚本是原子的?
┌─────────────────────────────────────────────────────────────┐
│ Redis命令执行流程 │
└─────────────────────────────────────────────────────────────┘
普通命令执行:
┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐
│ 命令1 │ → │ 命令2 │ → │ 命令3 │ → │ 命令4 │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
↑ ↑ ↑ ↑
原子 原子 原子 原子
─────────────────────────────────────────────────
其他命令可能插入执行
Lua脚本执行:
┌─────────────────────────────────────────────────────────────┐
│ Lua脚本整体执行 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 命令1 │ → │ 命令2 │ → │ 命令3 │ → │ 命令4 │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
↑
整体原子执行
其他命令无法插入原理说明:
- Redis 是单线程执行命令的
- 执行 Lua 脚本时,Redis 会阻塞其他命令
- 直到脚本执行完毕,才会处理其他命令
- 这保证了脚本内所有操作的原子性
注意事项:
- 脚本不要执行耗时操作,会阻塞 Redis
- 脚本不要有死循环,会导致 Redis 卡死
- 合理控制脚本复杂度,避免超时
5.4.5 分布式锁释放的 Lua 脚本实现
问题:GET 和 DEL 之间可能被其他请求打断
解决方案:使用 Lua 脚本保证原子性
-- unlock.lua
-- KEYS[1]: 锁的键名
-- ARGV[1]: 锁的唯一标识(UUID)
-- 原子性地检查并删除锁
if redis.call("get", KEYS[1]) == ARGV[1] then
-- 锁值匹配,删除锁
return redis.call("del", KEYS[1])
else
-- 锁值不匹配,说明锁已被其他客户端持有
return 0
endGo 调用 Lua 脚本:
// UnLockSafe 安全释放分布式锁
// 使用Lua脚本保证"判断锁值"和"删除锁"的原子性
func UnLockSafe(ctx context.Context, rds *redis.Client, key, value string) bool {
// Lua脚本:先检查锁值,再删除
// 只有锁值匹配时才删除,避免误删其他客户端的锁
luaScript := `
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
`
// 执行Lua脚本
// []string{key}: KEYS数组,包含锁的键名
// value: ARGV[1],锁的唯一标识
result, err := rds.Eval(ctx, luaScript, []string{key}, value).Result()
if err != nil {
return false
}
// 返回1表示删除成功,0表示锁值不匹配
return result.(int64) == 1
}5.4.6 Go 中加载外部 Lua 脚本文件
对于复杂的脚本,建议存储在独立文件中:
// 加载Lua脚本文件
func LoadLuaScript(filePath string) (string, error) {
content, err := os.ReadFile(filePath)
if err != nil {
return "", fmt.Errorf("读取脚本文件失败: %v", err)
}
return string(content), nil
}
// 使用示例
func ExecuteSeckillScript(ctx context.Context, rds *redis.Client, voucherId, userId, orderId string) (int64, error) {
// 加载脚本
script, err := LoadLuaScript("script/seckill.lua")
if err != nil {
return -1, err
}
// 执行脚本
result, err := rds.Eval(ctx, script, []string{}, voucherId, userId, orderId).Result()
if err != nil {
return -1, err
}
return result.(int64), nil
}使用 SCRIPT LOAD 优化性能:
var scriptSHA string
// 初始化时缓存脚本
func InitScript(ctx context.Context, rds *redis.Client) error {
script, _ := LoadLuaScript("script/seckill.lua")
sha, err := rds.ScriptLoad(ctx, script).Result()
if err != nil {
return err
}
scriptSHA = sha
return nil
}
// 后续使用SHA执行,避免重复传输脚本
func ExecuteBySHA(ctx context.Context, rds *redis.Client, keys []string, args ...interface{}) (interface{}, error) {
return rds.EvalSha(ctx, scriptSHA, keys, args...).Result()
}5.5 分布式锁优化
SETNX 锁的问题
| 问题 | 说明 |
|---|---|
| 不可重入 | 同一线程无法多次获取同一把锁 |
| 不可重试 | 获取失败直接返回,无重试机制 |
| 超时释放 | 业务执行时间超过锁过期时间会误删 |
| 主从一致性 | 主节点宕机,从节点未同步锁信息 |
5.6 Go 语言分布式锁库推荐
Go 语言中没有官方的 Redisson 库,但有几个优秀的替代方案:
5.6.1 Redsync(推荐)
Redsync 是 Go 语言中最流行的分布式锁库,基于 Redis 官方推荐的 Redlock 算法实现。
项目地址:github.com/go-redsync/redsync
特点:
- 基于 Redlock 算法,支持多 Redis 实例
- 支持锁自动过期,防止死锁
- 支持锁续期(Extend)
- 支持 Context 上下文
- 支持自定义重试策略
安装:
go get github.com/go-redsync/redsync/v4基本使用:
package main
import (
"context"
"fmt"
"time"
"github.com/go-redsync/redsync/v4"
"github.com/go-redsync/redsync/v4/redis/goredis/v9"
"github.com/redis/go-redis/v9"
)
func main() {
// 1. 创建Redis客户端
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
// 2. 创建连接池
pool := goredis.NewPool(client)
// 3. 创建Redsync实例
rs := redsync.New(pool)
// 4. 创建互斥锁
mutex := rs.NewMutex(
"my-lock",
redsync.WithExpiry(10*time.Second), // 锁过期时间
redsync.WithTries(3), // 重试次数
redsync.WithRetryDelay(500*time.Millisecond), // 重试间隔
)
// 5. 获取锁
if err := mutex.Lock(); err != nil {
panic(err)
}
defer mutex.Unlock() // 确保释放锁
// 6. 执行业务逻辑
fmt.Println("获取锁成功,执行业务逻辑...")
time.Sleep(5 * time.Second)
}支持 Context:
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 使用Context获取锁,支持超时取消
if err := mutex.LockContext(ctx); err != nil {
log.Printf("获取锁失败: %v", err)
return
}
// 使用Context释放锁
if ok, err := mutex.UnlockContext(ctx); !ok || err != nil {
log.Printf("释放锁失败: %v", err)
}锁续期(看门狗机制):
// 当业务执行时间可能超过锁过期时间时,需要续期
go func() {
ticker := time.NewTicker(3 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
// 续期锁
if ok, err := mutex.Extend(); !ok || err != nil {
log.Printf("锁续期失败: %v", err)
return
}
log.Println("锁续期成功")
case <-done:
return
}
}
}()多 Redis 实例部署(Redlock 算法):
// 创建多个Redis连接池,提高可靠性
pool1 := goredis.NewPool(redis.NewClient(&redis.Options{Addr: "localhost:6379"}))
pool2 := goredis.NewPool(redis.NewClient(&redis.Options{Addr: "localhost:6380"}))
pool3 := goredis.NewPool(redis.NewClient(&redis.Options{Addr: "localhost:6381"}))
// 使用多个池创建Redsync
rs := redsync.New(pool1, pool2, pool3)
// Redlock算法要求:需要在大多数节点(N/2 + 1)上成功获取锁
mutex := rs.NewMutex("distributed-lock")5.6.2 godisson
godisson 是 Redisson 的 Go 语言移植版本,提供类似 Redisson 的 API。
项目地址:github.com/cheerego/godisson
特点:
- API 风格类似 Java 版 Redisson
- 支持可重入锁
- 支持读写锁
- 内置看门狗机制
安装:
go get github.com/cheerego/godisson基本使用:
package main
import (
"fmt"
"time"
"github.com/cheerego/godisson"
"github.com/go-redis/redis/v8"
)
func main() {
// 1. 创建Redis客户端
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
// 2. 创建godisson实例
g := godisson.NewGodisson(client)
// 3. 获取可重入锁
lock := g.GetLock("my-lock")
// 4. 加锁
err := lock.Lock()
if err != nil {
panic(err)
}
defer lock.Unlock()
// 5. 执行业务逻辑
fmt.Println("获取锁成功")
}5.6.3 对比与选择
| 特性 | Redsync | godisson |
|---|---|---|
| 维护状态 | 活跃维护 | 较少更新 |
| Stars | 较多 | 较少 |
| Redlock 算法 | ✅ 完整支持 | ❌ |
| 可重入锁 | ❌ | ✅ |
| 看门狗 | 需手动实现 | ✅ 内置 |
| 读写锁 | ❌ | ✅ |
| 多节点支持 | ✅ | ❌ |
推荐选择:
- 生产环境推荐 Redsync:社区活跃,支持 Redlock 算法,可靠性高
- 简单场景可用 godisson:如果需要可重入锁和看门狗机制
5.6.4 在秒杀场景中的应用
// 使用Redsync实现秒杀一人一单
func SeckillVoucherWithLock(ctx context.Context, userId, voucherId uint) *utils.Result {
// 创建锁(以用户ID+优惠券ID为锁名,确保同一用户对同一优惠券串行)
mutex := rs.NewMutex(
fmt.Sprintf("lock:seckill:%d:%d", userId, voucherId),
redsync.WithExpiry(10*time.Second),
redsync.WithTries(3),
)
// 获取锁
if err := mutex.LockContext(ctx); err != nil {
return utils.ErrorResult("系统繁忙,请稍后重试")
}
defer mutex.Unlock()
// 执行秒杀逻辑
// 1. 检查库存
// 2. 检查一人一单
// 3. 扣减库存
// 4. 创建订单
return utils.SuccessResultWithData("秒杀成功")
}注意事项:
- 锁的粒度要合理,避免锁竞争过于激烈
- 锁的过期时间要大于业务执行时间
- 使用 defer 确保锁一定被释放
- 考虑使用多 Redis 实例提高可靠性
六、Redis 优化秒杀
6.1 异步秒杀思路
传统方案的问题:
- 所有操作都在数据库事务中
- 高并发时数据库压力大
- 响应时间长
优化思路:
┌─────────────────────────────────────────────────────────┐
│ 秒杀请求入口 │
└─────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ Redis Lua脚本(原子操作) │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 1. 检查秒杀时间 │ │
│ │ 2. 检查库存 │ │
│ │ 3. 检查一人一单 │ │
│ │ 4. 扣减库存(Redis) │ │
│ │ 5. 记录购买资格 │ │
│ │ 6. 发送消息到队列 │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────┬───────────────────────────────┘
│
┌───────────────┴───────────────┐
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────────┐
│ 返回用户成功 │ │ 消息队列(异步) │
└──────────────────┘ └──────────┬───────────┘
│
▼
┌──────────────────────┐
│ 消费者处理订单 │
│ 创建数据库记录 │
└──────────────────────┘6.2 秒杀资格判断
Redis 数据结构设计:
# 秒杀券库存
cache:seckill_voucher:stock:{voucherId} = stock
# 秒杀券信息(Hash)
cache:seckill_voucher:{voucherId}
voucher_id: xxx
stock: xxx
begin_time: xxx
end_time: xxx
# 已购买用户集合(Set)
cache:seckill_voucher:order:{voucherId} = [userId1, userId2, ...]6.3 基于阻塞队列实现(版本 2)
来源:service/voucher_order_service.go
这是项目中的第二个版本实现,使用 Lua 脚本 + Go 内存阻塞队列:
6.3.1 秒杀入口函数
// SeckillVoucher 秒杀优惠券
// 版本2:Lua脚本 + Go阻塞队列方案
func SeckillVoucher(ctx context.Context, userId, voucherId uint) *utils.Result {
// 从文件当中加载脚本
script, err := os.ReadFile("script/seckill.lua")
if err != nil {
log.Printf("读取秒杀脚本失败: %v", err)
return utils.ErrorResult("系统错误")
}
scriptStr := string(script)
// 1. 执行Lua脚本(原子性判断秒杀资格)
result := dao.Redis.Eval(ctx, scriptStr, []string{},
strconv.Itoa(int(voucherId)),
strconv.Itoa(int(userId)))
if result.Err() != nil {
log.Printf("执行秒杀脚本失败: %v", result.Err())
return utils.ErrorResult("系统错误")
}
// 2. 判断结果是否为 0,0的时候有资格完成
r, err := result.Int()
if err != nil {
log.Printf("获取秒杀脚本返回值失败: %v", err)
return utils.ErrorResult("系统错误")
}
if r != 0 {
if r == 1 {
return utils.ErrorResult("库存不足")
}
return utils.ErrorResult("不能重复购买")
}
// 3. 有购买资格,将订单信息保存到阻塞队列
err = AddOrderToQueue(userId, voucherId)
if err != nil {
log.Printf("订单入队失败: userId=%d, voucherId=%d, error=%v",
userId, voucherId, err)
return utils.ErrorResult("系统繁忙,请稍后重试")
}
// 4. 返回订单ID(这里可以生成一个临时ID或者返回成功信息)
return utils.SuccessResultWithData("秒杀成功,订单处理中...")
}6.3.2 订单信息结构体和全局变量
// VoucherOrderInfo 订单信息结构体,用于阻塞队列
type VoucherOrderInfo struct {
UserID uint `json:"userId"`
VoucherID uint `json:"voucherId"`
}
// 全局阻塞队列和相关变量
var (
orderQueue chan VoucherOrderInfo // 订单队列
queueOnce sync.Once // 确保队列只初始化一次
workerCount = 5 // worker数量
queueSize = 1000 // 队列大小
)6.3.3 队列初始化和 Worker
// InitOrderQueue 初始化订单队列和worker
func InitOrderQueue() {
queueOnce.Do(func() {
orderQueue = make(chan VoucherOrderInfo, queueSize)
// 启动多个worker goroutine处理订单
for i := 0; i < workerCount; i++ {
go orderWorker(i)
}
log.Printf("订单队列初始化完成,队列大小: %d, worker数量: %d",
queueSize, workerCount)
})
}
// orderWorker 订单处理worker
func orderWorker(workerID int) {
log.Printf("订单处理worker %d 启动", workerID)
for orderInfo := range orderQueue {
err := processOrder(orderInfo)
if err != nil {
log.Printf("Worker %d 处理订单失败: userId=%d, voucherId=%d, error=%v",
workerID, orderInfo.UserID, orderInfo.VoucherID, err)
// 这里可以添加重试逻辑或者将失败的订单放入死信队列
} else {
log.Printf("Worker %d 成功处理订单: userId=%d, voucherId=%d",
workerID, orderInfo.UserID, orderInfo.VoucherID)
}
}
}6.3.4 订单处理和入队
// processOrder 处理单个订单
func processOrder(orderInfo VoucherOrderInfo) error {
// 开始事务
tx := dao.DB.Begin()
if tx.Error != nil {
return tx.Error
}
defer func() {
if r := recover(); r != nil {
tx.Rollback()
}
}()
// 创建订单
now := time.Now()
order := &models.VoucherOrder{
UserID: orderInfo.UserID,
VoucherID: orderInfo.VoucherID,
PayType: 1,
Status: 1,
CreateTime: &now,
VoucherType: 2, // 秒杀券类型
}
// 创建订单记录
err := dao.CreateVoucherOrder(context.Background(), tx, order)
if err != nil {
tx.Rollback()
return err
}
// 提交事务
if err := tx.Commit().Error; err != nil {
tx.Rollback()
return err
}
return nil
}
// AddOrderToQueue 将订单添加到队列
func AddOrderToQueue(userID, voucherID uint) error {
orderInfo := VoucherOrderInfo{
UserID: userID,
VoucherID: voucherID,
}
select {
case orderQueue <- orderInfo:
return nil
default:
return fmt.Errorf("订单队列已满")
}
}6.3.5 版本 2 的优缺点
| 优点 | 说明 |
|---|---|
| 高性能 | Lua 脚本原子操作,Redis 内存操作 |
| 快速响应 | 用户请求立即返回,后台异步处理 |
| 削峰填谷 | 队列缓冲,平滑流量高峰 |
| 缺点 | 说明 |
|---|---|
| 数据丢失风险 | 内存队列不持久化,服务重启会丢失订单 |
| 队列容量有限 | 内存队列大小有限,超出会拒绝请求 |
| 无法追踪 | 订单在内存中,无法查询处理状态 |
问题:内存队列不持久化,服务重启会丢失订单 → 需要使用 Redis Stream 消息队列
七、Redis 消息队列实现异步秒杀
7.1 消息队列概念
消息队列(MQ):异步通信机制,生产者发送消息,消费者处理消息
优势:
- 解耦:生产者和消费者独立
- 异步:快速响应,后台处理
- 削峰:平滑流量高峰
7.2 Redis Stream 实现
Redis Stream:Redis 5.0 引入的消息队列结构
特点:
- 支持消费者组
- 支持消息确认(ACK)
- 支持持久化
- 支持阻塞读取
7.3 项目完整实现(版本 3)
来源:service/voucher_order_service.go
这是项目中的最终版本实现,使用 Lua 脚本 + Redis Stream 消息队列:
// SeckillVoucher 秒杀优惠券
// 版本3:Lua脚本 + Redis Stream消息队列方案(最终版本)
func SeckillVoucher(ctx context.Context, userId, voucherId uint) *utils.Result {
// 从文件当中加载脚本
script, err := os.ReadFile("script/seckill.lua")
if err != nil {
log.Printf("读取秒杀脚本失败: %v", err)
return utils.ErrorResult("系统错误")
}
scriptStr := string(script)
// 1. 执行Lua脚本(原子性判断秒杀资格 + 发送消息到Stream)
result := dao.Redis.Eval(ctx, scriptStr, []string{},
strconv.Itoa(int(voucherId)),
strconv.Itoa(int(userId)))
if result.Err() != nil {
log.Printf("执行秒杀脚本失败: %v", result.Err())
return utils.ErrorResult("系统错误")
}
// 2. 判断结果是否为 0,0的时候有资格完成
r, err := result.Int()
if err != nil {
log.Printf("获取秒杀脚本返回值失败: %v", err)
return utils.ErrorResult("系统错误")
}
// 3. 根据返回值返回不同结果
if r != 0 {
switch r {
case 1:
return utils.ErrorResult("库存不足")
case 2:
return utils.ErrorResult("不能重复购买")
case 3:
return utils.ErrorResult("秒杀券不存在")
case 4:
return utils.ErrorResult("秒杀尚未开始")
case 5:
return utils.ErrorResult("秒杀已结束")
default:
return utils.ErrorResult("系统错误")
}
}
// 4. 已经加入到消息队列了,返回成功
return utils.SuccessResultWithData("秒杀成功,订单处理中...")
}与版本 2 的区别:
| 对比项 | 版本 2(Go 阻塞队列) | 版本 3(Redis Stream) |
|---|---|---|
| 消息存储 | 内存 | Redis 持久化 |
| 服务重启 | 丢失订单 | 不丢失 |
| 消息确认 | 无 | ACK 机制 |
| 消费者管理 | 手动管理 | 消费者组自动管理 |
| 失败重试 | 需要自己实现 | Pending 消息自动重试 |
7.4 项目中的完整 Lua 脚本实现
-- ===========================================
-- 秒杀优惠券Lua脚本
-- 功能:原子性地完成秒杀资格判断和订单消息发送
-- ===========================================
-- 1. 参数列表
-- ARGV[1]: 优惠券ID
-- ARGV[2]: 用户ID
-- ARGV[3]: 订单ID
local voucherId = ARGV[1]
local userId = ARGV[2]
local orderId = ARGV[3]
-- 2. 数据Key定义
-- 2.1 库存key:存储当前库存数量
local stockKey = "cache:seckill_voucher:stock:" .. voucherId
-- 2.2 订单key:存储已购买用户集合(Set类型)
local orderKey = "cache:seckill_voucher:order:" .. voucherId
-- 2.3 秒杀券信息key:存储秒杀券详细信息(Hash类型)
local voucherKey = "cache:seckill_voucher:" .. voucherId
-- 3. 获取秒杀券信息
-- 使用hgetall获取所有字段
local voucherInfo = redis.call('hgetall', voucherKey)
if not voucherInfo or #voucherInfo == 0 then
return 3 -- 秒杀券不存在
end
-- 4. 获取当前时间(秒)
-- redis.call('time')返回两个值:秒和微秒
local timeArray = redis.call('time')
local currentTime = timeArray[1]
-- 5. 业务逻辑判断
-- 5.1 判断库存是否充足
-- 使用get获取库存值,tonumber转换为数字
if tonumber(redis.call('get', stockKey)) <= 0 then
return 1 -- 库存不足
end
-- 5.2 判断用户是否重复下单
-- 使用sismember检查用户是否在已购买集合中
-- 返回1表示存在,0表示不存在
if redis.call('sismember', orderKey, userId) == 1 then
return 2 -- 不能重复购买
end
-- 5.3 判断秒杀时间
-- 从Hash中获取开始时间和结束时间
local beginTime = tonumber(voucherInfo['begin_time'])
local endTime = tonumber(voucherInfo['end_time'])
if currentTime < beginTime then
return 4 -- 秒杀尚未开始
end
if currentTime > endTime then
return 5 -- 秒杀已结束
end
-- 6. 执行秒杀操作
-- 6.1 扣减库存
-- 使用incrby原子性地减少库存
redis.call('incrby', stockKey, -1)
-- 6.2 记录已购买用户
-- 使用sadd将用户添加到已购买集合
redis.call('sadd', orderKey, userId)
-- 6.3 设置订单集合过期时间(7天)
-- 避免数据永久占用内存
redis.call('expire', orderKey, 7 * 24 * 3600)
-- 6.4 发送订单消息到Stream
-- 使用xadd命令将订单信息发送到消息队列
-- '*'表示由Redis自动生成消息ID
redis.call('xadd', 'stream.orders', '*',
'userId', userId,
'voucherId', voucherId,
'id', orderId)
-- 7. 返回成功
return 0返回值说明:
| 返回值 | 含义 | 前端提示 |
|---|---|---|
| 0 | 成功 | 秒杀成功,订单处理中… |
| 1 | 库存不足 | 库存不足 |
| 2 | 重复购买 | 不能重复购买 |
| 3 | 秒杀券不存在 | 秒杀券不存在 |
| 4 | 未开始 | 秒杀尚未开始 |
| 5 | 已结束 | 秒杀已结束 |
7.5 消费者组详细实现
来源:service/voucher_order_service.go
消费者组配置
package service
import (
"context"
"fmt"
"hm-dianping-go/dao"
"hm-dianping-go/models"
"hm-dianping-go/utils"
"log"
"strconv"
"sync"
"time"
"github.com/go-redis/redis/v8"
)
// Stream配置常量
const (
StreamKey = "stream.orders" // Stream名称
GroupName = "order-group" // 消费者组名称
ConsumerCount = 3 // 消费者数量
)
// 全局变量
var (
streamOnce sync.Once // 确保只初始化一次
stopChan = make(chan struct{}) // 停止信号通道
wg sync.WaitGroup // 等待组,用于优雅关闭
)
// StreamOrderInfo Redis Stream中的订单信息结构体
type StreamOrderInfo struct {
UserID string `json:"userId"` // 用户ID
VoucherID string `json:"voucherId"` // 优惠券ID
OrderID string `json:"id"` // 订单ID
}
// InitStreamConsumer 初始化Redis Stream消费者
// 使用sync.Once确保只初始化一次
func InitStreamConsumer() error {
var initErr error
streamOnce.Do(func() {
ctx := context.Background()
// 1. 检查Stream是否存在
exists, err := checkStreamExists(ctx, StreamKey)
if err != nil {
initErr = fmt.Errorf("检查Stream失败: %v", err)
return
}
// 2. 如果Stream不存在,创建一个空的Stream
if !exists {
// 通过添加临时消息创建Stream
result := dao.Redis.XAdd(ctx, &redis.XAddArgs{
Stream: StreamKey,
ID: "*", // 自动生成ID
Values: map[string]interface{}{"init": "temp"},
})
if result.Err() != nil {
initErr = fmt.Errorf("创建Stream失败: %v", result.Err())
return
}
// 删除临时消息
dao.Redis.XDel(ctx, StreamKey, result.Val())
}
// 3. 创建消费者组
// XGroupCreateMkStream: 如果Stream不存在则创建
// "0": 从头开始消费所有消息
err = dao.Redis.XGroupCreateMkStream(ctx, StreamKey, GroupName, "0").Err()
if err != nil && err.Error() != "BUSYGROUP Consumer Group name already exists" {
initErr = fmt.Errorf("创建消费者组失败: %v", err)
return
}
// 4. 启动多个消费者goroutine
for i := 0; i < ConsumerCount; i++ {
consumerName := fmt.Sprintf("consumer-%d", i)
wg.Add(1)
go streamConsumer(consumerName, i)
}
log.Printf("Redis Stream消费者初始化完成,Stream: %s, 消费者组: %s, 消费者数量: %d",
StreamKey, GroupName, ConsumerCount)
})
return initErr
}
// checkStreamExists 检查Stream是否存在
func checkStreamExists(ctx context.Context, streamKey string) (bool, error) {
result := dao.Redis.Exists(ctx, streamKey)
if result.Err() != nil {
return false, result.Err()
}
return result.Val() > 0, nil
}消费者实现
// streamConsumer Stream消费者worker
// 每个消费者独立运行,从Stream中读取并处理消息
func streamConsumer(consumerName string, workerID int) {
defer wg.Done() // 函数退出时通知WaitGroup
log.Printf("Stream消费者 %s (Worker %d) 启动", consumerName, workerID)
ctx := context.Background()
for {
select {
case <-stopChan:
// 收到停止信号,退出循环
log.Printf("Stream消费者 %s (Worker %d) 收到停止信号,正在退出",
consumerName, workerID)
return
default:
// 从Stream中读取消息
messages, err := readStreamMessages(ctx, consumerName)
if err != nil {
log.Printf("消费者 %s 读取消息失败: %v", consumerName, err)
time.Sleep(time.Second * 2) // 出错时等待2秒再重试
continue
}
// 处理每条消息
for _, msg := range messages {
err := processStreamMessage(ctx, msg, consumerName)
if err != nil {
log.Printf("消费者 %s 处理消息失败: msgID=%s, error=%v",
consumerName, msg.ID, err)
// 消息处理失败,不确认ACK,后续会重新消费
} else {
log.Printf("消费者 %s 成功处理消息: msgID=%s",
consumerName, msg.ID)
// 确认消息已处理
dao.Redis.XAck(ctx, StreamKey, GroupName, msg.ID)
}
}
// 如果没有消息,短暂休眠避免空转
if len(messages) == 0 {
time.Sleep(time.Millisecond * 100)
}
}
}
}
// readStreamMessages 从Stream中读取消息
// 实现了Pending消息优先和新消息读取的逻辑
func readStreamMessages(ctx context.Context, consumerName string) ([]redis.XMessage, error) {
// 1. 首先尝试读取pending消息(之前未确认的消息)
// 这是为了处理消费者崩溃后消息恢复的场景
pendingResult := dao.Redis.XReadGroup(ctx, &redis.XReadGroupArgs{
Group: GroupName,
Consumer: consumerName,
Streams: []string{StreamKey, "0"}, // "0"表示读取pending消息
Count: 10, // 每次最多读取10条
Block: 0, // 不阻塞
})
// 如果有pending消息,直接返回
if pendingResult.Err() == nil && len(pendingResult.Val()) > 0 &&
len(pendingResult.Val()[0].Messages) > 0 {
return pendingResult.Val()[0].Messages, nil
}
// 忽略redis.Nil错误(表示没有pending消息)
if pendingResult.Err() != nil && pendingResult.Err() != redis.Nil {
return nil, pendingResult.Err()
}
// 2. 读取新消息
// 使用">"表示读取从未被消费过的新消息
result := dao.Redis.XReadGroup(ctx, &redis.XReadGroupArgs{
Group: GroupName,
Consumer: consumerName,
Streams: []string{StreamKey, ">"}, // ">"表示读取新消息
Count: 10, // 每次最多读取10条
Block: time.Second * 2, // 阻塞等待2秒
})
if result.Err() != nil {
// redis.Nil表示没有新消息,返回空切片
if result.Err() == redis.Nil {
return []redis.XMessage{}, nil
}
return nil, result.Err()
}
// 返回消息列表
if len(result.Val()) > 0 && len(result.Val()[0].Messages) > 0 {
return result.Val()[0].Messages, nil
}
return []redis.XMessage{}, nil
}消息处理实现
// processStreamMessage 处理单条Stream消息
func processStreamMessage(ctx context.Context, msg redis.XMessage, consumerName string) error {
// 1. 解析消息内容
orderInfo, err := parseOrderMessage(msg)
if err != nil {
return fmt.Errorf("解析消息失败: %v", err)
}
// 2. 转换字符串ID为uint
userID, err := strconv.ParseUint(orderInfo.UserID, 10, 32)
if err != nil {
return fmt.Errorf("解析用户ID失败: %v", err)
}
voucherID, err := strconv.ParseUint(orderInfo.VoucherID, 10, 32)
if err != nil {
return fmt.Errorf("解析优惠券ID失败: %v", err)
}
// 3. 处理订单(写入数据库)
return processStreamOrder(ctx, uint(userID), uint(voucherID), orderInfo.OrderID)
}
// parseOrderMessage 解析订单消息
// 从XMessage中提取订单信息
func parseOrderMessage(msg redis.XMessage) (*StreamOrderInfo, error) {
orderInfo := &StreamOrderInfo{}
// 从消息Values中提取字段
// msg.Values是一个map[string]interface{}
// 提取userId
if userID, ok := msg.Values["userId"].(string); ok {
orderInfo.UserID = userID
} else {
return nil, fmt.Errorf("消息中缺少userId字段")
}
// 提取voucherId
if voucherID, ok := msg.Values["voucherId"].(string); ok {
orderInfo.VoucherID = voucherID
} else {
return nil, fmt.Errorf("消息中缺少voucherId字段")
}
// 提取orderId
if orderID, ok := msg.Values["id"].(string); ok {
orderInfo.OrderID = orderID
} else {
return nil, fmt.Errorf("消息中缺少id字段")
}
return orderInfo, nil
}
// processStreamOrder 处理Stream中的订单
// 将订单信息写入MySQL数据库
func processStreamOrder(ctx context.Context, userID, voucherID uint, orderID string) error {
// 开始数据库事务
tx := dao.DB.Begin()
if tx.Error != nil {
return fmt.Errorf("开始事务失败: %v", tx.Error)
}
// 使用defer处理panic
defer func() {
if r := recover(); r != nil {
tx.Rollback()
log.Printf("订单处理发生panic: %v", r)
}
}()
// 创建订单对象
now := time.Now()
order := &models.VoucherOrder{
UserID: userID,
VoucherID: voucherID,
PayType: 1, // 支付类型:1-在线支付
Status: 1, // 订单状态:1-未支付
CreateTime: &now,
VoucherType: 2, // 券类型:2-秒杀券
}
// 创建订单记录
err := dao.CreateVoucherOrder(ctx, tx, order)
if err != nil {
tx.Rollback()
return fmt.Errorf("创建订单失败: %v", err)
}
// 提交事务
if err := tx.Commit().Error; err != nil {
tx.Rollback()
return fmt.Errorf("提交事务失败: %v", err)
}
log.Printf("成功创建订单: userID=%d, voucherID=%d, orderID=%d",
userID, voucherID, order.ID)
return nil
}
// StopStreamConsumer 停止Stream消费者
// 用于优雅关闭
func StopStreamConsumer() {
close(stopChan) // 发送停止信号
wg.Wait() // 等待所有消费者退出
log.Println("所有Stream消费者已停止")
}7.6 Stream 消息队列的优势
| 特性 | 说明 | 优势 |
|---|---|---|
| 持久化 | 消息存储在 Redis,服务重启不丢失 | 数据安全 |
| 消费者组 | 多消费者负载均衡,消息只被消费一次 | 高性能、高可用 |
| 消息确认 | ACK 机制确保消息不丢失 | 可靠性 |
| Pending 消息 | 未确认的消息可重新消费 | 容错性 |
| 阻塞读取 | 支持阻塞等待新消息 | 实时性 |
| 消息 ID | 自动生成有序的消息 ID | 有序性 |
7.7 Stream 相关命令详解
| 命令 | 说明 | 示例 |
|---|---|---|
XADD | 添加消息到 Stream | XADD stream.orders * userId 1 voucherId 100 |
XREAD | 读取消息 | XREAD STREAMS stream.orders 0 |
XREADGROUP | 消费者组读取 | XREADGROUP GROUP order-group consumer-1 STREAMS stream.orders > |
XACK | 确认消息 | XACK stream.orders order-group 1679433600000-0 |
XGROUP CREATE | 创建消费者组 | XGROUP CREATE stream.orders order-group 0 MKSTREAM |
XPENDING | 查看 pending 消息 | XPENDING stream.orders order-group |
XINFO | 查看 Stream 信息 | XINFO STREAM stream.orders |
XDEL | 删除消息 | XDEL stream.orders 1679433600000-0 |
XTRIM | 修剪 Stream 长度 | XTRIM stream.orders MAXLEN 1000 |
7.8 消费者组工作原理
┌─────────────────────────────────────────────────────────────┐
│ 消费者组工作流程 │
└─────────────────────────────────────────────────────────────┘
┌─────────────────┐
│ Stream队列 │
│ stream.orders │
└────────┬────────┘
│
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ consumer-0 │ │ consumer-1 │ │ consumer-2 │
│ │ │ │ │ │
│ 处理消息1,4,7 │ │ 处理消息2,5,8 │ │ 处理消息3,6,9 │
└───────────────┘ └───────────────┘ └───────────────┘
│ │ │
└────────────────┼────────────────┘
│
▼
┌─────────────────┐
│ 数据库写入 │
└─────────────────┘
说明:
1. 消息会被自动分配给不同的消费者
2. 同一条消息只会被一个消费者处理
3. 消费者崩溃后,pending消息会被重新分配八、总结
8.1 秒杀系统演进路线
┌─────────────────────────────────────────────────────────────┐
│ 秒杀系统技术演进 │
└─────────────────────────────────────────────────────────────┘
阶段1: 数据库事务方案
│
│ 优点:实现简单,强一致性
│ 缺点:性能差,存在超卖问题
│
▼
阶段2: 乐观锁方案
│
│ 优点:解决超卖问题,性能提升
│ 缺点:一人一单问题,集群并发问题
│
▼
阶段3: 分布式锁方案
│
│ 优点:解决集群并发问题
│ 缺点:性能瓶颈,锁竞争严重
│
▼
阶段4: Redis + 内存队列方案
│
│ 优点:高性能,快速响应
│ 缺点:内存队列不持久化,服务重启丢消息
│
▼
阶段5: Redis Stream消息队列方案(最终方案)
│
│ 优点:高性能、高可靠、支持持久化
│ 缺点:实现复杂度较高
│
▼
✓ 生产可用方案8.2 关键技术点总结
| 问题 | 解决方案 | 核心原理 |
|---|---|---|
| 全局唯一 ID | 雪花算法 / Redis 自增 | 时间戳 + 机器 ID + 序列号 |
| 超卖问题 | 乐观锁 CAS / Redis 原子操作 | 原子性更新,检查与更新同时进行 |
| 一人一单 | 唯一索引 / 分布式锁 | 数据库约束 / Redis SETNX |
| 集群并发 | 分布式锁 | 跨进程互斥 |
| 性能优化 | Redis 缓存 + 异步处理 | 内存操作 + 削峰填谷 |
| 数据可靠性 | Redis Stream 消息队列 | 持久化 + ACK 机制 |
8.3 项目文件索引
| 文件路径 | 功能说明 | 核心内容 |
|---|---|---|
| utils/snowflake.go | 雪花算法 ID 生成器 | 64 位 ID 生成,支持分布式 |
| utils/redis_id_worker.go | Redis 自增 ID 生成器 | 基于 INCR 的 ID 生成 |
| utils/lock.go | 分布式锁实现 | SETNX + Lua 脚本释放 |
| script/seckill.lua | 秒杀 Lua 脚本 | 原子性秒杀逻辑 |
| service/voucher_order_service.go | 秒杀业务逻辑 | Stream 消费者实现 |
| dao/seckill_voucher.go | 秒杀券数据访问 | 数据库 CRUD 操作 |
| dao/voucher_order.go | 订单数据访问 | 订单 CRUD 操作 |
| handler/voucher_order_handler.go | 秒杀接口处理 | HTTP 请求处理 |
| models/seckill_voucher.go | 秒杀券模型 | 数据结构定义 |
| models/voucher_order.go | 订单模型 | 数据结构定义 |
九、附录
9.1 Redis 命令速查表
| 命令 | 说明 | 使用场景 |
|---|---|---|
SET key value NX EX seconds | 设置带过期时间的键(不存在时) | 分布式锁 |
INCR key | 自增 | ID 生成、计数器 |
SADD key member | 添加集合成员 | 已购买用户集合 |
SISMEMBER key member | 判断是否在集合中 | 一人一单检查 |
HSET key field value | 设置 Hash 字段 | 存储秒杀券信息 |
HGET key field | 获取 Hash 字段 | 查询秒杀券信息 |
XADD stream * field value | 添加 Stream 消息 | 发送订单消息 |
XREADGROUP GROUP group consumer STREAMS stream > | 消费者组读取 | 消费订单消息 |
XACK stream group id | 确认消息 | 消息处理完成 |
EVAL script numkeys key arg | 执行 Lua 脚本 | 原子操作 |
9.2 常见面试题
Q1: 为什么使用 Redis 而不是数据库锁?
A: Redis 是内存操作,性能远高于数据库。在高并发场景下,数据库锁会成为瓶颈。
Q2: Lua 脚本有什么优势?
A: Lua 脚本在 Redis 中是原子执行的,可以保证多个操作的原子性,避免并发问题。
Q3: 如何解决锁误删问题?
A: 使用唯一标识作为锁值,释放时检查锁值是否匹配,使用 Lua 脚本保证原子性。
Q4: Redis Stream 相比内存队列有什么优势?
A: Redis Stream 支持持久化、消费者组、消息确认等特性,消息不会丢失,支持多消费者负载均衡。
Q5: 如何保证消息不重复消费?
A: 使用数据库唯一索引去重,或使用 Redis 记录已处理的消息 ID。
文档版本: v1.0
最后更新: 2026-03-27
项目地址: hm-dianping-go
Redis 实战篇-附近商铺
一、GEO 数据结构基本用法
1.1 什么是 GEO
GEO(Geospatial)是 Redis 3.2 版本引入的地理位置数据结构,用于存储和查询地理位置信息。它基于 Sorted Set 实现,提供了丰富的地理位置操作功能。
1.2 GEO 的核心概念
| 概念 | 说明 |
|---|---|
| 经度(Longitude) | 东西方向的位置,范围:-180 到 180 |
| 纬度(Latitude) | 南北方向的位置,范围:-85.05112878 到 85.05112878 |
| 距离单位 | m(米)、km(千米)、mi(英里)、ft(英尺) |
| 成员名称 | 地理位置的唯一标识,通常使用 ID |
1.3 GEO 常用命令
1.3.1 GEOADD - 添加地理位置
语法:
GEOADD key [NX|XX] [CH] longitude latitude member [longitude latitude member ...]参数说明:
key:GEO 集合的键名longitude:经度latitude:纬度member:成员名称(位置标识)NX:只添加不存在的成员XX:只更新已存在的成员CH:返回被修改的成员数量
示例:
# 添加单个位置
GEOADD shops:food 116.397128 39.916527 "shop:1"
# 批量添加多个位置
GEOADD shops:food 116.407526 39.904030 "shop:2" 116.417526 39.914030 "shop:3"Go 代码示例:
err := rdb.GeoAdd(ctx, "shops:food", &redis.GeoLocation{
Name: "shop:1",
Latitude: 39.916527,
Longitude: 116.397128,
}).Err()1.3.2 GEOPOS - 获取地理位置
语法:
GEOPOS key member [member ...]示例:
GEOPOS shops:food "shop:1"返回结果:
1) 1) "116.397128"
2) "39.916527"1.3.3 GEODIST - 计算两点距离
语法:
GEODIST key member1 member2 [unit]示例:
# 计算两个店铺的距离(默认米)
GEODIST shops:food "shop:1" "shop:2"
# 计算距离,单位为千米
GEODIST shops:food "shop:1" "shop:2" km1.3.4 GEORADIUS - 查询指定范围内的位置
语法:
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]参数说明:
longitude latitude:中心点的经纬度radius:半径m|km|ft|mi:距离单位WITHCOORD:返回经纬度WITHDIST:返回距离WITHHASH:返回 geohashCOUNT count:限制返回数量ASC|DESC:按距离排序
示例:
# 查询5公里内的店铺,返回距离和经纬度,按距离升序排列
GEORADIUS shops:food 116.397128 39.916527 5 km WITHDIST WITHCOORD COUNT 10 ASC1.3.5 GEORADIUSBYMEMBER - 查询指定成员范围内的位置
语法:
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]示例:
# 查询shop:1周围5公里内的店铺
GEORADIUSBYMEMBER shops:food "shop:1" 5 km WITHDIST COUNT 101.3.6 GEOHASH - 获取 geohash
语法:
GEOHASH key member [member ...]示例:
GEOHASH shops:food "shop:1"1.3.7 GEOSEARCH - 高级地理位置搜索(Redis 6.2+)
语法:
GEOSEARCH key [FROMMEMBER member] [FROMLONLAT longitude latitude] [BYRADIUS radius m|km|ft|mi] [BYBOX width height m|km|ft|mi] [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]示例:
# 查询指定坐标5公里内的店铺
GEOSEARCH shops:food FROMLONLAT 116.397128 39.916527 BYRADIUS 5 km COUNT 10Go 代码示例:
result, err := rdb.GeoSearch(ctx, "shops:food", &redis.GeoSearchQuery{
Latitude: 39.916527,
Longitude: 116.397128,
Radius: 5,
RadiusUnit: "km",
Count: 10,
}).Result()1.4 GEO 的应用场景
| 场景 | 说明 |
|---|---|
| 附近商铺 | 查找用户附近的商铺、餐厅等 |
| 打车服务 | 查找附近的司机 |
| 社交应用 | 查找附近的人 |
| 物流配送 | 查找最近的配送点 |
| 位置签到 | 记录用户签到位置 |
二、导入店铺数据到 GEO
2.1 数据库表结构
CREATE TABLE `tb_shop` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) NOT NULL COMMENT '商铺名称',
`type_id` bigint unsigned NOT NULL COMMENT '商铺类型',
`images` varchar(255) DEFAULT NULL COMMENT '商铺图片',
`area` varchar(255) DEFAULT NULL COMMENT '商圈',
`address` varchar(255) DEFAULT NULL COMMENT '地址',
`x` double DEFAULT NULL COMMENT '经度',
`y` double DEFAULT NULL COMMENT '纬度',
`avg_price` int DEFAULT NULL COMMENT '均价',
`sold` int DEFAULT '0' COMMENT '销量',
`comments` int DEFAULT '0' COMMENT '评论数',
`score` int DEFAULT '0' COMMENT '评分',
`open_hours` varchar(255) DEFAULT NULL COMMENT '营业时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`deleted_at` datetime DEFAULT NULL COMMENT '逻辑删除时间',
PRIMARY KEY (`id`),
KEY `idx_type_id` (`type_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商铺表';关键字段说明:
x:经度(Longitude)y:纬度(Latitude)type_id:商铺类型 ID,用于分类存储
2.2 导入数据到 Redis
2.2.1 DAO 层实现
文件位置: dao/shop.go
// LoadShopData 加载店铺地理位置数据到缓存,按照类型进行存到不同key当中
func LoadShopData(ctx context.Context, db *gorm.DB, rds *redis.Client) error {
// 1. 查询所有的店铺
var shops []models.Shop
err := db.WithContext(ctx).Model(&models.Shop{}).Find(&shops).Error
if err != nil {
return fmt.Errorf("failed to query shops: %w", err)
}
// 2. 遍历店铺,根据类型进行缓存
for _, shop := range shops {
// 2.1 使用 GEOADD 存储店铺位置信息
err = rds.GeoAdd(ctx, ShopLocationCache+strconv.Itoa(int(shop.TypeID)), &redis.GeoLocation{
Name: strconv.Itoa(int(shop.ID)),
Latitude: shop.Y,
Longitude: shop.X,
}).Err()
if err != nil {
return fmt.Errorf("failed to set geo cache: %w", err)
}
}
return nil
}关键点说明:
-
按类型分类存储
- Key 格式:
cache:shop:location:{typeId} - 例如:
cache:shop:location:1(美食类)、cache:shop:location:2(娱乐类) - 这样可以只查询同类型的店铺,提高查询效率
- Key 格式:
-
使用店铺 ID 作为成员名称
- 将店铺 ID 转换为字符串作为 GEO 的 member
- 方便后续根据 ID 查询店铺详细信息
-
批量导入
- 一次性查询所有店铺
- 遍历添加到 Redis
- 适合数据量不大的场景
2.2.2 在 main.go 中初始化
文件位置: main.go
func main() {
// ... 其他初始化代码 ...
// 初始化地理位置数据到redis
if err := dao.LoadShopData(context.Background(), dao.DB, dao.Redis); err != nil {
log.Fatalf("Failed to load shop locations: %v", err)
}
// ... 启动服务器 ...
}执行流程:
启动应用
↓
查询数据库所有商铺
↓
遍历每个商铺
↓
根据商铺类型分类
↓
使用GEOADD添加到Redis
↓
Key: cache:shop:location:{typeId}
Member: {shopId}
Location: (longitude, latitude)2.3 数据导入示例
假设有以下商铺数据:
| ID | 名称 | 类型 ID | 经度 | 纬度 |
|---|---|---|---|---|
| 1 | 北京烤鸭店 | 1 | 116.397128 | 39.916527 |
| 2 | 火锅店 | 1 | 116.407526 | 39.904030 |
| 3 | KTV | 2 | 116.417526 | 39.914030 |
导入后 Redis 中的数据结构:
cache:shop:location:1 (美食类)
├── shop:1 → (116.397128, 39.916527)
└── shop:2 → (116.407526, 39.904030)
cache:shop:location:2 (娱乐类)
└── shop:3 → (116.417526, 39.914030)2.4 数据更新策略
当商铺信息更新时,需要同步更新 Redis 中的地理位置数据:
// 更新商铺时同步更新GEO数据
func UpdateShop(ctx context.Context, db *gorm.DB, rds *redis.Client, shop *models.Shop) error {
// 1. 更新数据库
err := db.WithContext(ctx).Save(shop).Error
if err != nil {
return err
}
// 2. 更新Redis GEO数据
err = rdb.GeoAdd(ctx, ShopLocationCache+strconv.Itoa(int(shop.TypeID)), &redis.GeoLocation{
Name: strconv.Itoa(int(shop.ID)),
Latitude: shop.Y,
Longitude: shop.X,
}).Err()
return err
}三、实现附近商户功能
3.1 功能需求
用户在查看某个商铺时,可以查询该商铺附近的其他同类型商铺。
需求分析:
- 输入:商铺 ID、查询半径、返回数量
- 输出:附近商铺的 ID 列表
- 限制:只查询同类型的商铺
- 排序:按距离升序排列
3.2 API 接口设计
接口地址: GET /api/shop/:id/nearby
请求参数:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | path | 是 | 商铺 ID |
| radius | query | 否 | 查询半径(千米),默认 1.0 |
| count | query | 否 | 返回数量,默认 10 |
请求示例:
GET /api/shop/1/nearby?radius=5&count=10响应示例:
{
"success": true,
"errorMessage": null,
"data": [2, 3, 5, 8, 10]
}3.3 Handler 层实现
文件位置: handler/shop_handler.go
// GetNearbyShops 获取某个店铺的附近某个距离的所有点
func GetNearbyShops(c *gin.Context) {
// 1. 参数校验
idStr := c.Param("id")
id, err := strconv.ParseUint(idStr, 10, 32)
if err != nil {
utils.ErrorResponse(c, http.StatusBadRequest, "无效的商铺ID")
return
}
radius, err := strconv.ParseFloat(c.DefaultQuery("radius", "1.0"), 64)
if err != nil {
utils.ErrorResponse(c, http.StatusBadRequest, "无效的半径")
return
}
count, err := strconv.Atoi(c.DefaultQuery("count", "10"))
if err != nil {
utils.ErrorResponse(c, http.StatusBadRequest, "无效的数量")
return
}
// 2. 查询附近的商铺
result := service.GetNearbyShops(c.Request.Context(), uint(id), radius, count)
utils.Response(c, result)
}参数处理:
- 从 URL 路径中获取商铺 ID
- 从查询参数中获取半径和数量
- 设置默认值:radius=1.0km,count=10
3.4 Service 层实现
文件位置: service/shop_service.go
// GetNearbyShops 获取某个店铺的附近某个距离的所有点
func GetNearbyShops(ctx context.Context, shopId uint, radius float64, count int) *utils.Result {
// 1. 查询店铺
shop, err := dao.GetShopById(ctx, dao.DB, shopId)
if err != nil {
return utils.ErrorResult("查询店铺失败: " + err.Error())
}
// 2. 查询附近的同类型商铺
shopIds, err := dao.GetNearbyShops(ctx, dao.Redis, shop, radius, "km", count)
if err != nil {
return utils.ErrorResult("查询附近商铺失败: " + err.Error())
}
// 3. 返回结果
return utils.SuccessResultWithData(shopIds)
}处理流程:
- 根据商铺 ID 查询商铺信息(获取经纬度和类型)
- 使用 GEO 查询附近商铺
- 返回商铺 ID 列表
3.5 DAO 层实现
文件位置: dao/shop.go
// GetNearbyShops 获取某个店铺的附近某个距离的所有点
func GetNearbyShops(ctx context.Context, rds *redis.Client, shop *models.Shop, radius float64, unit string, count int) ([]uint, error) {
key := ShopLocationCache + strconv.Itoa(int(shop.TypeID))
result, err := rds.GeoSearch(ctx, key, &redis.GeoSearchQuery{
Latitude: shop.Y,
Longitude: shop.X,
Radius: radius,
RadiusUnit: unit,
Count: count,
}).Result()
if err != nil {
return nil, fmt.Errorf("failed to get geo cache: %w", err)
}
// 2. 解析结果,提取店铺ID
var shopIds []uint
for _, loc := range result {
id, _ := strconv.Atoi(loc)
shopIds = append(shopIds, uint(id))
}
return shopIds, nil
}关键点说明:
-
构建 Key
- 使用
cache:shop:location:{typeId}格式 - 只查询同类型的商铺
- 使用
-
使用 GEOSEARCH
- 以当前商铺的经纬度为中心点
- 查询指定半径内的商铺
- 限制返回数量
-
解析结果
- GEOSEARCH 返回的是成员名称(字符串形式的 ID)
- 需要转换为 uint 类型
3.6 完整调用链
用户请求: GET /api/shop/1/nearby?radius=5&count=10
↓
Handler: GetNearbyShops
├─ 参数校验
├─ id=1, radius=5, count=10
└─ 调用Service层
↓
Service: GetNearbyShops
├─ 查询商铺信息(获取经纬度和类型)
└─ 调用DAO层
↓
DAO: GetNearbyShops
├─ 构建Key: cache:shop:location:1
├─ 执行GEOSEARCH
│ └─ GEOSEARCH cache:shop:location:1 FROMLONLAT x y BYRADIUS 5 km COUNT 10
├─ 解析结果: ["2", "3", "5", "8", "10"]
└─ 返回: [2, 3, 5, 8, 10]
↓
返回给用户3.7 前端调用示例
// 获取附近商铺
async function getNearbyShops(shopId, radius = 5, count = 10) {
try {
const res = await request.get(`/shop/${shopId}/nearby`, {
params: { radius, count }
})
if (res.success) {
// res.data 是商铺ID数组
const shopIds = res.data
// 可以根据ID查询商铺详细信息
const shops = await Promise.all(
shopIds.map(id => request.get(`/shop/${id}`))
)
return shops
}
} catch (error) {
console.error('获取附近商铺失败:', error)
}
}3.8 性能优化建议
3.8.1 按类型分类存储
优点:
- 减少查询范围,提高查询速度
- 避免跨类型查询,结果更精准
- 便于数据管理和维护
实现:
// 不同类型的商铺使用不同的Key
key := "cache:shop:location:" + strconv.Itoa(int(shop.TypeID))3.8.2 合理设置查询半径
建议:
- 默认半径:1-5 公里
- 最大半径:不超过 20 公里
- 根据业务场景调整
原因:
- 半径过大:返回结果过多,用户体验差
- 半径过小:可能返回空结果
3.8.3 限制返回数量
建议:
- 默认返回:10-20 个
- 最大返回:不超过 50 个
实现:
result, err := rds.GeoSearch(ctx, key, &redis.GeoSearchQuery{
Count: count, // 限制返回数量
}).Result()3.8.4 结合缓存使用
场景:
- 查询到商铺 ID 后,需要查询商铺详细信息
- 可以从缓存中获取商铺信息,避免重复查询数据库
实现:
// 批量查询商铺信息
var shops []models.Shop
for _, id := range shopIds {
// 先从缓存查询
shop, err := dao.GetShopCacheById(ctx, rds, id)
if err == nil && shop != nil {
shops = append(shops, *shop)
continue
}
// 缓存未命中,查询数据库
shop, err = dao.GetShopById(ctx, db, id)
if err == nil {
shops = append(shops, *shop)
// 设置缓存
dao.SetShopCacheById(ctx, rds, id, shop)
}
}3.9 常见问题
Q1: GEO 查询结果包含自己吗?
A: 是的,GEO 查询会包含中心点本身。如果需要排除自己,可以在结果中过滤:
// 过滤掉自己
var filteredShopIds []uint
for _, id := range shopIds {
if id != shop.ID {
filteredShopIds = append(filteredShopIds, id)
}
}Q2: 如何按距离排序?
A: GEOSEARCH 默认按距离升序排列。如果需要获取距离信息,可以添加 WITHDIST 参数:
// 使用GEORADIUS获取距离信息
results, err := rdb.GeoRadius(ctx, key, shop.X, shop.Y, &redis.GeoRadiusQuery{
Radius: radius,
RadiusUnit: unit,
Count: count,
WithDist: true, // 返回距离
Sort: "ASC", // 升序排列
}).Result()Q3: 如何处理大量商铺数据?
A: 可以采用以下策略:
- 分片存储:按区域或类型分片
- 使用 GEORADIUSBYMEMBER:避免重复计算坐标
- 缓存热门区域:对查询频繁的区域进行缓存
- 异步加载:对不常用的区域异步加载
Q4: GEO 数据如何更新?
A: 当商铺位置信息变更时:
- 先删除旧数据(使用 ZREM)
- 再添加新数据(使用 GEOADD)
// 更新商铺位置
func UpdateShopLocation(ctx context.Context, rds *redis.Client, shop *models.Shop) error {
key := ShopLocationCache + strconv.Itoa(int(shop.TypeID))
member := strconv.Itoa(int(shop.ID))
// 删除旧数据
rds.ZRem(ctx, key, member)
// 添加新数据
return rds.GeoAdd(ctx, key, &redis.GeoLocation{
Name: member,
Latitude: shop.Y,
Longitude: shop.X,
}).Err()
}四、总结
4.1 GEO 的优势
| 优势 | 说明 |
|---|---|
| 高性能 | 基于内存,查询速度快 |
| 简单易用 | 提供丰富的地理位置命令 |
| 精度高 | 支持精确的地理位置查询 |
| 灵活 | 支持多种查询方式和排序 |
4.2 本项目 GEO 使用总结
-
数据导入
- 应用启动时批量导入商铺数据
- 按类型分类存储
- 使用 GEOADD 命令
-
附近查询
- 使用 GEOSEARCH 命令
- 支持自定义半径和数量
- 返回商铺 ID 列表
-
性能优化
- 按类型分类存储
- 限制查询范围和返回数量
- 结合缓存使用
4.3 扩展思考
-
地图可视化
- 将查询结果在地图上展示
- 显示距离和方向
-
路径规划
- 结合地图 API 规划路线
- 计算导航时间
-
推荐算法
- 基于地理位置推荐
- 结合用户偏好
-
实时定位
- 用户实时位置更新
- 动态推荐附近商铺
Redis 实战篇-用户签到
一、BitMap
1.1 什么是 BitMap
BitMap(位图)是 Redis 提供的一种基于字符串(String)数据结构的特殊用法,它将字符串看作一系列二进制位(bit),每个 bit 位可以存储 0 或 1。
1.2 BitMap 的核心概念
| 概念 | 说明 |
|---|---|
| 位(Bit) | 最小的存储单位,只能存储 0 或 1 |
| 位索引 | 从 0 开始,对应 bit 的位置 |
| 位操作 | 可以对单个或多个 bit 进行操作 |
| 内存占用 | 每个 bit 只占 1/8 字节,非常节省内存 |
1.3 BitMap 的优势
| 优势 | 说明 |
|---|---|
| 内存高效 | 1 个 bit 存储一个状态,1KB 可存储 8192 个状态 |
| 操作快速 | 位操作是 O(1)时间复杂度 |
| 统计方便 | 支持位运算,便于统计和分析 |
| 适用场景 | 适合存储二值状态(是/否、有/无) |
1.4 BitMap 的典型应用场景
| 场景 | 说明 |
|---|---|
| 用户签到 | 记录用户每天是否签到 |
| 在线状态 | 记录用户是否在线 |
| 布隆过滤器 | 快速判断元素是否存在 |
| 访问统计 | 统计用户访问过的页面 |
| 标签系统 | 记录用户拥有的标签 |
1.5 BitMap 常用命令
1.5.1 SETBIT - 设置位值
语法:
SETBIT key offset value参数说明:
key:键名offset:位偏移量(从 0 开始)value:位值(0 或 1)
示例:
# 设置第0位为1(第1天签到)
SETBIT user:sign:1:202603 0 1
# 设置第4位为1(第5天签到)
SETBIT user:sign:1:202603 4 1Go 代码示例:
err := rdb.SetBit(ctx, "user:sign:1:202603", 0, 1).Err()返回值:
- 返回该位原来的值(0 或 1)
- 如果位不存在,返回 0
1.5.2 GETBIT - 获取位值
语法:
GETBIT key offset示例:
# 获取第0位的值
GETBIT user:sign:1:202603 0
# 返回:1(表示已签到)Go 代码示例:
result, err := rdb.GetBit(ctx, "user:sign:1:202603", 0).Result()1.5.3 BITCOUNT - 统计位值为 1 的数量
语法:
BITCOUNT key [start end]示例:
# 统计整个key中1的数量(本月签到天数)
BITCOUNT user:sign:1:202603
# 统计指定范围内的1的数量
BITCOUNT user:sign:1:202603 0 10Go 代码示例:
count, err := rdb.BitCount(ctx, "user:sign:1:202603", nil).Result()1.5.4 BITOP - 位运算
语法:
BITOP operation destkey key [key ...]操作类型:
AND:按位与OR:按位或XOR:按位异或NOT:按位非
示例:
# 计算两个用户签到的交集(都签到的天数)
BITOP AND result:sign user:sign:1:202603 user:sign:2:202603
# 统计交集的签到天数
BITCOUNT result:sign1.5.5 BITPOS - 查找位值的位置
语法:
BITPOS key bit [start] [end]示例:
# 查找第一个为1的位的位置
BITPOS user:sign:1:202603 1
# 返回:0(表示第1位是1)1.6 BitMap 的存储结构
假设用户 ID 为 1,2026 年 3 月的签到情况:
Key: user:sign:1:202603
Value (二进制): 1011001000000000000000000000000000
Value (十进制): 1454028800
位索引: 0 1 2 3 4 5 6 7 8 9 ... 30
位值: 1 0 1 1 0 0 1 0 0 0 ... 0
日期: 1 2 3 4 5 6 7 8 9 10 ... 31
签到: ✓ ✗ ✓ ✓ ✗ ✗ ✓ ✗ ✗ ✗ ... ✗说明:
- 位索引 0 对应第 1 天
- 位索引 4 对应第 5 天
- 位值为 1 表示已签到,0 表示未签到
二、实现签到功能
2.1 功能需求
实现用户每日签到功能,记录用户每天的签到状态。
需求分析:
- 用户每天可以签到一次
- 防止重复签到
- 按月存储签到数据
- 支持查询签到状态
2.2 数据结构设计
2.2.1 Redis Key 设计
Key 格式: user:sign:{userID}:{month}
示例:
user:sign:1:202603- 用户 1 在 2026 年 3 月的签到数据user:sign:2:202604- 用户 2 在 2026 年 4 月的签到数据
参数说明:
userID:用户 IDmonth:月份,格式为 YYYYMM(如:202603 表示 2026 年 3 月)
2.2.2 位索引设计
位索引 = 日期 - 1
| 日期 | 位索引 | 说明 |
|---|---|---|
| 1 号 | 0 | 第 1 天对应位索引 0 |
| 2 号 | 1 | 第 2 天对应位索引 1 |
| 3 号 | 2 | 第 3 天对应位索引 2 |
| … | … | … |
| 31 号 | 30 | 第 31 天对应位索引 30 |
原因:
- Redis 的位索引从 0 开始
- 日期从 1 开始
- 所以位索引 = 日期 - 1
2.3 DAO 层实现
文件位置: dao/user.go
// ===== redis 相关
const (
SignUserKey = "user:sign:%d:%s" // sign:userID:month
)
// SignUser 签到
func SignUser(ctx context.Context, rdb *redis.Client, userID uint, month string, day int) error {
key := fmt.Sprintf(SignUserKey, userID, month)
// 设置对应位为1,day-1是因为位索引从0开始
return rdb.SetBit(ctx, key, int64(day-1), 1).Err()
}
// CheckSign 获取某个用户某个月到某一天的签到状态
func CheckSign(ctx context.Context, rdb *redis.Client, userID uint, month string, day int) (int64, error) {
key := fmt.Sprintf(SignUserKey, userID, month)
return rdb.GetBit(ctx, key, int64(day-1)).Result()
}
// GetSignData 获取某个用户某个月的签到数据
func GetSignData(ctx context.Context, rdb *redis.Client, userID uint, month string) (int64, error) {
key := fmt.Sprintf(SignUserKey, userID, month)
result, err := rdb.Get(ctx, key).Result()
if err != nil {
if err == redis.Nil {
// Key 不存在,返回 0
return 0, nil
}
return 0, err
}
return strconv.ParseInt(result, 10, 64)
}关键点说明:
-
SignUser 函数
- 使用
SETBIT命令设置对应位为 1 - 位索引为
day-1(因为位索引从 0 开始) - 如果该位已经为 1,SETBIT 会覆盖,返回原值
- 使用
-
CheckSign 函数
- 使用
GETBIT命令获取指定位的值 - 返回 0 表示未签到,1 表示已签到
- 使用
-
GetSignData 函数
- 使用
GET命令获取整个字符串的值 - 返回的是十进制数,需要转换为二进制来分析
- 如果 key 不存在,返回 0
- 使用
2.4 Service 层实现
文件位置: service/user_service.go
func Sign(ctx context.Context, userID uint) *utils.Result {
// 检查用户是否已签到
// 这里使用 redis 的 bitMap 来实现
// 1. 获取本月的日期
date := time.Now().Format("200601")
// 2. 获取今天是本月的第几天
day := time.Now().Day()
// 3. 检查今天是否已签到
signed, err := dao.CheckSign(ctx, dao.Redis, userID, date, day)
if err != nil {
return utils.ErrorResult("检查签到状态失败")
}
if signed == 1 {
return utils.ErrorResult("今天已签到")
}
// 4. 执行签到
if err := dao.SignUser(ctx, dao.Redis, userID, date, day); err != nil {
return utils.ErrorResult("签到失败")
}
return utils.SuccessResult("签到成功")
}处理流程:
- 获取当前日期和月份
- 检查今天是否已签到
- 如果未签到,执行签到操作
- 返回结果
2.5 Handler 层实现
文件位置: handler/user_handler.go
// Sign 用户签到
func Sign(c *gin.Context) {
userID, exists := c.Get("userID")
if !exists {
utils.ErrorResponse(c, http.StatusUnauthorized, "用户未登录")
return
}
result := service.Sign(c.Request.Context(), userID.(uint))
utils.Response(c, result)
}2.6 API 接口设计
接口地址: POST /api/user/sign
请求头:
Authorization: Bearer {token}请求示例:
curl -X POST http://localhost:8080/api/user/sign \
-H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9..."响应示例:
{
"success": true,
"errorMessage": null,
"data": "签到成功"
}重复签到响应:
{
"success": false,
"errorMessage": "今天已签到",
"data": null
}2.7 前端调用示例
// 用户签到
async function sign() {
try {
const res = await userApi.sign()
if (res.success) {
alert('签到成功!')
// 刷新签到状态
await getSignStatus()
} else {
alert(res.errorMessage || '签到失败')
}
} catch (error) {
console.error('签到失败:', error)
alert('签到失败,请稍后重试')
}
}2.8 完整调用链
用户请求: POST /api/user/sign
↓
Handler: Sign
├─ 从JWT中获取userID
└─ 调用Service层
↓
Service: Sign
├─ 获取当前日期: 202603
├─ 获取当前天数: 28
├─ 检查是否已签到: GETBIT user:sign:1:202603 27
│ └─ 返回: 0(未签到)
└─ 执行签到: SETBIT user:sign:1:202603 27 1
↓
返回给用户: 签到成功2.9 签到数据可视化
假设用户在 2026 年 3 月的签到情况:
日期: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
签到: ✓ ✗ ✓ ✓ ✗ ✗ ✓ ✗ ✗ ✗ ✓ ✗ ✓ ✓ ✗ ✓ ✗ ✓ ✓ ✗ ✓ ✗ ✓ ✗ ✓ ✓ ✗ ✓ ✗ ✓
位值: 1 0 1 1 0 0 1 0 0 0 1 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1 0 1 0 1
索引: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
Redis存储:
Key: user:sign:1:202603
Value: 1011001000101101011010101101010101 (二进制)
Value: 1454028800 (十进制)三、统计连续签到
3.1 功能需求
统计用户从某一天开始往前推算的连续签到天数。
需求分析:
- 从指定日期(或当天)开始往前推算
- 遇到未签到的天停止计数
- 支持查询任意月份的连续签到天数
- 返回连续签到天数
3.2 连续签到算法
3.2.1 算法思路
1. 获取整个月的签到数据(十进制数)
2. 从最后一天开始往前遍历
3. 检查每一天的签到状态
4. 遇到未签到的天,停止计数
5. 返回连续签到天数3.2.2 位运算原理
检查指定位是否为 1:
bitValue := (result >> bitIndex) & 1步骤说明:
result >> bitIndex:将数值右移 bitIndex 位& 1:与 1 进行按位与运算- 结果为 1 表示该位是 1,结果为 0 表示该位是 0
示例:
result = 1011001 (二进制) = 89 (十进制)
bitIndex = 3
步骤1: result >> 3 = 1011 (右移3位)
步骤2: 1011 & 1 = 1 (最后一位是1)
结论: 第4位(索引3)是1,表示已签到3.3 DAO 层实现
文件位置: dao/user.go
// GetSignData 获取某个用户某个月的签到数据
func GetSignData(ctx context.Context, rdb *redis.Client, userID uint, month string) (int64, error) {
key := fmt.Sprintf(SignUserKey, userID, month)
result, err := rdb.Get(ctx, key).Result()
if err != nil {
if err == redis.Nil {
// Key 不存在,返回 0
return 0, nil
}
return 0, err
}
return strconv.ParseInt(result, 10, 64)
}3.4 Service 层实现
文件位置: service/user_service.go
func CheckSign(ctx context.Context, userID uint, month string) *utils.Result {
// 检查某个月到某一天的连续签到次数
// 解析月份参数
var targetMonth string
var day int
var err error
if month == "" {
// 使用当前月
today := time.Now()
targetMonth = today.Format("200601")
day = today.Day()
} else {
// 验证月份格式
if len(month) != 6 {
return utils.ErrorResult("月份格式不正确,请使用 YYYYMM 格式")
}
// 验证月份是否有效
if month < "202001" || month > "209912" {
return utils.ErrorResult("月份超出有效范围")
}
// 获取该月的天数
yearStr := month[:4]
monthStr := month[4:]
year, _ := strconv.Atoi(yearStr)
m, _ := strconv.Atoi(monthStr)
if m < 1 || m > 12 {
return utils.ErrorResult("月份不正确")
}
// 获取该月最后一天
lastDay := time.Date(year, time.Month(m), 1, 0, 0, 0, 0, time.UTC).AddDate(0, 1, -1).Day()
// 如果月份是当前月,使用当前天数,否则使用最后一天
today := time.Now()
currentMonth := today.Format("200601")
if month == currentMonth {
day = today.Day()
} else {
day = lastDay
}
targetMonth = month
}
// 获取整个月的签到数据
result, err := dao.GetSignData(ctx, dao.Redis, userID, targetMonth)
if err != nil {
// 如果数据不存在,返回0
return utils.SuccessResultWithData(0)
}
// 计算连续签到天数(从最后一天开始往前数)
// 注意:Redis 中 bit 的索引从 0 开始,对应每个月的第 1 天
count := 0
for i := 0; i < day; i++ {
// 检查第 day-i 天是否签到
bitIndex := day - 1 - i
if bitIndex >= 0 && bitIndex < 31 {
// 右移 bitIndex 位,然后与 1 进行与运算,判断该位是否为 1
bitValue := (result >> bitIndex) & 1
if bitValue == 1 {
count++
} else {
// 遇到未签到的天,停止计数
break
}
}
}
return utils.SuccessResultWithData(count)
}关键点说明:
-
月份参数处理
- 如果不传月份,使用当前月
- 如果传了月份,验证格式和有效性
- 如果是当前月,使用当前天数;否则使用该月最后一天
-
连续签到计算
- 从最后一天开始往前遍历
- 使用位运算检查每一天的签到状态
- 遇到未签到的天,立即停止
-
边界检查
bitIndex >= 0 && bitIndex < 31:确保索引在有效范围内
3.5 Handler 层实现
文件位置: handler/user_handler.go
// CheckSign 获取用户签到状态
func CheckSign(c *gin.Context) {
userID, exists := c.Get("userID")
if !exists {
utils.ErrorResponse(c, http.StatusUnauthorized, "用户未登录")
return
}
month := c.Query("month")
if month == "" {
// 以当前月为准
month = time.Now().Format("200601")
}
result := service.CheckSign(c.Request.Context(), userID.(uint), month)
utils.Response(c, result)
}3.6 API 接口设计
接口地址: GET /api/user/sign
请求头:
Authorization: Bearer {token}请求参数:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| month | query | 否 | 月份,格式 YYYYMM,默认当前月 |
请求示例:
# 查询当前月连续签到天数
curl -X GET http://localhost:8080/api/user/sign \
-H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9..."
# 查询指定月份连续签到天数
curl -X GET "http://localhost:8080/api/user/sign?month=202603" \
-H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9..."响应示例:
{
"success": true,
"errorMessage": null,
"data": 5
}3.7 连续签到计算示例
假设今天是 2026 年 3 月 28 日,用户签到情况如下:
日期: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
签到: ✓ ✗ ✓ ✓ ✗ ✗ ✓ ✗ ✗ ✗ ✓ ✗ ✓ ✓ ✗ ✓ ✗ ✓ ✓ ✗ ✓ ✗ ✓ ✗ ✓ ✓ ✗ ✓ ✗ ✓
位值: 1 0 1 1 0 0 1 0 0 0 1 0 1 1 0 1 0 1 1 0 1 0 1 0 1 1 0 1 0 1
索引: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
连续签到计算(从28号往前):
第1步: 检查28号(索引27)→ 位值=1 → 连续天数=1
第2步: 检查27号(索引26)→ 位值=1 → 连续天数=2
第3步: 检查26号(索引25)→ 位值=0 → 停止计数
结果: 连续签到2天3.8 获取签到详情
除了统计连续签到,还可以获取整个月的签到详情。
文件位置: service/user_service.go
// GetSignDetail 获取用户月度签到详情
func GetSignDetail(ctx context.Context, userID uint, month string) *utils.Result {
// 解析月份参数
var targetMonth string
var daysInMonth int
var err error
if month == "" {
// 使用当前月
today := time.Now()
targetMonth = today.Format("200601")
daysInMonth = today.Day()
} else {
// 验证月份格式
if len(month) != 6 {
return utils.ErrorResult("月份格式不正确,请使用 YYYYMM 格式")
}
// 验证月份是否有效
if month < "202001" || month > "209912" {
return utils.ErrorResult("月份超出有效范围")
}
// 获取该月的天数
yearStr := month[:4]
monthStr := month[4:]
year, _ := strconv.Atoi(yearStr)
m, _ := strconv.Atoi(monthStr)
if m < 1 || m > 12 {
return utils.ErrorResult("月份不正确")
}
// 获取该月最后一天
lastDay := time.Date(year, time.Month(m), 1, 0, 0, 0, 0, time.UTC).AddDate(0, 1, -1).Day()
daysInMonth = lastDay
targetMonth = month
}
// 获取整个月的签到数据
result, err := dao.GetSignData(ctx, dao.Redis, userID, targetMonth)
if err != nil {
// 如果数据不存在,返回空数组
return utils.SuccessResultWithData(make([]int, daysInMonth))
}
// 构建签到详情数组
signDetail := make([]int, daysInMonth)
for i := 0; i < daysInMonth; i++ {
bitIndex := i
if bitIndex < 31 {
bitValue := (result >> bitIndex) & 1
if bitValue == 1 {
signDetail[i] = i + 1 // 返回天数(1-31)
} else {
signDetail[i] = 0 // 未签到
}
}
}
return utils.SuccessResultWithData(signDetail)
}API 接口: GET /api/user/sign/detail
响应示例:
{
"success": true,
"errorMessage": null,
"data": [1, 0, 3, 4, 0, 0, 7, 0, 0, 0, 11, 0, 13, 14, 0, 16, 0, 18, 19, 0, 21, 0, 23, 0, 25, 26, 0, 28, 0, 30]
}说明:
- 数组索引 0 对应 1 号
- 数组索引 27 对应 28 号
- 值为 0 表示未签到
- 值为日期表示已签到
3.9 前端调用示例
// 获取连续签到天数
async function getSignStatus(month) {
try {
const res = await userApi.getSignStatus(month)
if (res.success) {
return res.data // 连续签到天数
}
} catch (error) {
console.error('获取签到状态失败:', error)
}
}
// 获取签到详情
async function getSignDetail(month) {
try {
const res = await userApi.getSignDetail(month)
if (res.success) {
return res.data // 签到详情数组
}
} catch (error) {
console.error('获取签到详情失败:', error)
}
}
// 使用示例
const continuousDays = await getSignStatus('202603')
console.log(`连续签到 ${continuousDays} 天`)
const signDetails = await getSignDetail('202603')
console.log('签到详情:', signDetails)3.10 性能优化建议
3.10.1 设置过期时间
为签到数据设置过期时间,避免数据无限增长:
// 设置key的过期时间为1年
rdb.Expire(ctx, key, 365*24*time.Hour)3.10.2 使用 BITCOUNT 快速统计
使用BITCOUNT命令快速统计本月签到天数:
// 统计本月签到天数
count, err := rdb.BitCount(ctx, key, nil).Result()3.10.3 批量查询优化
如果需要查询多个用户的签到状态,可以使用BITOP进行批量操作:
# 计算多个用户签到的并集
BITOP OR result:sign user:sign:1:202603 user:sign:2:202603 user:sign:3:202603
# 统计并集的签到天数
BITCOUNT result:sign3.10.4 缓存热门数据
对频繁查询的签到数据进行缓存:
// 使用Redis缓存连续签到天数
cacheKey := fmt.Sprintf("user:sign:continuous:%d:%s", userID, month)
cached, err := rdb.Get(ctx, cacheKey).Result()
if err == nil {
// 缓存命中,直接返回
count, _ := strconv.Atoi(cached)
return utils.SuccessResultWithData(count)
}
// 缓存未命中,计算连续签到天数
// ... 计算逻辑 ...
// 设置缓存,过期时间1小时
rdb.Set(ctx, cacheKey, count, time.Hour)3.11 常见问题
Q1: 如何跨月统计连续签到?
A: 需要查询多个月的签到数据,从当前月往前推算:
func GetContinuousSignDays(ctx context.Context, userID uint) int {
count := 0
today := time.Now()
for i := 0; i < 12; i++ { // 最多查询12个月
month := today.AddDate(0, -i, 0).Format("200601")
result, _ := dao.GetSignData(ctx, rdb, userID, month)
// 从当月最后一天开始往前检查
var daysToCheck int
if i == 0 {
daysToCheck = today.Day()
} else {
daysToCheck = 31 // 最多31天
}
for j := 0; j < daysToCheck; j++ {
bitIndex := daysToCheck - 1 - j
if bitIndex >= 0 {
bitValue := (result >> bitIndex) & 1
if bitValue == 1 {
count++
} else {
return count
}
}
}
}
return count
}Q2: 如何实现签到奖励?
A: 根据连续签到天数发放奖励:
func CheckSignWithReward(ctx context.Context, userID uint) *utils.Result {
// 1. 执行签到
result := Sign(ctx, userID)
if !result.Success {
return result
}
// 2. 获取连续签到天数
continuousDays := CheckSign(ctx, userID, "")
// 3. 根据连续签到天数发放奖励
reward := calculateReward(continuousDays)
return utils.SuccessResultWithData(map[string]interface{}{
"message": "签到成功",
"continuousDays": continuousDays,
"reward": reward,
})
}
func calculateReward(days int) string {
switch {
case days >= 30:
return "30天连续签到奖励:100积分"
case days >= 21:
return "21天连续签到奖励:50积分"
case days >= 14:
return "14天连续签到奖励:20积分"
case days >= 7:
return "7天连续签到奖励:10积分"
default:
return "每日签到奖励:1积分"
}
}Q3: 如何防止用户刷签到?
A: 可以采用以下策略:
- IP 限制:限制同一 IP 的签到次数
- 设备限制:限制同一设备的签到次数
- 验证码:签到时输入验证码
- 行为分析:分析异常签到行为
// IP限制示例
func CheckSignWithIPLimit(ctx context.Context, userID uint, clientIP string) *utils.Result {
// 检查该IP今日签到次数
ipKey := fmt.Sprintf("sign:ip:%s:%s", clientIP, time.Now().Format("20060102"))
count, _ := rdb.Incr(ctx, ipKey).Result()
if count > 5 { // 每个IP每天最多5次签到
return utils.ErrorResult("今日签到次数已达上限")
}
// 设置过期时间(今天结束)
rdb.ExpireAt(ctx, ipKey, time.Now().AddDate(0, 0, 1))
// 执行签到
return Sign(ctx, userID)
}Q4: BitMap 的内存占用是多少?
A: BitMap 非常节省内存:
| 数据量 | 内存占用 |
|---|---|
| 31 天(1 个月) | 4 字节 |
| 365 天(1 年) | 46 字节 |
| 100 万用户×365 天 | 46MB |
计算公式:
内存占用(字节)= 位数 / 8示例:
- 31 天:31 / 8 = 3.875 ≈ 4 字节
- 365 天:365 / 8 = 45.625 ≈ 46 字节
四、总结
4.1 BitMap 的优势
| 优势 | 说明 |
|---|---|
| 内存高效 | 1 个 bit 存储一个状态,1KB 可存储 8192 个状态 |
| 操作快速 | 位操作是 O(1)时间复杂度 |
| 统计方便 | 支持位运算,便于统计和分析 |
| 适用场景 | 适合存储二值状态(是/否、有/无) |
4.2 本项目签到功能总结
-
数据存储
- 使用 BitMap 存储签到状态
- Key 格式:
user:sign:{userID}:{month} - 位索引:日期-1
-
签到功能
- 使用 SETBIT 命令设置签到状态
- 防止重复签到
- 按月存储数据
-
连续签到统计
- 使用 GETBIT 命令查询签到状态
- 使用位运算判断签到状态
- 从最后一天往前遍历
-
性能优化
- 设置过期时间
- 使用 BITCOUNT 快速统计
- 缓存热门数据
4.3 扩展思考
-
签到奖励系统
- 根据连续签到天数发放奖励
- 设计阶梯式奖励机制
- 实现签到排行榜
-
签到可视化
- 使用日历组件展示签到
- 标记连续签到天数
- 显示签到奖励
-
数据分析
- 统计用户签到率
- 分析签到行为模式
- 预测用户流失
-
社交功能
- 签到分享到社交平台
- 好友签到提醒
- 签到排行榜
Redis 实战篇-UV 统计
一、HyperLogLog 用法
1.1 什么是 HyperLogLog
HyperLogLog(HLL)是 Redis 2.8.9 版本引入的一种概率型数据结构,用于统计集合的基数(不重复元素的个数)。它使用极少的内存就能统计海量数据的基数。
1.2 HyperLogLog 的核心概念
| 概念 | 说明 |
|---|---|
| 基数(Cardinality) | 集合中不重复元素的个数 |
| 概率算法 | 使用概率统计方法,允许一定的误差 |
| 误差率 | 默认 0.81%,可配置 |
| 内存占用 | 12KB 固定内存,可统计 2^64 个元素 |
1.3 HyperLogLog 的优势
| 优势 | 说明 |
|---|---|
| 内存极小 | 固定 12KB 内存,可统计海量数据 |
| 高性能 | 添加和查询都是 O(1)时间复杂度 |
| 自动去重 | 自动处理重复元素 |
| 可合并 | 支持多个 HyperLogLog 合并 |
| 适用场景 | UV 统计、独立访客统计、大数据去重 |
1.4 HyperLogLog 的典型应用场景
| 场景 | 说明 |
|---|---|
| UV 统计 | 统计网站独立访客数 |
| 独立 IP 统计 | 统计独立 IP 访问数 |
| 用户行为分析 | 统计用户独立行为数 |
| 大数据去重 | 海量数据快速去重 |
| 实时统计 | 实时统计不重复元素 |
1.5 HyperLogLog 常用命令
1.5.1 PFADD - 添加元素
语法:
PFADD key element [element ...]参数说明:
key:HyperLogLog 的键名element:要添加的元素(可以添加多个)
示例:
# 添加单个元素
PFADD uv:daily:2026-03-28 "user:1"
# 批量添加多个元素
PFADD uv:daily:2026-03-28 "user:2" "user:3" "user:4"Go 代码示例:
err := rdb.PFAdd(ctx, "uv:daily:2026-03-28", "user:1").Err()返回值:
语法:
PFCOUNT key [key ...]示例:
# 统计单个HyperLogLog的基数
PFCOUNT uv:daily:2026-03-28
# 统计多个HyperLogLog的并集基数
PFCOUNT uv:daily:2026-03-28 uv:daily:2026-03-27 uv:daily:2026-03-26Go 代码示例:
count, err := rdb.PFCount(ctx, "uv:daily:2026-03-28").Result()返回值:
- 返回基数(不重复元素的个数)
1.5.3 PFMERGE - 合并 HyperLogLog
语法:
PFMERGE destkey sourcekey [sourcekey ...]示例:
# 合并两天的UV数据
PFMERGE uv:week:2026-03-22-28 uv:daily:2026-03-28 uv:daily:2026-03-27 uv:daily:2026-03-26 uv:daily:2026-03-25 uv:daily:2026-03-24 uv:daily:2026-03-23 uv:daily:2026-03-22Go 代码示例:
err := rdb.PFMerge(ctx, "uv:week:2026-03-22-28",
"uv:daily:2026-03-28",
"uv:daily:2026-03-27",
"uv:daily:2026-03-26").Err()说明:
- 将多个 HyperLogLog 合并为一个
- 合并后的基数是所有源 HyperLogLog 的并集基数
1.6 HyperLogLog 的工作原理
1.6.1 基本原理
HyperLogLog 使用概率算法来估算基数:
- 哈希映射:将每个元素通过哈希函数映射到一个很大的整数空间
- 分桶统计:将哈希值分配到多个桶(register)
- 记录前导零:每个桶记录哈希值前导零的个数
- 基数估算:根据所有桶的统计结果估算基数
1.6.2 误差率
| 配置 | 误差率 | 内存占用 |
|---|---|---|
| 默认 | 0.81% | 12KB |
| 精确配置 | 0.5% | 18KB |
| 粗略配置 | 1.6% | 8KB |
说明:
- 误差率是概率性的,不是绝对误差
- 数据量越大,相对误差越小
- 可以通过配置调整精度和内存的平衡
1.7 HyperLogLog vs 其他方案
| 方案 | 内存占用 | 精确度 | 性能 | 适用场景 |
|---|---|---|---|---|
| HyperLogLog | 12KB | 99.19% | 高 | 海量数据 UV 统计 |
| Set | N×元素大小 | 100% | 中 | 小数据量精确统计 |
| BitMap | N/8 字节 | 100% | 高 | ID 连续的统计 |
| 数据库 | N×行大小 | 100% | 低 | 需要精确统计 |
二、测试 HyperLogLog:利用单元测试,看看内存占用和统计效果
测试文件位置: test/hyperloglog_test.go
2.1 测试 1:内存占用和统计效果
测试目的: 验证 HyperLogLog 在不同数据量下的内存占用和统计精度
测试代码:
func TestHyperLogLogMemoryUsage(t *testing.T) {
ctx := context.Background()
rdb := createTestRedisClient()
defer rdb.Close()
testRedisConnection(t, rdb)
testCases := []struct {
count int
description string
}{
{1000, "1千条数据"},
{10000, "1万条数据"},
{100000, "10万条数据"},
}
for _, tc := range testCases {
t.Run(tc.description, func(t *testing.T) {
testKey := "test:hll:uv"
rdb.Del(ctx, testKey)
start := time.Now()
// 批量插入,每1000条批量发一次
var users []interface{}
for i := 0; i < tc.count; i++ {
users = append(users, fmt.Sprintf("user:%d", i))
if len(users) == 1000 {
err := rdb.PFAdd(ctx, testKey, users...).Err()
if err != nil {
t.Fatal(err)
}
users = nil
}
}
if len(users) > 0 {
rdb.PFAdd(ctx, testKey, users...)
}
cost := time.Since(start)
count, _ := rdb.PFCount(ctx, testKey).Result()
mem, _ := rdb.MemoryUsage(ctx, testKey).Result()
errRate := float64(count-int64(tc.count))/float64(tc.count)*100
fmt.Printf("【%s】\n", tc.description)
fmt.Printf(" 真实:%d 统计:%d 误差:%.2f%%\n", tc.count, count, errRate)
fmt.Printf(" 耗时:%v 内存:%d bytes\n\n", cost, mem)
rdb.Del(ctx, testKey)
})
}
}实际测试结果:
【1千条数据】
真实:1000 统计:1007 误差:0.70%
耗时:40.6687ms 内存:2616 bytes
【1万条数据】
真实:10000 统计:10089 误差:0.89%
耗时:423.9086ms 内存:14392 bytes
【10万条数据】
真实:100000 统计:99471 误差:-0.53%
耗时:4.3624364s 内存:14392 bytes关键发现:
- 内存占用极小:1 万条数据仅占用 14KB,10 万条数据仍为 14KB
- 误差率低:误差率在 0.53%-0.89%之间
- 性能优秀:10 万条数据添加只需 4.36 秒
2.2 测试 2:重复数据处理
测试目的: 验证 HyperLogLog 自动去重功能
测试代码:
func TestHyperLogLogDuplicateHandling(t *testing.T) {
ctx := context.Background()
rdb := createTestRedisClient()
defer rdb.Close()
testRedisConnection(t, rdb)
key := "test:hll:dup"
rdb.Del(ctx, key)
var users []interface{}
for i := 0; i < 100; i++ {
users = append(users, fmt.Sprintf("user:%d", i))
}
rdb.PFAdd(ctx, key, users...)
// 重复添加50个
users = nil
for i := 0; i < 50; i++ {
users = append(users, fmt.Sprintf("user:%d", i))
}
rdb.PFAdd(ctx, key, users...)
total, _ := rdb.PFCount(ctx, key).Result()
fmt.Printf("=== 重复数据测试 ===\n添加150次(100不重复) → 统计:%d\n\n", total)
rdb.Del(ctx, key)
}实际测试结果:
=== 重复数据测试 ===
添加150次(100不重复) → 统计:100关键发现:
- HyperLogLog 自动去重
- 重复添加不会影响统计结果
- 只统计不重复的元素
2.3 测试 3:合并功能
测试目的: 验证 HyperLogLog 的合并功能
测试代码:
func TestHyperLogLogPFMerge(t *testing.T) {
ctx := context.Background()
rdb := createTestRedisClient()
defer rdb.Close()
key1, key2, mergeKey := "day1", "day2", "merge"
rdb.Del(ctx, key1, key2, mergeKey)
var users []interface{}
for i := 1; i <= 50; i++ {
users = append(users, fmt.Sprintf("user:%d", i))
}
rdb.PFAdd(ctx, key1, users...)
users = nil
for i := 30; i <= 80; i++ {
users = append(users, fmt.Sprintf("user:%d", i))
}
rdb.PFAdd(ctx, key2, users...)
rdb.PFMerge(ctx, mergeKey, key1, key2)
day1, _ := rdb.PFCount(ctx, key1).Result()
day2, _ := rdb.PFCount(ctx, key2).Result()
total, _ := rdb.PFCount(ctx, mergeKey).Result()
fmt.Printf("=== 合并测试 ===\nday1:%d day2:%d merge:%d (理论80)\n\n", day1, day2, total)
rdb.Del(ctx, key1, key2, mergeKey)
}实际测试结果:
=== 合并测试 ===
day1:50 day2:51 merge:80 (理论80)关键发现:
- PFMERGE 自动去重
- 合并后的基数是所有源 HyperLogLog 的并集基数
- 适合统计多天、多周、多月的总 UV
2.4 测试 4:真实场景模拟
测试目的: 模拟真实的多日 UV 统计场景
测试代码:
func TestHyperLogLogRealScenario(t *testing.T) {
ctx := context.Background()
rdb := createTestRedisClient()
defer rdb.Close()
fmt.Println("=== 7日UV模拟 ===")
for day := 1; day <= 3; day++ {
date := time.Now().AddDate(0, 0, -day).Format("20060102")
key := "uv:day:" + date
rdb.Del(ctx, key)
var users []interface{}
for i := 0; i < 1000; i++ {
uid := fmt.Sprintf("user:%d", i)
users = append(users, uid)
}
rdb.PFAdd(ctx, key, users...)
cnt, _ := rdb.PFCount(ctx, key).Result()
fmt.Printf(" %s UV: %d\n", date, cnt)
rdb.Del(ctx, key)
}
fmt.Println()
}实际测试结果:
=== 7日UV模拟 ===
20260330 UV: 1007
20260329 UV: 1007
20260328 UV: 1007关键发现:
- HyperLogLog 能准确统计每日 UV
- 适合真实业务场景
2.5 运行测试
运行所有测试:
cd e:\CodeHub\GoStudy\hm-dianping-go
go test -v ./test -run TestHyperLogLog运行单个测试:
go test -v ./test -run TestHyperLogLogMemoryUsage三、实现 UV 统计
3.1 功能需求
实现网站 UV(独立访客)统计功能。
需求分析:
- 自动记录每次请求的 UV
- 按天统计 UV 数据
- 支持查询单日、多日 UV
- 支持查询 UV 摘要(今日、昨日、本周、本月)
3.2 数据结构设计
3.2.1 Redis Key 设计
Key 格式: uv:daily:{date}
示例:
uv:daily:2026-03-28- 2026 年 3 月 28 日的 UV 数据uv:daily:2026-03-27- 2026 年 3 月 27 日的 UV 数据
参数说明:
date:日期,格式为 YYYY-MM-DD(如:2026-03-28)
3.2.2 用户标识设计
用户标识格式:
- 登录用户:
user:{userID} - 未登录用户:
ip:{clientIP}
示例:
user:1- 用户 ID 为 1 的登录用户ip:192.168.1.1- IP 为 192.168.1.1 的访客
说明:
- 优先使用用户 ID(更精确)
- 未登录用户使用 IP(可能有误差)
- HyperLogLog 自动去重
3.3 中间件实现
文件位置: utils/middleware.go
// UVStatMiddleware UV统计中间件,使用Redis HyperLogLog实现
func UVStatMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
// 先执行请求
c.Next()
// 请求处理完成后进行UV统计
go func() {
// 获取用户标识,优先使用用户ID,其次使用IP
var userIdentifier string
// 尝试从JWT中获取用户ID
if userID, exists := c.Get("userID"); exists {
userIdentifier = fmt.Sprintf("user:%v", userID)
} else {
// 使用客户端IP作为标识
userIdentifier = fmt.Sprintf("ip:%s", c.ClientIP())
}
// 获取当前日期作为key的一部分
today := time.Now().Format("2006-01-02")
// 使用HyperLogLog记录UV
uvKey := fmt.Sprintf("uv:daily:%s", today)
// 异步记录到Redis,避免影响请求性能
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
if err := dao.Redis.PFAdd(ctx, uvKey, userIdentifier).Err(); err != nil {
// 记录错误但不影响主流程
fmt.Printf("UV统计记录失败: %v\n", err)
}
// 设置key的过期时间为7天,避免数据无限增长
dao.Redis.Expire(ctx, uvKey, 7*24*time.Hour)
}()
}
}关键点说明:
-
异步处理
- 使用 goroutine 异步记录 UV
- 不影响主请求的响应时间
- 使用 context 设置超时
-
用户标识
- 优先使用用户 ID(更精确)
- 未登录用户使用 IP(可能有误差)
- 格式:
user:{userID}或ip:{clientIP}
-
按天存储
- 每天一个独立的 HyperLogLog
- Key 格式:
uv:daily:{date} - 便于查询和统计
-
过期时间
- 设置 7 天过期时间
- 避免数据无限增长
- 可根据业务需求调整
3.4 Service 层实现
文件位置: service/stat_service.go
3.4.1 获取单日 UV
// GetDailyUV 获取指定日期的UV统计
func GetDailyUV(ctx context.Context, date string) *utils.Result {
// 验证日期格式
if _, err := time.Parse("2006-01-02", date); err != nil {
return utils.ErrorResult("日期格式错误,请使用YYYY-MM-DD格式")
}
uvKey := fmt.Sprintf("uv:daily:%s", date)
// 使用HyperLogLog获取UV数量
count, err := dao.Redis.PFCount(ctx, uvKey).Result()
if err != nil {
return utils.ErrorResult("获取UV统计失败")
}
return utils.SuccessResultWithData(map[string]interface{}{
"date": date,
"uv": count,
})
}3.4.2 获取今日 UV
// GetTodayUV 获取今日UV统计
func GetTodayUV(ctx context.Context) *utils.Result {
today := time.Now().Format("2006-01-02")
return GetDailyUV(ctx, today)
}3.4.3 获取日期范围 UV
// GetUVRange 获取指定日期范围的UV统计
func GetUVRange(ctx context.Context, startDate, endDate string) *utils.Result {
// 验证日期格式
start, err := time.Parse("2006-01-02", startDate)
if err != nil {
return utils.ErrorResult("开始日期格式错误,请使用YYYY-MM-DD格式")
}
end, err := time.Parse("2006-01-02", endDate)
if err != nil {
return utils.ErrorResult("结束日期格式错误,请使用YYYY-MM-DD格式")
}
if start.After(end) {
return utils.ErrorResult("开始日期不能晚于结束日期")
}
// 限制查询范围,避免查询过多数据
if end.Sub(start).Hours() > 24*30 { // 最多30天
return utils.ErrorResult("查询范围不能超过30天")
}
var results []map[string]interface{}
// 遍历日期范围
for d := start; !d.After(end); d = d.AddDate(0, 0, 1) {
dateStr := d.Format("2006-01-02")
uvKey := fmt.Sprintf("uv:daily:%s", dateStr)
count, err := dao.Redis.PFCount(ctx, uvKey).Result()
if err != nil {
// 如果某天的数据获取失败,记录为0
count = 0
}
results = append(results, map[string]interface{}{
"date": dateStr,
"uv": count,
})
}
return utils.SuccessResultWithData(map[string]interface{}{
"startDate": startDate,
"endDate": endDate,
"data": results,
})
}3.4.4 获取最近 N 天 UV
// GetRecentUV 获取最近N天的UV统计
func GetRecentUV(ctx context.Context, days int) *utils.Result {
if days <= 0 || days > 30 {
return utils.ErrorResult("天数必须在1-30之间")
}
endDate := time.Now()
startDate := endDate.AddDate(0, 0, -(days - 1))
return GetUVRange(ctx, startDate.Format("2006-01-02"), endDate.Format("2006-01-02"))
}3.4.5 获取 UV 摘要
// GetUVSummary 获取UV统计摘要(今日、昨日、本周、本月)
func GetUVSummary(ctx context.Context) *utils.Result {
now := time.Now()
today := now.Format("2006-01-02")
yesterday := now.AddDate(0, 0, -1).Format("2006-01-02")
// 获取今日UV
todayResult := GetDailyUV(ctx, today)
var todayUV int64 = 0
if todayResult.Success {
if data, ok := todayResult.Data.(map[string]interface{}); ok {
if uv, ok := data["uv"].(int64); ok {
todayUV = uv
}
}
}
// 获取昨日UV
yesterdayResult := GetDailyUV(ctx, yesterday)
var yesterdayUV int64 = 0
if yesterdayResult.Success {
if data, ok := yesterdayResult.Data.(map[string]interface{}); ok {
if uv, ok := data["uv"].(int64); ok {
yesterdayUV = uv
}
}
}
// 获取本周UV(周一到今天)
weekStart := now.AddDate(0, 0, -int(now.Weekday())+1)
if now.Weekday() == time.Sunday {
weekStart = now.AddDate(0, 0, -6)
}
weekResult := GetUVRange(ctx, weekStart.Format("2006-01-02"), today)
var weekUV int64 = 0
if weekResult.Success {
if data, ok := weekResult.Data.(map[string]interface{}); ok {
if dataList, ok := data["data"].([]map[string]interface{}); ok {
for _, item := range dataList {
if uv, ok := item["uv"].(int64); ok {
weekUV += uv
}
}
}
}
}
// 获取本月UV(月初到今天)
monthStart := time.Date(now.Year(), now.Month(), 1, 0, 0, 0, 0, now.Location())
monthResult := GetUVRange(ctx, monthStart.Format("2006-01-02"), today)
var monthUV int64 = 0
if monthResult.Success {
if data, ok := monthResult.Data.(map[string]interface{}); ok {
if dataList, ok := data["data"].([]map[string]interface{}); ok {
for _, item := range dataList {
if uv, ok := item["uv"].(int64); ok {
monthUV += uv
}
}
}
}
}
return utils.SuccessResultWithData(map[string]interface{}{
"today": todayUV,
"yesterday": yesterdayUV,
"thisWeek": weekUV,
"thisMonth": monthUV,
})
}3.5 Handler 层实现
文件位置: handler/stat_handler.go
// GetDailyUV 获取指定日期的UV统计
func GetDailyUV(c *gin.Context) {
date := c.Query("date")
if date == "" {
c.JSON(http.StatusBadRequest, gin.H{
"success": false,
"message": "请提供日期参数",
})
return
}
result := service.GetDailyUV(c.Request.Context(), date)
if result.Success {
c.JSON(http.StatusOK, result)
} else {
c.JSON(http.StatusBadRequest, result)
}
}
// GetTodayUV 获取今日UV统计
func GetTodayUV(c *gin.Context) {
result := service.GetTodayUV(c.Request.Context())
if result.Success {
c.JSON(http.StatusOK, result)
} else {
c.JSON(http.StatusInternalServerError, result)
}
}
// GetUVRange 获取指定日期范围的UV统计
func GetUVRange(c *gin.Context) {
startDate := c.Query("startDate")
endDate := c.Query("endDate")
if startDate == "" || endDate == "" {
c.JSON(http.StatusBadRequest, gin.H{
"success": false,
"message": "请提供开始日期和结束日期参数",
})
return
}
result := service.GetUVRange(c.Request.Context(), startDate, endDate)
if result.Success {
c.JSON(http.StatusOK, result)
} else {
c.JSON(http.StatusBadRequest, result)
}
}
// GetRecentUV 获取最近N天的UV统计
func GetRecentUV(c *gin.Context) {
daysStr := c.Query("days")
if daysStr == "" {
daysStr = "7" // 默认7天
}
days, err := strconv.Atoi(daysStr)
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{
"success": false,
"message": "天数参数格式错误",
})
return
}
result := service.GetRecentUV(c.Request.Context(), days)
if result.Success {
c.JSON(http.StatusOK, result)
} else {
c.JSON(http.StatusBadRequest, result)
}
}
// GetUVSummary 获取UV统计摘要
func GetUVSummary(c *gin.Context) {
result := service.GetUVSummary(c.Request.Context())
if result.Success {
c.JSON(http.StatusOK, result)
} else {
c.JSON(http.StatusInternalServerError, result)
}
}3.6 API 接口设计
3.6.1 获取单日 UV
接口地址: GET /api/stat/uv/daily
请求参数:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| date | query | 是 | 日期,格式 YYYY-MM-DD |
请求示例:
curl -X GET "http://localhost:8080/api/stat/uv/daily?date=2026-03-28"响应示例:
{
"success": true,
"errorMessage": null,
"data": {
"date": "2026-03-28",
"uv": 12345
}
}3.6.2 获取今日 UV
接口地址: GET /api/stat/uv/today
请求示例:
curl -X GET "http://localhost:8080/api/stat/uv/today"响应示例:
{
"success": true,
"errorMessage": null,
"data": {
"date": "2026-03-28",
"uv": 12345
}
}3.6.3 获取日期范围 UV
接口地址: GET /api/stat/uv/range
请求参数:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| startDate | query | 是 | 开始日期,格式 YYYY-MM-DD |
| endDate | query | 是 | 结束日期,格式 YYYY-MM-DD |
请求示例:
curl -X GET "http://localhost:8080/api/stat/uv/range?startDate=2026-03-22&endDate=2026-03-28"响应示例:
{
"success": true,
"errorMessage": null,
"data": {
"startDate": "2026-03-22",
"endDate": "2026-03-28",
"data": [
{
"date": "2026-03-22",
"uv": 9876
},
{
"date": "2026-03-23",
"uv": 10234
},
{
"date": "2026-03-24",
"uv": 11567
},
{
"date": "2026-03-25",
"uv": 10890
},
{
"date": "2026-03-26",
"uv": 12045
},
{
"date": "2026-03-27",
"uv": 11345
},
{
"date": "2026-03-28",
"uv": 12345
}
]
}
}3.6.4 获取最近 N 天 UV
接口地址: GET /api/stat/uv/recent
请求参数:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| days | query | 否 | 天数,默认 7,范围 1-30 |
请求示例:
curl -X GET "http://localhost:8080/api/stat/uv/recent?days=7"响应示例:
{
"success": true,
"errorMessage": null,
"data": {
"startDate": "2026-03-22",
"endDate": "2026-03-28",
"data": [
{
"date": "2026-03-22",
"uv": 9876
},
{
"date": "2026-03-23",
"uv": 10234
},
{
"date": "2026-03-24",
"uv": 11567
},
{
"date": "2026-03-25",
"uv": 10890
},
{
"date": "2026-03-26",
"uv": 12045
},
{
"date": "2026-03-27",
"uv": 11345
},
{
"date": "2026-03-28",
"uv": 12345
}
]
}
}3.6.5 获取 UV 摘要
接口地址: GET /api/stat/uv/summary
请求示例:
curl -X GET "http://localhost:8080/api/stat/uv/summary"响应示例:
{
"success": true,
"errorMessage": null,
"data": {
"today": 12345,
"yesterday": 11345,
"thisWeek": 78002,
"thisMonth": 234567
}
}3.7 完整调用链
用户请求: GET /api/stat/uv/today
↓
Handler: GetTodayUV
└─ 调用Service层
↓
Service: GetTodayUV
├─ 获取当前日期: 2026-03-28
└─ 调用GetDailyUV
↓
Service: GetDailyUV
├─ 验证日期格式
├─ 构建Key: uv:daily:2026-03-28
├─ 执行PFCOUNT: PFCOUNT uv:daily:2026-03-28
└─ 返回UV数量
↓
返回给用户: { "date": "2026-03-28", "uv": 12345 }3.8 前端调用示例
// 获取今日UV
async function getTodayUV() {
try {
const res = await request.get('/stat/uv/today')
if (res.success) {
console.log('今日UV:', res.data.uv)
return res.data
}
} catch (error) {
console.error('获取今日UV失败:', error)
}
}
// 获取日期范围UV
async function getUVRange(startDate, endDate) {
try {
const res = await request.get('/stat/uv/range', {
params: { startDate, endDate }
})
if (res.success) {
console.log('UV趋势:', res.data.data)
return res.data
}
} catch (error) {
console.error('获取UV范围失败:', error)
}
}
// 获取最近N天UV
async function getRecentUV(days = 7) {
try {
const res = await request.get('/stat/uv/recent', {
params: { days }
})
if (res.success) {
console.log('最近UV:', res.data.data)
return res.data
}
} catch (error) {
console.error('获取最近UV失败:', error)
}
}
// 获取UV摘要
async function getUVSummary() {
try {
const res = await request.get('/stat/uv/summary')
if (res.success) {
console.log('UV摘要:', res.data)
return res.data
}
} catch (error) {
console.error('获取UV摘要失败:', error)
}
}
// 使用示例
const todayUV = await getTodayUV()
console.log(`今日UV: ${todayUV.uv}`)
const weekUV = await getRecentUV(7)
console.log('本周UV:', weekUV.data.reduce((sum, item) => sum + item.uv, 0))
const summary = await getUVSummary()
console.log('UV摘要:', summary)3.9 性能优化建议
3.9.1 异步处理
实现:
// 使用goroutine异步记录UV
go func() {
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
defer cancel()
if err := dao.Redis.PFAdd(ctx, uvKey, userIdentifier).Err(); err != nil {
fmt.Printf("UV统计记录失败: %v\n", err)
}
}()优点:
- 不影响主请求的响应时间
- 即使 Redis 操作失败也不影响业务
- 提升用户体验
3.9.2 设置过期时间
实现:
// 设置key的过期时间为7天
dao.Redis.Expire(ctx, uvKey, 7*24*time.Hour)优点:
- 避免数据无限增长
- 自动清理过期数据
- 节省内存空间
3.9.3 限制查询范围
实现:
// 限制查询范围,避免查询过多数据
if end.Sub(start).Hours() > 24*30 { // 最多30天
return utils.ErrorResult("查询范围不能超过30天")
}优点:
- 避免大范围查询影响性能
- 限制单次查询的数据量
- 提升查询速度
3.9.4 使用缓存
实现:
// 缓存UV摘要数据
cacheKey := "uv:summary:today"
cached, err := rdb.Get(ctx, cacheKey).Result()
if err == nil {
// 缓存命中,直接返回
var summary map[string]interface{}
json.Unmarshal([]byte(cached), &summary)
return utils.SuccessResultWithData(summary)
}
// 缓存未命中,计算UV摘要
summary := calculateUVSummary(ctx)
// 设置缓存,过期时间5分钟
data, _ := json.Marshal(summary)
rdb.Set(ctx, cacheKey, data, 5*time.Minute)优点:
- 减少 Redis 查询次数
- 提升查询速度
- 降低 Redis 负载
3.10 常见问题
Q1: HyperLogLog 的误差率是多少?
A: HyperLogLog 的默认误差率是 0.81%,可以通过配置调整:
| 配置 | 误差率 | 内存占用 |
|---|---|---|
| 默认 | 0.81% | 12KB |
| 精确 | 0.5% | 18KB |
| 粗略 | 1.6% | 8KB |
说明:
- 误差率是概率性的,不是绝对误差
- 数据量越大,相对误差越小
- 可以根据业务需求选择配置
Q2: 如何统计多天的总 UV?
A: 有两种方法:
方法 1:遍历每天求和
var totalUV int64
for d := start; !d.After(end); d = d.AddDate(0, 0, 1) {
dateStr := d.Format("2006-01-02")
uvKey := fmt.Sprintf("uv:daily:%s", dateStr)
count, _ := dao.Redis.PFCount(ctx, uvKey).Result()
totalUV += count
}方法 2:使用 PFMERGE 合并
// 合并多天的数据
var keys []string
for d := start; !d.After(end); d = d.AddDate(0, 0, 1) {
dateStr := d.Format("2006-01-02")
keys = append(keys, fmt.Sprintf("uv:daily:%s", dateStr))
}
// 合并
mergedKey := "uv:merged:" + startDate + ":" + endDate
dao.Redis.PFMerge(ctx, mergedKey, keys...)
// 获取总UV
totalUV, _ := dao.Redis.PFCount(ctx, mergedKey).Result()比较:
- 方法 1:简单直接,但需要多次查询
- 方法 2:一次查询,但需要额外的 key 和内存
Q3: 如何处理 IP 变化的问题?
A: IP 变化会导致 UV 统计偏高,可以采用以下策略:
-
优先使用用户 ID
- 登录用户使用用户 ID
- 未登录用户才使用 IP
-
使用 Cookie/Session
- 为未登录用户分配唯一 ID
- 存储在 Cookie 或 Session 中
-
使用设备指纹
- 综合 User-Agent、IP 等信息
- 生成设备唯一标识
// 改进的用户标识获取
func getUserIdentifier(c *gin.Context) string {
// 优先使用用户ID
if userID, exists := c.Get("userID"); exists {
return fmt.Sprintf("user:%v", userID)
}
// 尝试从Cookie获取设备ID
if deviceID, err := c.Cookie("device_id"); err == nil {
return fmt.Sprintf("device:%s", deviceID)
}
// 使用IP作为标识
return fmt.Sprintf("ip:%s", c.ClientIP())
}Q4: 如何实时监控 UV?
A: 可以使用 Redis 的 Pub/Sub 功能实现实时监控:
// 发布UV更新
func publishUVUpdate(ctx context.Context, date string, uv int64) {
data := map[string]interface{}{
"date": date,
"uv": uv,
"time": time.Now().Unix(),
}
jsonData, _ := json.Marshal(data)
dao.Redis.Publish(ctx, "uv:update", jsonData)
}
// 订阅UV更新
func subscribeUVUpdate(ctx context.Context) {
pubsub := dao.Redis.Subscribe(ctx, "uv:update")
ch := pubsub.Channel()
for msg := range ch {
var data map[string]interface{}
json.Unmarshal([]byte(msg.Payload), &data)
fmt.Printf("UV更新: %+v\n", data)
}
}四、总结
4.1 HyperLogLog 的优势
| 优势 | 说明 |
|---|---|
| 内存极小 | 固定 12KB 内存,可统计海量数据 |
| 高性能 | 添加和查询都是 O(1)时间复杂度 |
| 自动去重 | 自动处理重复元素 |
| 可合并 | 支持多个 HyperLogLog 合并 |
| 适用场景 | UV 统计、独立访客统计、大数据去重 |
4.2 本项目 UV 统计总结
-
数据存储
- 使用 HyperLogLog 存储 UV 数据
- Key 格式:
uv:daily:{date} - 按天独立存储
-
自动统计
- 使用中间件自动记录 UV
- 异步处理,不影响性能
- 优先使用用户 ID,其次使用 IP
-
查询功能
- 支持单日、多日查询
- 支持 UV 摘要查询
- 限制查询范围,保证性能
-
性能优化
- 异步处理 UV 记录
- 设置过期时间
- 限制查询范围
- 使用缓存优化
4.3 扩展思考
-
UV 趋势分析
- 绘制 UV 趋势图
- 分析 UV 变化规律
- 预测 UV 走势
-
UV 对比分析
- 同比分析(今年 vs 去年)
- 环比分析(本月 vs 上月)
- 周期性分析(工作日 vs 周末)
-
UV 异常检测
- 检测 UV 异常波动
- 分析异常原因
- 及时发现问题
-
UV 预测
- 基于历史数据预测 UV
- 辅助运营决策
- 优化资源配置
Redis 高级篇-分布式缓存
一、Redis 持久化
1.1 RDB(Redis Database)
1.1.1 RDB 基本概念
RDB 是 Redis 默认的持久化方式,它通过在指定的时间间隔内生成数据集的时间点快照来实现持久化。
特点:
- 文件紧凑:RDB 文件是经过压缩的二进制文件
- 恢复速度快:直接加载 RDB 文件即可恢复数据
- 适合备份:适合用于灾难恢复
- 性能影响小:fork 子进程进行持久化,不影响主进程
1.1.2 RDB 触发机制
RDB 可以通过以下方式触发:
1. 自动触发
在 redis.conf 中配置:
# 900秒内至少有1个key发生变化
save 900 1
# 300秒内至少有10个key发生变化
save 300 10
# 60秒内至少有10000个key发生变化
save 60 10000
# 禁用RDB持久化
save ""2. 手动触发
# 同步保存,阻塞主进程
SAVE
# 异步保存,不阻塞主进程
BGSAVE3. 其他触发
- 执行 FLUSHALL 命令
- 执行 SHUTDOWN 命令
- 主从复制时,主节点自动执行 BGSAVE
1.1.3 Fork 原理
什么是 Fork?
Fork 是 Linux 系统调用,用于创建一个子进程。子进程是父进程的副本,共享父进程的内存空间。
Fork 在 RDB 中的作用:
主进程(Redis Server)
|
| fork()
|
+-------------------+
| |
父进程 子进程(RDB持久化)
继续处理请求 读取内存数据
写入RDB文件
退出Fork 的工作流程:
-
Copy-on-Write(写时复制)机制
- Fork 时,父子进程共享相同的内存页
- 内存页标记为只读
- 当父进程修改数据时,复制该内存页
- 子进程继续读取原始内存页
-
内存占用
- Fork 瞬间,子进程占用与父进程相同的虚拟内存
- 实际物理内存只增加修改的页面
- 如果数据量大,需要足够的内存
-
性能影响
- Fork 操作本身很快(毫秒级)
- 但如果数据量大,可能阻塞主进程
- 建议在低峰期执行
Fork 优化建议:
# 控制fork时的最大内存使用量
# 0表示不限制,1表示不进行fork
vm.overcommit_memory = 1
# 建议关闭THP(Transparent Huge Pages)
echo never > /sys/kernel/mm/transparent_hugepage/enabled1.1.4 RDB 文件结构
RDB 文件包含以下信息:
- Redis 版本号
- 数据库选择
- 键值对数据
- 校验和
RDB 文件命名:
- 默认:
dump.rdb - 可配置:
dbfilename dump.rdb
RDB 文件位置:
- 默认:当前工作目录
- 可配置:
dir /var/lib/redis
1.2 AOF(Append Only File)
1.2.1 AOF 基本概念
AOF 通过记录 Redis 服务器接收到的每一个写命令来实现持久化。
特点:
- 数据安全性高:可以配置每秒或每次写操作都同步
- 可读性强:AOF 文件是文本格式,可以手动修改
- 文件体积大:记录了所有写命令
- 恢复速度慢:需要重新执行所有命令
1.2.2 AOF 工作流程
写命令
|
v
命令缓冲区
|
| (根据策略)
v
AOF文件
|
| (重写)
v
AOF重写文件1.2.3 AOF 同步策略
在 redis.conf 中配置:
# 每次写操作都同步到磁盘(最安全,性能最差)
appendfsync always
# 每秒同步一次(折中方案,推荐)
appendfsync everysec
# 由操作系统决定何时同步(性能最好,可能丢失数据)
appendfsync no策略对比:
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| always | 数据最安全 | 性能最差 | 对数据安全性要求极高 |
| everysec | 性能和安全平衡 | 可能丢失 1 秒数据 | 生产环境推荐 |
| no | 性能最好 | 可能丢失大量数据 | 不推荐 |
1.2.4 AOF 重写
为什么需要 AOF 重写?
随着时间推移,AOF 文件会越来越大,因为:
- 记录了所有写命令
- 可能包含冗余命令
- 占用磁盘空间
AOF 重写原理:
AOF 重写不是读取旧的 AOF 文件,而是:
- 读取当前内存中的数据
- 生成对应的写命令
- 写入新的 AOF 文件
AOF 重写触发:
# AOF文件大小比上次重写后增长了一倍
auto-aof-rewrite-percentage 100
# AOF文件最小64MB时才触发重写
auto-aof-rewrite-min-size 64mb手动触发:
BGREWRITEAOF1.2.5 AOF 文件格式
AOF 文件是文本格式,包含 Redis 命令:
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n格式说明:
*2:命令有 2 个参数$6:参数长度为 6SELECT:参数内容\r\n:分隔符
1.3 RDB 和 AOF 对比
| 特性 | RDB | AOF |
|---|---|---|
| 持久化方式 | 快照 | 记录写命令 |
| 文件大小 | 小(压缩) | 大(记录所有命令) |
| 恢复速度 | 快 | 慢(需要重放命令) |
| 数据安全性 | 可能丢失最后一次快照数据 | 可配置为不丢失数据 |
| 性能影响 | fork 时可能阻塞 | 根据同步策略不同 |
| 文件格式 | 二进制 | 文本 |
| 适用场景 | 备份、灾难恢复 | 数据安全性要求高 |
选择建议:
-
纯 RDB:
- 数据可以容忍丢失
- 需要快速恢复
- 磁盘空间有限
-
纯 AOF:
- 数据不能丢失
- 需要可读的持久化文件
- 磁盘空间充足
-
RDB+AOF(推荐):
- 结合两者优点
- RDB 用于备份
- AOF 用于实时持久化
- 恢复时优先使用 AOF
混合持久化(Redis 4.0+):
aof-use-rdb-preamble yes- AOF 文件开头使用 RDB 格式
- 后续增量使用 AOF 格式
- 兼顾性能和数据安全
二、Redis 主从
2.1 概念和搭建
2.1.1 主从复制概念
主从复制是指将一个 Redis 服务器的数据复制到其他 Redis 服务器。
角色:
- 主节点(Master):负责写操作,数据源
- 从节点(Slave):负责读操作,数据备份
优点:
- 数据冗余:提高数据安全性
- 读写分离:提高系统吞吐量
- 故障恢复:主节点故障时,从节点可以提升为主节点
- 负载均衡:分散读请求
2.1.2 主从复制搭建
重要说明:
- 只配置从库,不用配置主库
- 默认情况下,每台 Redis 服务器都是主节点
- 一个主节点可以有多个从节点,但一个从节点只能有一个主节点
实际环境配置步骤(一主二从):
假设我们搭建一个主节点(6379)和两个从节点(6380、6381):
步骤 1:复制配置文件
# 复制3个配置文件
cp redis.conf redis-6379.conf
cp redis.conf redis-6380.conf
cp redis.conf redis-6381.conf步骤 2:修改每个配置文件
修改 redis-6379.conf(主节点):
port 6379
pidfile /var/run/redis_6379.pid
logfile "6379.log"
dbfilename dump6379.rdb修改 redis-6380.conf(从节点):
port 6380
pidfile /var/run/redis_6380.pid
logfile "6380.log"
dbfilename dump6380.rdb
# 指定主节点
replicaof 127.0.0.1 6379修改 redis-6381.conf(从节点):
port 6381
pidfile /var/run/redis_6381.pid
logfile "6381.log"
dbfilename dump6381.rdb
# 指定主节点
replicaof 127.0.0.1 6379步骤 3:启动 3 个 Redis 服务器
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf步骤 4:查看进程信息
ps -ef|grep redis
# 输出示例:
# root 426 1 0 16:53 ? 00:00:00 redis-server *:6379
# root 446 1 0 16:54 ? 00:00:00 redis-server *:6380
# root 457 1 0 16:54 ? 00:00:00 redis-server *:6381方式 1:配置文件(推荐,永久生效)
从节点 redis.conf:
# 指定主节点
replicaof 192.168.1.100 6379
# 主节点密码(如果设置了)
masterauth 123456
# 从节点只读
replica-read-only yes方式 2:命令行(临时生效,重启后失效)
# 连接从节点后执行
SLAVEOF 127.0.0.1 6379
# 或者使用新命令
REPLICAOF 127.0.0.1 6379
# 取消复制
REPLICAOF NO ONE方式 3:启动参数
redis-server --replicaof 192.168.1.100 63792.1.3 验证主从复制
步骤 1:查看主节点信息
# 连接主节点
redis-cli -p 6379
# 查看当前库信息
INFO replication
# 输出示例:
# # Replication
# role:master
# connected_slaves:2
# slave0:ip=127.0.0.1,port=6380,state=online,offset=420,lag=1
# slave1:ip=127.0.0.1,port=6381,state=online,offset=420,lag=1
# master_replid:907bcdf00c69d361ede43f4f6181004e2148efb7
# master_repl_offset:420步骤 2:查看从节点信息
# 连接从节点6380
redis-cli -p 6380
# 查看复制状态
INFO replication
# 输出示例:
# # Replication
# role:slave
# master_host:127.0.0.1
# master_port:6379
# master_link_status:up
# master_sync_in_progress:0
# slave_repl_offset:420
# slave_read_only:1步骤 3:测试主从复制
# 在主节点写入数据
redis-cli -p 6379 SET k1 v1
redis-cli -p 6379 SET k2 v2
# 在从节点读取数据
redis-cli -p 6380 GET k1
redis-cli -p 6380 GET k2
# 输出:
# "v1"
# "v2"步骤 4:测试从节点只读
# 在从节点尝试写入数据
redis-cli -p 6380 SET k3 v3
# 输出错误:
# (error) READONLY You can't write against a read only replica.主从复制的几个重要特性:
-
主机可以写,从机不能写只能读
- 主机中的所有信息和数据都会自动保存在从机中
- 从机尝试写操作会报错:READONLY
-
主机断开后的行为
- 如果主机断开了,从机依然连接到主机,可以进行读操作
- 主机恢复后,从机依然可以直接从主机同步信息
-
命令行配置的持久性
- 使用命令行配置的主从关系,如果从机重启,就会变回主机
- 如果再通过命令变回从机,立马就可以从主机中获取值
- 真实的主从配置应该在配置文件中配置,这样才是永久的
2.2 全量同步
2.2.1 全量同步触发条件
全量同步在以下情况触发:
- 从节点第一次连接主节点
- 从节点与主节点断开连接时间过长
- 从节点请求的复制偏移量不存在
2.2.2 全量同步流程
从节点 主节点
| |
|---PSYNC ? -1--------->|
| |
|<---+RUNID + OFFSET----|
| |
|<------RDB文件---------|
| |
|<---缓冲区命令---------|
| |
|---继续接收增量------->|详细步骤:
-
握手阶段
- 从节点发送
PSYNC ? -1请求全量同步 - 主节点返回自己的 RUNID 和复制偏移量
- 从节点发送
-
发送 RDB 文件
- 主节点执行 BGSAVE 生成 RDB 文件
- 主节点将 RDB 文件发送给从节点
- 从节点接收并加载 RDB 文件
-
发送缓冲区命令
- 在生成 RDB 期间,主节点继续接收写命令
- 这些命令保存在复制缓冲区
- RDB 发送完成后,主节点发送缓冲区命令
-
继续增量同步
- 从节点加载完 RDB 和缓冲区命令后
- 开始接收增量命令
2.2.3 全量同步优化
无盘复制(Diskless Replication):
# 主节点配置
repl-diskless-sync yes
repl-diskless-sync-delay 5- 主节点不将 RDB 写入磁盘
- 直接通过网络发送给从节点
- 减少磁盘 IO
复制积压缓冲区:
# 缓冲区大小,默认1MB
repl-backlog-size 1mb
# 缓冲区过期时间,默认300秒
repl-backlog-ttl 3600- 保存主节点的写命令
- 从节点断线重连时,如果偏移量在缓冲区内,只同步增量
2.3 增量同步
2.3.1 增量同步触发条件
增量同步在以下情况触发:
- 从节点与主节点短暂断开
- 从节点请求的复制偏移量在复制积压缓冲区内
2.3.2 增量同步流程
从节点 主节点
| |
|---PSYNC RUNID OFFSET->|
| |
|<---CONTINUE-----------|
| |
|<---增量命令----------->|
| |
|---继续接收增量------->|详细步骤:
-
请求同步
- 从节点发送
PSYNC RUNID OFFSET - RUNID 是主节点的唯一标识
- OFFSET 是从节点的复制偏移量
- 从节点发送
-
判断同步方式
- 主节点检查 RUNID 是否匹配
- 检查 OFFSET 是否在复制积压缓冲区内
- 如果都满足,执行增量同步
-
发送增量命令
- 主节点从复制积压缓冲区读取命令
- 发送给从节点
- 从节点执行这些命令
2.3.3 复制偏移量
每个节点维护一个复制偏移量:
# 查看复制偏移量
INFO replication
# 输出示例:
# master_repl_offset:123456
# slave_repl_offset:123456作用:
- 标识数据同步位置
- 判断是否需要全量同步
- 检测复制延迟
三、Redis 哨兵模式
3.1 概念和原理
3.1.1 哨兵模式概念
哨兵(Sentinel)是 Redis 的高可用解决方案,用于监控主从节点,自动进行故障转移。
核心功能:
- 监控:持续监控主从节点是否正常运行
- 通知:当节点出现故障时,通知管理员
- 自动故障转移:主节点故障时,自动将从节点提升为主节点
- 配置中心:提供主节点的地址信息
3.1.2 哨兵架构
客户端
|
v
哨兵集群(3个哨兵)
| | |
v v v
主节点 从节点1 从节点2为什么需要多个哨兵?
- 避免单点故障
- 防止误判(主观下线 vs 客观下线)
- 提高可用性
3.1.3 主观下线和客观下线
主观下线(SDOWN):
- 单个哨兵认为某个节点下线
- 哨兵通过心跳检测判断
- 配置:
down-after-milliseconds
客观下线(ODOWN):
- 多个哨兵都认为某个节点下线
- 需要达到法定人数(quorum)
- 配置:
quorum
判断流程:
哨兵A: 主观下线
|
v
询问其他哨兵
|
+---哨兵B: 主观下线
+---哨兵C: 主观下线
|
v
达到quorum -> 客观下线3.1.4 故障转移流程
1. 发现主节点客观下线
|
v
2. 选举领头哨兵
|
v
3. 领头哨兵选择新的主节点
|
v
4. 提升从节点为主节点
|
v
5. 其他从节点复制新的主节点
|
v
6. 通知客户端新的主节点地址选择新主节点的标准:
- 优先级(replica-priority)
- 复制偏移量(数据最新)
- 运行 ID(最小)
3.2 搭建
3.2.1 配置主从节点
假设有:
- 1 个主节点:192.168.1.100:6379
- 2 个从节点:192.168.1.101:6379, 192.168.1.102:6379
从节点配置:
replicaof 192.168.1.100 6379
masterauth 1234563.2.2 配置哨兵
创建 sentinel.conf:
# 哨兵端口
port 26379
# 监控主节点
# mymaster:主节点名称
# 192.168.1.100 6379:主节点地址
# 2:quorum,至少2个哨兵认为主节点下线才进行故障转移
sentinel monitor mymaster 192.168.1.100 6379 2
# 主节点密码
sentinel auth-pass mymaster 123456
# 主观下线时间(毫秒)
sentinel down-after-milliseconds mymaster 30000
# 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 180000
# 故障转移时,最多有多少个从节点同时同步新的主节点
sentinel parallel-syncs mymaster 1
# 哨兵工作目录
dir /var/lib/redis/sentinel启动哨兵:
# 方式1:使用配置文件
redis-sentinel /path/to/sentinel.conf
# 方式2:使用redis-server
redis-server /path/to/sentinel.conf --sentinel3.2.3 验证哨兵
# 连接哨兵
redis-cli -p 26379
# 查看主节点信息
SENTINEL masters
# 查看指定主节点的详细信息
SENTINEL master mymaster
# 查看从节点信息
SENTINEL slaves mymaster
# 查看哨兵信息
SENTINEL sentinels mymaster3.2.4 客户端连接哨兵
客户端应该连接哨兵,而不是直接连接主节点。
Go 代码示例:
package main
import (
"fmt"
"github.com/go-redis/redis/v8"
)
func main() {
// 连接哨兵
rdb := redis.NewFailoverClient(&redis.FailoverOptions{
MasterName: "mymaster",
SentinelAddrs: []string{"192.168.1.100:26379", "192.168.1.101:26379", "192.168.1.102:26379"},
Password: "123456",
})
// 测试连接
ctx := context.Background()
err := rdb.Set(ctx, "key", "value", 0).Err()
if err != nil {
panic(err)
}
val, err := rdb.Get(ctx, "key").Result()
if err != nil {
panic(err)
}
fmt.Println("key:", val)
}3.2.5 哨兵模式的优缺点
优点:
-
哨兵集群,基于主从复制模式
- 所有的主从配置优点,它全有
- 数据冗余、读写分离、故障恢复、负载均衡
-
主从可以切换,故障可以转移
- 系统的可用性就会更好
- 自动故障转移,无需人工干预
-
哨兵模式就是主从模式的升级
- 从手动到自动,更加健壮
- 提供监控、通知、自动故障转移等功能
缺点:
-
Redis 不方便在线扩容
- 集群达到一定的上限,在线扩容就会十分麻烦
- 需要重启节点,影响服务可用性
-
配置复杂
- 实现哨兵模式的配置其实也很麻烦
- 里面有甚多的配置项需要理解和调整
-
单点故障风险
- 虽然哨兵本身是集群模式,但如果配置不当,仍可能存在单点故障
- 需要至少 3 个哨兵节点才能保证高可用
-
性能开销
- 哨兵会定期发送心跳检测,会有一定的性能开销
- 对于性能要求极高的场景,需要考虑这个因素
3.3.Go-Redis NewFailoverClient(哨兵集成)
在 Sentinel 集群监管下的 Redis 主从集群,其节点会因为自动故障转移而发生变化,Redis 的客户端必须感知这种变化,及时更新连接信息。Go-Redis 通过 NewFailoverClient 实现了与 Spring RedisTemplate 完全一致的哨兵感知、主节点自动切换能力,底层自动监听哨兵事件,无需手动处理节点变更。
下面我们通过完整配置实现 Go-Redis 集成哨兵机制。
3.3.1.环境依赖
首先确保项目中引入 go-redis/v9(最新稳定版):
go get github.com/redis/go-redis/v93.3.2.基础客户端(自动故障切换)
直接使用 NewFailoverClient 连接哨兵集群,自动发现主节点、自动切换新主。
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
"time"
)
var ctx = context.Background()
func main() {
// 哨兵模式客户端:自动感知主节点切换
rdb := redis.NewFailoverClient(&redis.FailoverOptions{
// 哨兵中配置的主节点名称(必须与sentinel.conf一致)
MasterName: "mymaster",
// 哨兵节点地址列表(填写所有哨兵,避免单点故障)
SentinelAddrs: []string{
"127.0.0.1:26379",
"127.0.0.1:26380",
"127.0.0.1:26381",
},
// Redis密码(如主从设置了密码)
Password: "123456",
DB: 0,
// 超时配置
DialTimeout: 5 * time.Second,
ReadTimeout: 3 * time.Second,
WriteTimeout: 3 * time.Second,
// 主从切换回调(可用于日志/监控)
OnFailover: func(ctx context.Context, newMaster *redis.RedisNode) {
fmt.Printf("⚠️ 主节点已自动切换 → %s:%d\n", newMaster.Host, newMaster.Port)
},
})
// 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(fmt.Sprintf("redis连接失败: %v", err))
}
fmt.Println("✅ redis哨兵客户端初始化成功")
}3.3.3.读写分离配置(对应 Spring ReadFrom)
Go-Redis 提供 NewFailoverClusterClient 实现读写分离:
- 写请求 → 主节点
- 读请求 → 从节点
- 自动故障切换 + 自动负载均衡
// 读写分离客户端:读从库、写主库(对应Spring REPLICA_PREFERRED)
func NewRedisFailoverClusterClient() *redis.FailoverClusterClient {
return redis.NewFailoverClusterClient(&redis.FailoverOptions{
MasterName: "mymaster",
SentinelAddrs: []string{"127.0.0.1:26379", "127.0.0.1:26380", "127.0.0.1:26381"},
Password: "123456",
DB: 0,
// 路由策略:读写分离(最常用,对应Spring REPLICA_PREFERRED)
RouteByLatency: true, // 优先选择延迟最低的从节点
ReadOnly: true, // 读请求只访问从节点
})
}3.3.4.读写策略对照表(对应 Spring)
Go-Redis 与 Spring RedisTemplate 读写策略完全对应:
| Spring 策略 | 说明 | Go-Redis 实现 |
|---|---|---|
| MASTER | 只从主节点读 | 普通 FailoverClient |
| MASTER_PREFERRED | 优先读主 | 默认模式 |
| REPLICA | 只从从节点读 | FailoverClusterClient + ReadOnly:true |
| REPLICA_PREFERRED(推荐) | 优先读从,从不可用读主 | FailoverClusterClient(标准用法) |
3.3.5.核心能力说明(与 RedisTemplate 一致)
- 自动发现主节点:连接哨兵后自动获取当前主节点
- 自动故障切换:主节点宕机后,哨兵完成切换,客户端无感知自动连接新主
- 自动重连:切换过程中自动关闭旧连接、重建新连接
- 读写分离:支持读从、写主,降低主节点压力
- 高可用:支持多哨兵地址,防止哨兵单点故障
总结
NewFailoverClient 就是 Go 版本的 RedisTemplate:
- 底层自动对接哨兵
- 自动监听主节点切换
- 业务代码完全无需修改
- 支持读写分离、高可用、故障转移
四、Redis 集群
4.1 概念和搭建
4.1.1 集群概念
Redis 集群是 Redis 提供的分布式数据库方案,通过分片(Sharding)实现数据分散存储。
特点:
- 数据分片:数据自动分散到多个节点
- 高可用:每个节点都有主从复制
- 自动分区:支持动态添加/删除节点
- 无中心架构:所有节点地位平等
4.1.2 集群架构
客户端
|
v
节点1(主)<--->节点1(从)
节点2(主)<--->节点2(从)
节点3(主)<--->节点3(从)集群要求:
- 至少需要 3 个主节点
- 每个主节点至少有 1 个从节点
- 推荐配置:3 主 3 从
4.1.3 搭建集群
方式 1:使用 redis-cli 创建集群
假设有 6 个节点:
- 7001, 7002, 7003(主节点)
- 7004, 7005, 7006(从节点)
配置文件示例(redis-7001.conf):
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
appendonly yes
daemonize yes
dir /var/lib/redis/cluster/7001启动所有节点:
redis-server redis-7001.conf
redis-server redis-7002.conf
redis-server redis-7003.conf
redis-server redis-7004.conf
redis-server redis-7005.conf
redis-server redis-7006.conf创建集群:
redis-cli --cluster create \
192.168.1.100:7001 \
192.168.1.100:7002 \
192.168.1.100:7003 \
192.168.1.100:7004 \
192.168.1.100:7005 \
192.168.1.100:7006 \
--cluster-replicas 1参数说明:
--cluster-replicas 1:每个主节点 1 个从节点
方式 2:使用 Redis Cluster Manager
# 安装
npm install -g redis-cluster-manager
# 创建集群
rcm create 192.168.1.100:7001-7006 --replicas 14.1.4 验证集群
# 连接集群
redis-cli -c -p 7001
# 查看集群状态
CLUSTER INFO
# 查看集群节点
CLUSTER NODES
# 测试数据分布
SET key1 value1
SET key2 value2
GET key1
GET key24.2 散列插槽
4.2.1 插槽概念
Redis 集群使用散列插槽(Hash Slot)来分配数据。
插槽总数: 16384 个(0-16383)
分配规则:
- 每个主节点负责一部分插槽
- 3 个主节点时,每个负责约 5461 个插槽
- 插槽均匀分布
插槽分配示例:
节点1:插槽 0-5460
节点2:插槽 5461-10922
节点3:插槽 10923-163834.2.2 计算插槽
计算公式:
slot = CRC16(key) % 16384Go 代码示例:
package main
import (
"fmt"
"hash/crc16"
)
func calculateSlot(key string) int {
// 计算CRC16
crc := crc16.ChecksumIEEE([]byte(key))
// 取模
slot := crc % 16384
return slot
}
func main() {
key := "mykey"
slot := calculateSlot(key)
fmt.Printf("Key: %s, Slot: %d\n", key, slot)
}Hash Tag:
如果 key 包含{},只计算{}内的内容:
user:1001:profile -> slot = CRC16("1001") % 16384
user:1001:orders -> slot = CRC16("1001") % 16384用途:
- 确保相关数据在同一节点
- 支持 MGET、MSET 等批量操作
4.2.3 查看插槽分布
# 查看所有插槽的分配
CLUSTER SLOTS
# 查看指定key的插槽
CLUSTER KEYSLOT mykey
# 查看指定插槽所在的节点
CLUSTER COUNTKEYSINSLOT 54614.3 请求重定向
4.3.1 为什么需要请求重定向?
Redis 集群采用去中心化的架构,集群的主节点各自负责一部分槽。客户端如何确定 key 到底会映射到哪个节点上呢?这就是请求重定向要解决的问题。
4.3.2 节点处理请求的流程
客户端发送命令
|
v
1. 检查当前key是否存在当前NODE?
|
v
2. 通过CRC16(key) % 16384计算出slot
|
v
3. 查询负责该slot的节点,得到节点指针
|
v
4. 该指针与自身节点比较
|
+---> 若slot不是由自身负责,则返回MOVED重定向
|
+---> 若slot由自身负责,且key在slot中,则返回该key对应结果
|
+---> 若key不存在此slot中,检查该slot是否正在迁出(MIGRATING)?
|
+---> 若key正在迁出,返回ASK错误重定向客户端到迁移的目的服务器上
|
+---> 若Slot未迁出,检查Slot是否导入中?
|
+---> 若Slot导入中且有ASKING标记,则直接操作
|
+---> 否则返回MOVED重定向4.3.3 MOVED 重定向
场景: 槽不命中,即当前键命令所请求的键不在当前请求的节点中。
处理流程:
- 当前节点会向客户端发送一个 MOVED 重定向
- 客户端根据 MOVED 重定向所包含的内容找到目标节点
- 客户端再一次发送命令到目标节点
MOVED 重定向示例:
# 假设客户端连接到节点1(7001),但key1实际在节点2(7002)
redis-cli -c -p 7001
# 执行命令
127.0.0.1:7001> SET key1 value1
(error) MOVED 12539 127.0.0.1:7002
# 客户端自动重定向到节点2
127.0.0.1:7002> SET key1 value1
OKMOVED 重定向的特点:
- 表示槽已经永久迁移到另一个节点
- 客户端需要更新本地缓存
- 后续对该槽的请求都直接发送到新节点
4.3.4 ASK 重定向
场景: 集群伸缩时,集群伸缩会导致槽迁移。当我们去源节点访问时,此时数据已经可能已经迁移到了目标节点。
处理流程:
- 客户端访问源节点
- 源节点返回 ASK 错误
- 客户端发送 ASKING 命令到目标节点
- 客户端再次发送原命令到目标节点
ASK 重定向示例:
# 假设槽12539正在从节点1迁移到节点2
redis-cli -c -p 7001
# 执行命令
127.0.0.1:7001> GET key1
(error) ASK 12539 127.0.0.1:7002
# 客户端先发送ASKING命令
127.0.0.1:7002> ASKING
OK
# 再次执行命令
127.0.0.1:7002> GET key1
"value1"ASK 重定向的特点:
- 表示槽正在迁移中
- 客户端不需要更新本地缓存
- 只对当前请求有效,后续请求仍可能返回 MOVED
4.3.5 MOVED vs ASK 的区别
| 特性 | MOVED 重定向 | ASK 重定向 |
|---|---|---|
| 触发场景 | 槽已经永久迁移到另一个节点 | 槽正在迁移中 |
| 客户端行为 | 更新本地缓存,后续请求直接到新节点 | 不更新缓存,只对当前请求有效 |
| 持续时间 | 永久 | 临时 |
| 是否需要 ASKING 命令 | 不需要 | 需要 |
| 使用场景 | 正常的数据访问 | 集群伸缩期间的数据访问 |
4.3.6 客户端处理重定向
智能客户端(如 go-redis):
package main
import (
"context"
"fmt"
"github.com/go-redis/redis/v8"
)
func main() {
// 创建集群客户端
rdb := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{
"127.0.0.1:7001",
"127.0.0.1:7002",
"127.0.0.1:7003",
},
})
ctx := context.Background()
// 客户端会自动处理MOVED和ASK重定向
err := rdb.Set(ctx, "key1", "value1", 0).Err()
if err != nil {
panic(err)
}
val, err := rdb.Get(ctx, "key1").Result()
if err != nil {
panic(err)
}
fmt.Println("key1:", val)
}手动处理重定向(不推荐):
# 使用redis-cli的-c参数,客户端会自动处理重定向
redis-cli -c -p 7001
# 如果不使用-c参数,需要手动处理重定向
redis-cli -p 7001
# 遇到MOVED错误后,需要手动连接到正确的节点
redis-cli -p 70024.4 集群伸缩
4.4.1 添加节点
步骤 1:启动新节点
redis-server redis-7007.conf
redis-server redis-7008.conf步骤 2:将新节点加入集群
redis-cli --cluster add-node 192.168.1.100:7007 192.168.1.100:7001
redis-cli --cluster add-node 192.168.1.100:7008 192.168.1.100:7001步骤 3:分配插槽
# 从节点1迁移1000个插槽到节点7
redis-cli --cluster reshard 192.168.1.100:7001 \
--cluster-from 192.168.1.100:7001 \
--cluster-to 192.168.1.100:7007 \
--cluster-slots 1000步骤 4:设置主从关系
# 将节点8设置为节点7的从节点
redis-cli -p 7008 cluster replicate <节点7的node-id>4.4.2 删除节点
步骤 1:迁移插槽
# 将节点7的插槽迁移到其他节点
redis-cli --cluster reshard 192.168.1.100:7001步骤 2:删除节点
# 删除从节点
redis-cli --cluster del-node 192.168.1.100:7001 <节点8的node-id>
# 删除主节点(必须先迁移插槽)
redis-cli --cluster del-node 192.168.1.100:7001 <节点7的node-id>4.5 故障转移
4.5.1 故障检测
集群通过 Gossip 协议检测节点故障。
检测机制:
- 节点定期发送 PING 消息
- 如果超过
cluster-node-timeout未收到 PONG,标记为 PFAIL - 如果超过半数主节点标记为 PFAIL,标记为 FAIL
配置:
# 节点超时时间(毫秒)
cluster-node-timeout 150004.5.2 故障转移流程
1. 主节点故障
|
v
2. 从节点检测到主节点FAIL
|
v
3. 从节点发起选举
|
v
4. 获得半数以上主节点投票
|
v
5. 从节点提升为主节点
|
v
6. 广播新主节点信息选举规则:
- 优先级最高的从节点
- 复制偏移量最大的从节点
- 运行 ID 最小的从节点
4.5.3 故障恢复
# 查看集群状态
CLUSTER INFO
# 查看节点状态
CLUSTER NODES
# 手动故障转移(在主节点上执行)
CLUSTER FAILOVER4.6 go-redis 访问和演示
4.6.1 连接集群
Go 代码示例:
package main
import (
"context"
"fmt"
"github.com/go-redis/redis/v8"
)
func main() {
// 创建集群客户端
rdb := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{
"192.168.1.100:7001",
"192.168.1.100:7002",
"192.168.1.100:7003",
},
Password: "",
PoolSize: 10,
})
ctx := context.Background()
// 测试连接
err := rdb.Ping(ctx).Err()
if err != nil {
panic(err)
}
fmt.Println("连接集群成功")
}4.6.2 基本操作
// 设置值
err := rdb.Set(ctx, "key1", "value1", 0).Err()
if err != nil {
panic(err)
}
// 获取值
val, err := rdb.Get(ctx, "key1").Result()
if err != nil {
panic(err)
}
fmt.Println("key1:", val)
// 删除值
err = rdb.Del(ctx, "key1").Err()
if err != nil {
panic(err)
}4.6.3 Hash 操作
// 设置Hash
err := rdb.HSet(ctx, "user:1001", map[string]interface{}{
"name": "张三",
"age": 25,
"email": "zhangsan@example.com",
}).Err()
// 获取Hash
name, err := rdb.HGet(ctx, "user:1001", "name").Result()
if err != nil {
panic(err)
}
fmt.Println("name:", name)
// 获取整个Hash
user, err := rdb.HGetAll(ctx, "user:1001").Result()
if err != nil {
panic(err)
}
fmt.Println("user:", user)4.6.4 List 操作
// 左推入列表
err := rdb.LPush(ctx, "mylist", "value1", "value2", "value3").Err()
if err != nil {
panic(err)
}
// 获取列表长度
length, err := rdb.LLen(ctx, "mylist").Result()
if err != nil {
panic(err)
}
fmt.Println("list length:", length)
// 获取列表元素
values, err := rdb.LRange(ctx, "mylist", 0, -1).Result()
if err != nil {
panic(err)
}
fmt.Println("list values:", values)4.6.5 Set 操作
// 添加到集合
err := rdb.SAdd(ctx, "myset", "member1", "member2", "member3").Err()
if err != nil {
panic(err)
}
// 获取集合成员
members, err := rdb.SMembers(ctx, "myset").Result()
if err != nil {
panic(err)
}
fmt.Println("set members:", members)
// 判断成员是否存在
exists, err := rdb.SIsMember(ctx, "myset", "member1").Result()
if err != nil {
panic(err)
}
fmt.Println("member1 exists:", exists)4.6.6 Sorted Set 操作
// 添加到有序集合
err := rdb.ZAdd(ctx, "leaderboard", &redis.Z{
Score: 100,
Member: "user1",
}, &redis.Z{
Score: 200,
Member: "user2",
}).Err()
// 获取排名
rank, err := rdb.ZRank(ctx, "leaderboard", "user1").Result()
if err != nil {
panic(err)
}
fmt.Println("user1 rank:", rank)
// 获取分数
score, err := rdb.ZScore(ctx, "leaderboard", "user1").Result()
if err != nil {
panic(err)
}
fmt.Println("user1 score:", score)
// 获取排行榜
leaderboard, err := rdb.ZRevRangeWithScores(ctx, "leaderboard", 0, 9).Result()
if err != nil {
panic(err)
}
fmt.Println("leaderboard:", leaderboard)4.6.7 批量操作
// Pipeline批量操作
pipe := rdb.Pipeline()
incr := pipe.Incr(ctx, "counter")
pipe.Expire(ctx, "counter", time.Hour)
// 执行Pipeline
cmds, err := pipe.Exec(ctx)
if err != nil {
panic(err)
}
// 获取结果
counter := incr.Val()
fmt.Println("counter:", counter)4.6.8 事务操作
// Watch监听key
err := rdb.Watch(ctx, func(tx *redis.Tx) error {
// 获取当前值
n, err := tx.Get(ctx, "balance").Int()
if err != nil && err != redis.Nil {
return err
}
// 事务操作
_, err = tx.TxPipelined(ctx, func(pipe redis.Pipeliner) error {
pipe.Set(ctx, "balance", n+100, 0)
return nil
})
return err
}, "balance")
if err != nil {
panic(err)
}
fmt.Println("事务执行成功")4.6.9 错误处理
// 处理MOVED错误
val, err := rdb.Get(ctx, "key1").Result()
if err != nil {
if err == redis.Nil {
fmt.Println("key不存在")
} else {
fmt.Println("其他错误:", err)
}
}
// 处理重定向错误
if err != nil && strings.Contains(err.Error(), "MOVED") {
fmt.Println("需要重定向")
// go-redis会自动处理重定向
}4.6.10 完整示例
package main
import (
"context"
"fmt"
"time"
"github.com/go-redis/redis/v8"
)
func main() {
// 创建集群客户端
rdb := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{
"192.168.1.100:7001",
"192.168.1.100:7002",
"192.168.1.100:7003",
},
Password: "",
PoolSize: 10,
MaxRetries: 3,
})
ctx := context.Background()
// 测试连接
err := rdb.Ping(ctx).Err()
if err != nil {
panic(err)
}
fmt.Println("=== Redis集群操作示例 ===")
// String操作
err = rdb.Set(ctx, "name", "张三", 0).Err()
if err != nil {
panic(err)
}
name, _ := rdb.Get(ctx, "name").Result()
fmt.Printf("String: name = %s\n", name)
// Hash操作
rdb.HSet(ctx, "user:1", map[string]interface{}{
"name": "李四",
"age": 30,
"email": "lisi@example.com",
})
user, _ := rdb.HGetAll(ctx, "user:1").Result()
fmt.Printf("Hash: user:1 = %v\n", user)
// List操作
rdb.LPush(ctx, "tasks", "task1", "task2", "task3")
tasks, _ := rdb.LRange(ctx, "tasks", 0, -1).Result()
fmt.Printf("List: tasks = %v\n", tasks)
// Set操作
rdb.SAdd(ctx, "tags", "redis", "golang", "database")
tags, _ := rdb.SMembers(ctx, "tags").Result()
fmt.Printf("Set: tags = %v\n", tags)
// Sorted Set操作
rdb.ZAdd(ctx, "rank", &redis.Z{Score: 100, Member: "player1"})
rdb.ZAdd(ctx, "rank", &redis.Z{Score: 200, Member: "player2"})
rank, _ := rdb.ZRevRangeWithScores(ctx, "rank", 0, -1).Result()
fmt.Printf("Sorted Set: rank = %v\n", rank)
// 设置过期时间
rdb.Expire(ctx, "name", 10*time.Minute)
ttl, _ := rdb.TTL(ctx, "name").Result()
fmt.Printf("TTL: name expires in %v\n", ttl)
fmt.Println("=== 操作完成 ===")
}五、总结
5.1 持久化选择
| 场景 | 推荐方案 |
|---|---|
| 数据可以容忍丢失 | RDB |
| 数据不能丢失 | AOF |
| 生产环境 | RDB + AOF |
| Redis 4.0+ | 混合持久化 |
5.2 高可用方案选择
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 主从复制 | 读多写少 | 简单 | 需要手动故障转移 |
| 哨兵模式 | 需要自动故障转移 | 自动故障转移 | 配置复杂 |
| 集群 | 数据量大 | 自动分片 | 客户端需要支持 |
5.3 最佳实践
-
持久化
- 生产环境使用 RDB + AOF
- 定期备份 RDB 文件
- 监控 AOF 文件大小
-
主从复制
- 从节点配置为只读
- 监控复制延迟
- 定期检查复制状态
-
哨兵模式
- 至少 3 个哨兵
- 哨兵部署在不同机器
- 监控哨兵状态
-
集群
- 至少 3 主 3 从
- 使用 Hash Tag 优化批量操作
- 监控集群状态
-
客户端
- 使用连接池
- 处理重定向错误
- 实现重试机制
Redis 高级篇-多级缓存
一、什么是多级缓存
1.1 传统缓存架构缺陷
传统的缓存架构通常采用”Redis + 数据库”的两层结构:
客户端 → 应用服务器 → Redis → 数据库存在的问题:
-
Redis 单点瓶颈
- 所有请求都经过 Redis
- Redis 成为性能瓶颈
- 高并发下 Redis 压力巨大
-
网络开销大
- 每次请求都需要访问 Redis
- 网络 IO 成为性能瓶颈
- 延迟较高
-
Redis 故障影响大
- Redis 宕机后所有请求打到数据库
- 可能导致数据库崩溃
- 系统可用性降低
-
无法应对极端高并发
- 秒杀场景下 QPS 可能达到 10 万+
- 单层 Redis 难以承受
- 需要更强大的缓存架构
1.2 多级缓存完整流程
多级缓存采用”浏览器 + Nginx + Redis + 应用服务 + 数据库”的多层结构:
┌─────────────────────────────────────────────────────────────┐
│ 客户端请求 │
└─────────────────────┬───────────────────────────────────────┘
│
v
┌─────────────────────────────────────────────────────────────┐
│ 浏览器本地缓存(Cookie、LocalStorage、SessionStorage) │
│ - 静态资源缓存 │
│ - 用户偏好设置 │
│ - 过期时间:小时级 │
└─────────────────────┬───────────────────────────────────────┘
│ 未命中
v
┌─────────────────────────────────────────────────────────────┐
│ Nginx本地缓存(lua_shared_dict) │
│ - 热点数据缓存 │
│ - 共享内存存储 │
│ - 过期时间:分钟级 │
└─────────────────────┬───────────────────────────────────────┘
│ 未命中
v
┌─────────────────────────────────────────────────────────────┐
│ Redis分布式缓存 │
│ - 全量数据缓存 │
│ - 集群部署 │
│ - 过期时间:小时级 │
└─────────────────────┬───────────────────────────────────────┘
│ 未命中
v
┌─────────────────────────────────────────────────────────────┐
│ 应用服务本地缓存(BigCache、go-cache) │
│ - 进程内缓存 │
│ - 极速访问 │
│ - 过期时间:秒级 │
└─────────────────────┬───────────────────────────────────────┘
│ 未命中
v
┌─────────────────────────────────────────────────────────────┐
│ 数据库(MySQL) │
│ - 持久化存储 │
│ - 数据源 │
└─────────────────────────────────────────────────────────────┘多级缓存的优势:
-
逐层过滤请求
- 大部分请求在 Nginx 层就被处理
- 减少后端压力
- 提高响应速度
-
降低网络开销
- 本地缓存无需网络 IO
- 响应时间从毫秒级降到微秒级
- 极大提升性能
-
提高系统可用性
- 即使 Redis 故障,Nginx 本地缓存仍可工作
- 多层保障,更加健壮
-
应对极端高并发
- 秒杀场景下,Nginx 本地缓存可承担大部分请求
- 保护后端服务不被击垮
1.3 架构角色变化:Nginx 变业务 Web 服务器
在传统架构中,Nginx 只是反向代理服务器,负责负载均衡和静态资源服务。
在多级缓存架构中,Nginx 的角色发生变化:
传统架构:
Nginx(反向代理)→ 应用服务器(业务逻辑)→ 数据库多级缓存架构:
Nginx(反向代理 + 业务逻辑 + 本地缓存)→ 应用服务器 → 数据库Nginx 的新职责:
-
反向代理
- 负载均衡
- 请求转发
-
业务逻辑处理
- 使用 Lua 编写业务代码
- 处理简单的查询请求
- 数据聚合和转换
-
本地缓存
- 使用 lua_shared_dict 存储热点数据
- 提供极速访问
-
Redis 客户端
- 直接访问 Redis
- 减少应用服务器压力
为什么选择 OpenResty?
OpenResty 是一个基于 Nginx 的 Web 平台,集成了大量精良的 Lua 库:
- 高性能:基于 Nginx 事件模型,支持高并发
- 灵活:使用 Lua 编写业务逻辑,开发效率高
- 丰富:提供 Redis、MySQL、HTTP 等客户端库
- 成熟:在生产环境广泛应用,稳定可靠
1.4 集群部署:Nginx 集群 + Gin 集群
为了实现高可用和高性能,需要集群部署:
┌──────────────┐
│ 负载均衡 │
│ (LVS/F5) │
└──────┬───────┘
│
┌──────────────┼──────────────┐
│ │ │
v v v
┌──────────┐ ┌──────────┐ ┌──────────┐
│ OpenResty│ │ OpenResty│ │ OpenResty│
│ 节点1 │ │ 节点2 │ │ 节点3 │
│ 本地缓存 │ │ 本地缓存 │ │ 本地缓存 │
└─────┬────┘ └─────┬────┘ └─────┬────┘
│ │ │
└──────────────┼──────────────┘
│
v
┌───────────────┐
│ Redis Cluster │
└───────┬───────┘
│
┌─────────────┼─────────────┐
│ │ │
v v v
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Gin │ │ Gin │ │ Gin │
│ 服务1 │ │ 服务2 │ │ 服务3 │
│ 本地缓存 │ │ 本地缓存 │ │ 本地缓存 │
└─────┬────┘ └─────┬────┘ └─────┬────┘
│ │ │
└─────────────┼─────────────┘
│
v
┌───────────────┐
│ MySQL Master │
│ 主数据库 │
└───────┬───────┘
│
v
┌───────────────┐
│ MySQL Slave │
│ 从数据库 │
└───────────────┘集群部署要点:
-
OpenResty 集群
- 至少 3 个节点
- 每个节点独立的本地缓存
- 需要解决缓存一致性问题
-
Redis 集群
- 3 主 3 从配置
- 数据分片存储
- 自动故障转移
-
Gin 集群
- 至少 3 个节点
- 每个节点独立的本地缓存
- 无状态服务,可水平扩展
-
数据库集群
- 主从复制
- 读写分离
- 数据持久化
二、Go 进程本地缓存
2.1 分布式缓存 vs 进程本地缓存对比
| 特性 | 分布式缓存(Redis) | 进程本地缓存(BigCache) |
|---|---|---|
| 存储位置 | 独立进程,网络访问 | 应用进程内,内存访问 |
| 访问速度 | 毫秒级(网络 IO) | 微秒级(内存访问) |
| 数据一致性 | 集中存储,一致性好 | 分散存储,一致性差 |
| 容量 | 可配置大容量(GB 级) | 受限于进程内存 |
| 扩展性 | 易于扩展 | 需要应用重启 |
| 适用场景 | 全量数据缓存 | 热点数据缓存 |
| 故障影响 | 影响所有应用节点 | 只影响单个节点 |
| 成本 | 需要独立服务器 | 无额外成本 |
选择建议:
- 使用分布式缓存:数据量大、需要持久化、多个应用共享
- 使用本地缓存:热点数据、访问频繁、对延迟敏感
- 组合使用:本地缓存作为一级缓存,Redis 作为二级缓存
2.2 Go 本地缓存选型:BigCache 介绍
主流 Go 本地缓存库对比:
| 库名 | 性能 | 特点 | 适用场景 |
|---|---|---|---|
| BigCache | 极高 | 零 GC 开销、分片存储 | 高并发、大数据量 |
| go-cache | 高 | 简单易用、支持过期 | 中小规模、简单场景 |
| sync.Map | 高 | Go 标准库、无过期 | 简单 KV 存储 |
| freecache | 高 | 零 GC、内存限制 | 内存受限场景 |
BigCache 优势:
-
零 GC 开销
- 使用堆外内存
- 避免 GC 扫描
- 适合存储大量数据
-
高性能
- 分片设计,减少锁竞争
- 读写性能极高
- 支持高并发
-
内存控制
- 可设置最大内存
- 自动淘汰旧数据
- 防止内存溢出
-
简单易用
- API 简洁
- 支持过期时间
- 易于集成
2.3 BigCache 基础使用
安装 BigCache:
go get github.com/allegro/bigcache/v3基础示例:
package main
import (
"fmt"
"time"
"github.com/allegro/bigcache/v3"
)
func main() {
cache, err := bigcache.NewBigCache(bigcache.DefaultConfig(10 * time.Minute))
if err != nil {
panic(err)
}
defer cache.Close()
key := "user:1001"
value := []byte(`{"id":1001,"name":"张三","age":25}`)
err = cache.Set(key, value)
if err != nil {
panic(err)
}
fmt.Println("设置缓存成功")
data, err := cache.Get(key)
if err != nil {
panic(err)
}
fmt.Printf("获取缓存: %s\n", string(data))
err = cache.Delete(key)
if err != nil {
panic(err)
}
fmt.Println("删除缓存成功")
}高级配置:
package main
import (
"fmt"
"time"
"github.com/allegro/bigcache/v3"
)
func NewBigCache() (*bigcache.BigCache, error) {
config := bigcache.Config{
Shards: 1024,
LifeWindow: 10 * time.Minute,
CleanWindow: 5 * time.Minute,
MaxEntriesInWindow: 1000 * 10 * 60,
MaxShardSize: 500 * 1024 * 1024,
Verbose: true,
Hasher: newDefaultHasher(),
HardMaxCacheSize: 1024,
OnRemove: func(key string, entry []byte) {
fmt.Printf("Key %s removed\n", key)
},
OnRemoveWithReason: func(key string, entry []byte, reason bigcache.RemoveReason) {
fmt.Printf("Key %s removed, reason: %v\n", key, reason)
},
}
return bigcache.NewBigCache(config)
}
type defaultHasher struct{}
func newDefaultHasher() *defaultHasher {
return &defaultHasher{}
}
func (h *defaultHasher) Sum64(key string) uint64 {
hash := uint64(14695981039346656037)
for _, c := range key {
hash ^= uint64(c)
hash *= 1099511628211
}
return hash
}2.4 商品/库存本地缓存实现
项目结构:
multi-level-cache/
├── main.go
├── config/
│ └── config.go
├── cache/
│ └── local_cache.go
├── model/
│ ├── product.go
│ └── stock.go
├── dao/
│ ├── product_dao.go
│ └── stock_dao.go
├── service/
│ ├── product_service.go
│ └── stock_service.go
└── router/
└── router.go配置文件:
package config
import (
"time"
)
type Config struct {
Server ServerConfig
Cache CacheConfig
Database DatabaseConfig
Redis RedisConfig
}
type ServerConfig struct {
Port int
}
type CacheConfig struct {
LocalCacheTTL time.Duration
LocalCacheMaxSize int
RedisCacheTTL time.Duration
}
type DatabaseConfig struct {
Host string
Port int
User string
Password string
DBName string
}
type RedisConfig struct {
Addr string
Password string
DB int
}
var AppConfig = &Config{
Server: ServerConfig{
Port: 8080,
},
Cache: CacheConfig{
LocalCacheTTL: 5 * time.Minute,
LocalCacheMaxSize: 10000,
RedisCacheTTL: 30 * time.Minute,
},
Database: DatabaseConfig{
Host: "localhost",
Port: 3306,
User: "root",
Password: "123456",
DBName: "shop",
},
Redis: RedisConfig{
Addr: "localhost:6379",
Password: "",
DB: 0,
},
}本地缓存封装:
package cache
import (
"encoding/json"
"fmt"
"time"
"github.com/allegro/bigcache/v3"
"multi-level-cache/config"
)
type LocalCache struct {
cache *bigcache.BigCache
ttl time.Duration
}
func NewLocalCache() (*LocalCache, error) {
cacheConfig := bigcache.DefaultConfig(config.AppConfig.Cache.LocalCacheTTL)
cacheConfig.Shards = 1024
cacheConfig.MaxShardSize = 100 * 1024 * 1024
cache, err := bigcache.NewBigCache(cacheConfig)
if err != nil {
return nil, fmt.Errorf("创建本地缓存失败: %w", err)
}
return &LocalCache{
cache: cache,
ttl: config.AppConfig.Cache.LocalCacheTTL,
}, nil
}
func (lc *LocalCache) Set(key string, value interface{}) error {
data, err := json.Marshal(value)
if err != nil {
return fmt.Errorf("序列化失败: %w", err)
}
return lc.cache.Set(key, data)
}
func (lc *LocalCache) Get(key string, dest interface{}) error {
data, err := lc.cache.Get(key)
if err != nil {
return err
}
return json.Unmarshal(data, dest)
}
func (lc *LocalCache) Delete(key string) error {
return lc.cache.Delete(key)
}
func (lc *LocalCache) Clear() error {
return lc.cache.Reset()
}
func (lc *LocalCache) Close() error {
return lc.cache.Close()
}数据模型:
package model
type Product struct {
ID int64 `json:"id"`
Name string `json:"name"`
Price float64 `json:"price"`
Description string `json:"description"`
Image string `json:"image"`
CategoryID int64 `json:"category_id"`
Status int `json:"status"`
CreateTime string `json:"create_time"`
UpdateTime string `json:"update_time"`
}
type Stock struct {
ID int64 `json:"id"`
ProductID int64 `json:"product_id"`
Stock int `json:"stock"`
Version int `json:"version"`
}
type ProductDetail struct {
Product Product `json:"product"`
Stock Stock `json:"stock"`
}数据库查询封装:
package dao
import (
"database/sql"
"fmt"
"multi-level-cache/config"
"multi-level-cache/model"
_ "github.com/go-sql-driver/mysql"
)
var DB *sql.DB
func InitDB() error {
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=utf8mb4&parseTime=True&loc=Local",
config.AppConfig.Database.User,
config.AppConfig.Database.Password,
config.AppConfig.Database.Host,
config.AppConfig.Database.Port,
config.AppConfig.Database.DBName,
)
var err error
DB, err = sql.Open("mysql", dsn)
if err != nil {
return fmt.Errorf("连接数据库失败: %w", err)
}
DB.SetMaxOpenConns(100)
DB.SetMaxIdleConns(10)
return DB.Ping()
}
func GetProductByID(id int64) (*model.Product, error) {
query := `SELECT id, name, price, description, image, category_id, status, create_time, update_time
FROM tb_product WHERE id = ?`
product := &model.Product{}
err := DB.QueryRow(query, id).Scan(
&product.ID,
&product.Name,
&product.Price,
&product.Description,
&product.Image,
&product.CategoryID,
&product.Status,
&product.CreateTime,
&product.UpdateTime,
)
if err != nil {
return nil, err
}
return product, nil
}
func GetStockByProductID(productID int64) (*model.Stock, error) {
query := `SELECT id, product_id, stock, version
FROM tb_seckill_voucher WHERE voucher_id = ?`
stock := &model.Stock{}
err := DB.QueryRow(query, productID).Scan(
&stock.ID,
&stock.ProductID,
&stock.Stock,
&stock.Version,
)
if err != nil {
return nil, err
}
return stock, nil
}业务逻辑:
package service
import (
"fmt"
"multi-level-cache/cache"
"multi-level-cache/dao"
"multi-level-cache/model"
)
type ProductService struct {
localCache *cache.LocalCache
}
func NewProductService(localCache *cache.LocalCache) *ProductService {
return &ProductService{
localCache: localCache,
}
}
func (s *ProductService) GetProductDetail(id int64) (*model.ProductDetail, error) {
cacheKey := fmt.Sprintf("product:detail:%d", id)
var detail model.ProductDetail
err := s.localCache.Get(cacheKey, &detail)
if err == nil {
return &detail, nil
}
product, err := dao.GetProductByID(id)
if err != nil {
return nil, fmt.Errorf("查询商品失败: %w", err)
}
stock, err := dao.GetStockByProductID(id)
if err != nil {
return nil, fmt.Errorf("查询库存失败: %w", err)
}
detail = model.ProductDetail{
Product: *product,
Stock: *stock,
}
_ = s.localCache.Set(cacheKey, detail)
return &detail, nil
}
func (s *ProductService) UpdateProductStock(productID int64, stock int) error {
query := `UPDATE tb_seckill_voucher SET stock = ? WHERE voucher_id = ?`
_, err := dao.DB.Exec(query, stock, productID)
if err != nil {
return err
}
cacheKey := fmt.Sprintf("product:detail:%d", productID)
_ = s.localCache.Delete(cacheKey)
return nil
}路由配置:
package router
import (
"fmt"
"net/http"
"multi-level-cache/service"
"github.com/gin-gonic/gin"
)
func SetupRouter(productService *service.ProductService) *gin.Engine {
r := gin.Default()
r.GET("/product/:id", func(c *gin.Context) {
id := c.Param("id")
var productID int64
_, err := fmt.Sscanf(id, "%d", &productID)
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "无效的商品ID"})
return
}
detail, err := productService.GetProductDetail(productID)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": err.Error()})
return
}
c.JSON(http.StatusOK, gin.H{
"code": 200,
"data": detail,
})
})
return r
}主程序:
package main
import (
"fmt"
"log"
"multi-level-cache/cache"
"multi-level-cache/config"
"multi-level-cache/dao"
"multi-level-cache/router"
"multi-level-cache/service"
)
func main() {
if err := dao.InitDB(); err != nil {
log.Fatalf("初始化数据库失败: %v", err)
}
defer dao.DB.Close()
localCache, err := cache.NewLocalCache()
if err != nil {
log.Fatalf("初始化本地缓存失败: %v", err)
}
defer localCache.Close()
productService := service.NewProductService(localCache)
r := router.SetupRouter(productService)
addr := fmt.Sprintf(":%d", config.AppConfig.Server.Port)
log.Printf("服务启动在 %s", addr)
if err := r.Run(addr); err != nil {
log.Fatalf("启动服务失败: %v", err)
}
}三、Lua 语法入门(OpenResty 必备)
3.1 Lua 简介与应用场景
Lua 简介:
Lua 是一种轻量级、高效的脚本语言,设计目的是为了嵌入到应用程序中,从而提供灵活的扩展和定制功能。
特点:
- 轻量级:整个解释器只有 200KB 左右
- 高效:执行速度快,接近 C 语言
- 可嵌入:易于集成到 C/C++程序中
- 简单:语法简洁,易于学习
- 可扩展:支持模块化开发
应用场景:
-
OpenResty/Nginx
- 编写业务逻辑
- 访问 Redis、MySQL
- 实现复杂的路由规则
-
游戏开发
- 游戏逻辑脚本
- 配置文件解析
- 热更新机制
-
嵌入式系统
- 物联网设备
- 自动化控制
- 配置管理
-
Web 应用
- Redis 脚本
- Nginx 业务逻辑
- API 网关
3.2 基础语法:变量、数据类型、table
变量:
-- 全局变量
name = "张三"
-- 局部变量(推荐使用)
local age = 25
-- 多重赋值
local a, b = 1, 2
-- 交换变量
a, b = b, a数据类型:
-- nil:空值
local var = nil
-- boolean:布尔值
local flag = true
-- number:数字(整数和浮点数)
local num1 = 10
local num2 = 3.14
-- string:字符串
local str1 = "Hello"
local str2 = 'World'
local str3 = [[
多行
字符串
]]
-- table:表(数组、字典、对象)
local arr = {1, 2, 3, 4, 5}
local dict = {name = "张三", age = 25}
-- function:函数
local func = function()
print("Hello")
end
-- thread:协程
local co = coroutine.create(function()
print("协程")
end)
-- userdata:用户自定义数据(C数据结构)type 函数:
print(type(nil)) -- nil
print(type(true)) -- boolean
print(type(10)) -- number
print(type("hello")) -- string
print(type({})) -- table
print(type(print)) -- functiontable:
Lua 中最强大的数据结构,可以表示数组、字典、对象等。
-- 数组
local arr = {1, 2, 3, 4, 5}
print(arr[1]) -- 输出1(索引从1开始)
-- 字典
local person = {
name = "张三",
age = 25,
city = "北京"
}
print(person.name) -- 输出张三
-- 混合结构
local data = {
1,
2,
name = "李四",
age = 30,
3
}
print(data[1]) -- 输出1
print(data.name) -- 输出李四
-- 嵌套table
local user = {
name = "王五",
address = {
province = "广东",
city = "深圳"
}
}
print(user.address.city) -- 输出深圳
-- table操作
local t = {1, 2, 3}
table.insert(t, 4) -- 插入元素
table.remove(t, 1) -- 删除第一个元素
table.sort(t) -- 排序
print(#t) -- 输出长度3.3 循环、条件判断、函数定义
条件判断:
-- if语句
local age = 20
if age < 18 then
print("未成年")
elseif age >= 18 and age < 60 then
print("成年人")
else
print("老年人")
end
-- 三元运算符(Lua没有,用and/or实现)
local status = age >= 18 and "成年" or "未成年"
print(status)循环:
-- while循环
local i = 1
while i <= 10 do
print(i)
i = i + 1
end
-- for循环(数值)
for i = 1, 10 do
print(i)
end
-- for循环(步长)
for i = 1, 10, 2 do
print(i) -- 输出1, 3, 5, 7, 9
end
-- for循环(泛型)
local arr = {10, 20, 30, 40, 50}
for index, value in ipairs(arr) do
print(index, value)
end
-- 遍历字典
local dict = {name = "张三", age = 25}
for key, value in pairs(dict) do
print(key, value)
end
-- repeat-until循环(类似do-while)
local j = 1
repeat
print(j)
j = j + 1
until j > 10函数定义:
-- 基本函数
function sayHello()
print("Hello, World!")
end
-- 带参数的函数
function greet(name)
print("Hello, " .. name)
end
-- 带返回值的函数
function add(a, b)
return a + b
end
-- 多返回值
function swap(a, b)
return b, a
end
local x, y = swap(1, 2)
print(x, y) -- 输出2 1
-- 可变参数
function sum(...)
local total = 0
for _, v in ipairs({...}) do
total = total + v
end
return total
end
print(sum(1, 2, 3, 4, 5)) -- 输出15
-- 闭包
function counter()
local count = 0
return function()
count = count + 1
return count
end
end
local c = counter()
print(c()) -- 输出1
print(c()) -- 输出2
print(c()) -- 输出3
-- 匿名函数
local func = function(x)
return x * 2
end
print(func(5)) -- 输出103.4 JSON 处理(cjson)
OpenResty 内置了 cjson 库,用于 JSON 编码和解码。
安装 cjson(如果未安装):
luarocks install lua-cjson基本使用:
-- 引入cjson库
local cjson = require "cjson"
-- 编码(Lua table -> JSON字符串)
local data = {
name = "张三",
age = 25,
hobbies = {"读书", "运动", "旅游"},
address = {
province = "广东",
city = "深圳"
}
}
local jsonStr = cjson.encode(data)
print(jsonStr)
-- 输出:{"name":"张三","age":25,"hobbies":["读书","运动","旅游"],"address":{"province":"广东","city":"深圳"}}
-- 解码(JSON字符串 -> Lua table)
local jsonData = '{"name":"李四","age":30,"city":"北京"}'
local luaTable = cjson.decode(jsonData)
print(luaTable.name) -- 输出李四
print(luaTable.age) -- 输出30
-- 编码配置
cjson.encode_empty_table_as_object(false) -- 空表编码为数组[]
cjson.encode_sparse_array(true) -- 稀疏数组编码
-- 解码配置
cjson.decode_max_depth(10) -- 最大解析深度
-- 处理特殊类型
local data2 = {
date = os.time(),
flag = true,
value = nil
}
-- null处理
local jsonStr2 = '{"name":"王五","age":null}'
local data3 = cjson.decode(jsonStr2)
print(data3.age) -- 输出nil
-- 编码时保留null
data3.age = cjson.null
local jsonStr3 = cjson.encode(data3)
print(jsonStr3) -- 输出{"name":"王五","age":null}实际应用示例:
local cjson = require "cjson"
-- 构建API响应
function buildResponse(code, message, data)
local response = {
code = code,
message = message,
data = data or cjson.null,
timestamp = os.time()
}
return cjson.encode(response)
end
-- 使用示例
local responseData = {
id = 1001,
name = "iPhone 15",
price = 5999.00,
stock = 100
}
local response = buildResponse(200, "success", responseData)
print(response)3.5 OpenResty 常用 API
ngx 模块:
-- 输出内容
ngx.say("Hello, World!")
ngx.print("Hello")
-- 获取请求参数
local id = ngx.var.arg_id
local name = ngx.var.uri
local method = ngx.var.request_method
local headers = ngx.req.get_headers()
-- 获取POST参数
ngx.req.read_body()
local args = ngx.req.get_post_args()
local username = args.username
-- 获取路径参数
local id = ngx.var.arg_id
local id = ngx.var[1]
-- 设置响应头
ngx.header["Content-Type"] = "application/json"
ngx.header["X-Custom-Header"] = "Custom Value"
-- 设置状态码
ngx.status = 200
-- 重定向
ngx.redirect("http://example.com", 302)
-- 输出JSON
local cjson = require "cjson"
local data = {code = 200, message = "success"}
ngx.say(cjson.encode(data))
-- 退出请求
ngx.exit(200)
ngx.exit(404)
ngx.exit(500)
-- 日志
ngx.log(ngx.ERR, "错误日志")
ngx.log(ngx.WARN, "警告日志")
ngx.log(ngx.INFO, "信息日志")
ngx.log(ngx.DEBUG, "调试日志")ngx.location.capture(子请求):
-- 发起子请求
local res = ngx.location.capture("/api/user", {
method = ngx.HTTP_GET,
args = {id = 1001}
})
if res.status == 200 then
ngx.say(res.body)
else
ngx.say("请求失败")
end
-- 并发子请求
local res1, res2 = ngx.location.capture_multi({
{"/api/user", {args = {id = 1001}}},
{"/api/order", {args = {id = 2001}}}
})
ngx.say(res1.body)
ngx.say(res2.body)ngx.shared.DICT(共享字典):
-- 获取共享字典
local cache = ngx.shared.product_cache
-- 设置缓存
cache:set("product:1001", "iPhone 15", 300)
-- 获取缓存
local value, flags = cache:get("product:1001")
if value then
ngx.say(value)
else
ngx.say("缓存未命中")
end
-- 删除缓存
cache:delete("product:1001")
-- 原子操作
local newval, err = cache:incr("counter", 1)
-- 安全设置(如果不存在才设置)
local success, err, forcible = cache:add("product:1002", "MacBook", 300)
-- 替换(如果存在才替换)
local success, err, forcible = cache:replace("product:1002", "MacBook Pro", 300)
-- 获取过期时间
local ttl, err = cache:ttl("product:1001")
-- 设置过期时间
cache:expire("product:1001", 600)
-- 清空所有缓存
cache:flush_all()
cache:flush_expired()resty.redis(Redis 客户端):
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000)
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.log(ngx.ERR, "连接Redis失败: ", err)
return
end
local res, err = red:auth("password")
local res, err = red:select(0)
red:set("key", "value")
red:get("key")
red:del("key")
red:expire("key", 300)
red:hset("user:1001", "name", "张三")
red:hget("user:1001", "name")
red:hgetall("user:1001")
red:lpush("list", "value1", "value2")
red:rpush("list", "value3")
red:lrange("list", 0, -1)
red:sadd("set", "member1", "member2")
red:smembers("set")
red:zadd("rank", 100, "user1")
red:zrange("rank", 0, -1, "withscores")
local ok, err = red:set_keepalive(10000, 100)
if not ok then
ngx.log(ngx.ERR, "放回连接池失败: ", err)
endresty.http(HTTP 客户端):
local http = require "resty.http"
local httpc = http.new()
local res, err = httpc:request_uri("http://localhost:8080/api/product/1001", {
method = "GET",
headers = {
["Content-Type"] = "application/json"
},
timeout = 5000
})
if not res then
ngx.log(ngx.ERR, "请求失败: ", err)
return
end
ngx.say(res.body)
local res, err = httpc:request_uri("http://localhost:8080/api/order", {
method = "POST",
body = '{"product_id":1001,"count":1}',
headers = {
["Content-Type"] = "application/json"
}
})
ngx.say(res.body)四、实现多级缓存(核心实操)
4.1 OpenResty 安装与基础配置
安装 OpenResty(CentOS):
yum install yum-utils
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
yum install openresty
yum install openresty-resty
systemctl start openresty
systemctl enable openresty安装 OpenResty(Ubuntu):
apt-get install -y wget gnupg ca-certificates
wget -qO - https://openresty.org/package/pubkey.gpg | apt-key add -
apt-get install -y software-properties-common
add-apt-repository -y "deb http://openresty.org/package/ubuntu $(lsb_release -sc) main"
apt-get update
apt-get install -y openresty
systemctl start openresty
systemctl enable openresty安装 OpenResty(macOS):
brew install openresty/brew/openresty
brew services start openresty目录结构:
/usr/local/openresty/
├── bin/
│ ├── openresty
│ └── resty
├── nginx/
│ ├── conf/
│ │ ├── nginx.conf
│ │ └── mime.types
│ ├── logs/
│ │ ├── access.log
│ │ └── error.log
│ └── html/
└── lualib/
├── resty/
│ ├── redis.lua
│ ├── http.lua
│ └── ...
└── ngx/基础配置:
编辑/usr/local/openresty/nginx/conf/nginx.conf:
# ========================================
# OpenResty基础配置详解
# ========================================
# worker进程数,建议设置为CPU核心数
# 每个worker进程是单线程的,可以处理大量并发连接
worker_processes 1;
# 错误日志级别:debug|info|notice|warn|error|crit
# 生产环境建议使用error或warn
error_log logs/error.log info;
# 事件模块配置
events {
# 每个worker进程的最大连接数
# 包含客户端连接和上游服务器连接
worker_connections 1024;
}
http {
# 包含MIME类型映射文件
include mime.types;
# 默认MIME类型(当无法识别文件类型时使用)
default_type application/octet-stream;
# 启用sendfile,提高静态文件传输效率
# sendfile: 直接在内核空间传输文件,避免用户空间拷贝
sendfile on;
# 保持连接超时时间(秒)
# 同一个客户端的多个请求可以复用TCP连接
keepalive_timeout 65;
# ========================================
# Lua模块路径配置
# ========================================
# lua_package_path: Lua模块搜索路径(.lua文件)
# ";;" 表示保留默认搜索路径
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# lua_package_cpath: Lua C模块搜索路径(.so动态库)
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
# ========================================
# 共享字典配置(Nginx本地缓存)
# ========================================
# 语法: lua_shared_dict <名称> <大小>
# product_cache: 共享内存区域名称,用于存储商品缓存
# 128m: 分配128MB共享内存
# 所有worker进程共享同一块内存区域
lua_shared_dict product_cache 128m;
server {
# 监听80端口
listen 80;
# 服务器名称,可以是域名或IP
server_name localhost;
# 字符编码设置
charset utf-8;
# ========================================
# 静态资源处理
# ========================================
location / {
root html; # 静态文件根目录
index index.html index.htm; # 默认首页文件
}
# ========================================
# Lua脚本测试路由
# ========================================
location /lua {
# 设置响应类型为纯文本
default_type 'text/plain';
# content_by_lua_block: 在content阶段执行Lua代码块
# 这是OpenResty最常用的指令之一
content_by_lua_block {
# ngx.say: 向客户端输出内容(自动添加换行)
ngx.say("Hello, OpenResty!")
}
}
# 错误页面配置
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}验证安装:
openresty -t
openresty -s reload
curl http://localhost/lua4.2 OpenResty 监听请求与返回数据
创建 Lua 脚本目录:
mkdir -p /usr/local/openresty/nginx/lua创建商品查询脚本:
/usr/local/openresty/nginx/lua/product.lua:
-- ========================================
-- OpenResty商品查询脚本(基础示例)
-- 功能:返回模拟的商品数据,演示Lua脚本基本结构
-- ========================================
-- 引入cjson模块,用于JSON编码和解码
-- cjson是OpenResty内置的高性能JSON库
local cjson = require "cjson"
-- ========================================
-- 构建统一响应格式的函数
-- @param code: 状态码(200成功,400客户端错误,500服务器错误)
-- @param message: 响应消息
-- @param data: 响应数据(任意类型)
-- @return: 格式化的响应表
-- ========================================
local function buildResponse(code, message, data)
local response = {
code = code, -- 业务状态码
message = message, -- 响应消息
data = data, -- 响应数据
timestamp = ngx.now() -- 当前时间戳(秒级)
}
return response
end
-- ========================================
-- 主函数:处理请求的核心逻辑
-- ========================================
local function main()
-- 设置响应头,指定Content-Type为JSON格式
-- 这一步很重要,否则客户端可能无法正确解析响应
ngx.header["Content-Type"] = "application/json;charset=utf-8"
-- 构造模拟的商品数据
-- 实际项目中,这里会从数据库或缓存中查询
local data = {
id = 1001,
name = "iPhone 15 Pro Max",
price = 9999.00,
stock = 100,
description = "Apple iPhone 15 Pro Max 256GB"
}
-- 构建响应对象
local response = buildResponse(200, "success", data)
-- 将响应对象编码为JSON并输出到客户端
-- ngx.say: 输出内容并自动添加换行符
-- cjson.encode: 将Lua表转换为JSON字符串
ngx.say(cjson.encode(response))
end
-- 执行主函数
-- Lua脚本从上到下执行,这里调用main()开始处理请求
main()配置路由:
server {
listen 80;
server_name localhost;
charset utf-8;
# ========================================
# 商品API路由配置
# ========================================
location /api/product {
# 设置响应类型为JSON
default_type 'application/json';
# content_by_lua_file: 从文件加载并执行Lua脚本
# 相对于nginx.conf所在目录的路径
# 与content_by_lua_block的区别:代码放在独立文件中,便于管理
content_by_lua_file lua/product.lua;
}
}测试接口:
curl http://localhost/api/product4.3 请求参数处理(路径参数获取)
获取 URL 参数:
/usr/local/openresty/nginx/lua/product_query.lua:
-- ========================================
-- OpenResty请求参数处理示例
-- 功能:从URL查询参数中获取商品ID,返回对应的商品信息
-- ========================================
local cjson = require "cjson"
-- 构建统一响应格式
local function buildResponse(code, message, data)
return {
code = code,
message = message,
data = data,
timestamp = ngx.now()
}
end
local function main()
-- 设置响应头
ngx.header["Content-Type"] = "application/json;charset=utf-8"
-- ========================================
-- 获取URL查询参数
-- ========================================
-- ngx.var.arg_<参数名>: 获取URL中的查询参数
-- 例如:/api/product/query?id=1001,则ngx.var.arg_id = "1001"
-- 注意:返回的是字符串类型,需要手动转换
local id = ngx.var.arg_id
-- 参数校验:检查id是否存在
if not id then
local response = buildResponse(400, "缺少商品ID参数", cjson.null)
ngx.status = 400 -- 设置HTTP状态码
ngx.say(cjson.encode(response))
return -- 提前返回,终止执行
end
-- 参数校验:检查id是否为有效数字
-- tonumber(): 将字符串转换为数字,转换失败返回nil
local productId = tonumber(id)
if not productId then
local response = buildResponse(400, "商品ID必须是数字", cjson.null)
ngx.status = 400
ngx.say(cjson.encode(response))
return
end
-- ========================================
-- 构造响应数据(实际项目中从数据库查询)
-- ========================================
local data = {
id = productId,
name = "商品" .. productId, -- 字符串拼接使用 ..
price = math.random(100, 10000), -- 生成随机价格
stock = math.random(0, 1000) -- 生成随机库存
}
local response = buildResponse(200, "success", data)
ngx.say(cjson.encode(response))
end
main()配置路由:
location /api/product/query {
default_type 'application/json';
content_by_lua_file lua/product_query.lua;
}测试:
curl "http://localhost/api/product/query?id=1001"获取路径参数(正则匹配):
# ========================================
# 路径参数获取(正则匹配方式)
# ========================================
# location ~: 表示使用正则表达式匹配
# ^/api/product/(\d+)$: 正则表达式
# ^ - 字符串开始
# \d+ - 匹配一个或多个数字
# () - 捕获组,可以通过ngx.var[1]获取
# $ - 字符串结束
location ~ ^/api/product/(\d+)$ {
default_type 'application/json';
# content_by_lua_block: 在配置文件中直接编写Lua代码
# 适合代码量较少的场景,代码量大时建议使用独立文件
content_by_lua_block {
local cjson = require "cjson"
-- ========================================
-- 获取正则捕获组中的参数
-- ========================================
-- ngx.var[1]: 获取第一个捕获组的内容
-- 例如:/api/product/1001,则ngx.var[1] = "1001"
local id = ngx.var[1]
-- 构建响应对象
local response = {
code = 200,
message = "success",
data = {
id = tonumber(id), -- 转换为数字类型
name = "商品" .. id, -- 字符串拼接
price = math.random(100, 10000) -- 随机价格
},
timestamp = ngx.now()
}
-- 输出JSON响应
ngx.say(cjson.encode(response))
}
}测试:
curl http://localhost/api/product/10014.4 查询 Go+Gin 服务
4.4.1 反向代理配置
启动 Go 服务:
cd multi-level-cache
go run main.go配置 OpenResty 反向代理:
# ========================================
# 反向代理配置详解
# ========================================
# upstream: 定义后端服务器组
# 用于负载均衡和健康检查
upstream gin_backend {
# 后端服务器地址
# 可以配置多个server实现负载均衡
server 127.0.0.1:8080;
# keepalive: 保持连接池大小
# 复用TCP连接,减少连接建立开销
# 32表示最多保持32个长连接
keepalive 32;
}
server {
listen 80;
server_name localhost;
# ========================================
# 反向代理location配置
# ========================================
location /gin/ {
# proxy_pass: 将请求转发到上游服务器
# 注意末尾的/,会将/gin/后面的路径追加到上游URL
# 例如:/gin/product/1001 -> http://gin_backend/product/1001
proxy_pass http://gin_backend/;
# ========================================
# 请求头设置(透传客户端信息)
# ========================================
# Host: 原始请求的Host头
proxy_set_header Host $host;
# X-Real-IP: 客户端真实IP
proxy_set_header X-Real-IP $remote_addr;
# X-Forwarded-For: 代理链IP记录
# $proxy_add_x_forwarded_for会追加当前客户端IP
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# X-Forwarded-Proto: 原始请求的协议(http/https)
proxy_set_header X-Forwarded-Proto $scheme;
}
}测试:
curl http://localhost/gin/product/10014.4.2 封装 HTTP 工具
/usr/local/openresty/nginx/lua/http_util.lua:
-- ========================================
-- HTTP工具模块
-- 功能:封装HTTP GET/POST请求,简化调用代码
-- ========================================
-- 引入OpenResty的HTTP客户端库
-- resty.http是OpenResty内置的高性能HTTP客户端
local http = require "resty.http"
-- 创建模块表,用于导出函数
local _M = {}
-- ========================================
-- HTTP GET请求封装
-- @param url: 请求URL
-- @param headers: 请求头表(可选)
-- @param timeout: 超时时间,单位毫秒(可选,默认5000ms)
-- @return: body响应体, err错误信息
-- ========================================
function _M.get(url, headers, timeout)
-- 创建HTTP客户端实例
local httpc = http.new()
-- 设置默认超时时间
-- or运算符:如果timeout为nil,则使用5000
timeout = timeout or 5000
-- 发送HTTP请求
-- request_uri: 发送请求并返回响应
local res, err = httpc:request_uri(url, {
method = "GET", -- 请求方法
headers = headers or {}, -- 请求头,默认为空表
timeout = timeout -- 超时时间
})
-- 请求失败处理
if not res then
return nil, err
end
-- 返回响应体
return res.body, nil
end
-- ========================================
-- HTTP POST请求封装
-- @param url: 请求URL
-- @param body: 请求体
-- @param headers: 请求头表(可选)
-- @param timeout: 超时时间,单位毫秒(可选,默认5000ms)
-- @return: body响应体, err错误信息
-- ========================================
function _M.post(url, body, headers, timeout)
local httpc = http.new()
timeout = timeout or 5000
local res, err = httpc:request_uri(url, {
method = "POST", -- 请求方法
body = body, -- 请求体
headers = headers or {}, -- 请求头
timeout = timeout -- 超时时间
})
if not res then
return nil, err
end
return res.body, nil
end
-- 返回模块表,使其可被require引入
return _M4.4.3 调用 Gin 接口并合并商品+库存数据
/usr/local/openresty/nginx/lua/product_detail.lua:
-- ========================================
-- 商品详情查询脚本
-- 功能:调用Gin服务获取商品信息和库存信息,合并后返回
-- 演示:如何在OpenResty中聚合多个后端服务的数据
-- ========================================
local cjson = require "cjson"
local http_util = require "lua.http_util"
-- Gin服务地址配置
local GIN_HOST = "http://127.0.0.1:8080"
-- 构建统一响应格式
local function buildResponse(code, message, data)
return {
code = code,
message = message,
data = data,
timestamp = ngx.now()
}
end
-- ========================================
-- 查询商品基本信息
-- @param id: 商品ID
-- @return: 商品数据表, 错误信息
-- ========================================
local function getProduct(id)
-- 构建请求URL
local url = GIN_HOST .. "/product/" .. id
-- 发送HTTP GET请求
-- 参数:URL, 请求头, 超时时间(3秒)
local body, err = http_util.get(url, {
["Content-Type"] = "application/json"
}, 3000)
-- 请求失败处理
if not body then
-- ngx.log: 记录日志
-- ngx.ERR: 错误级别日志
ngx.log(ngx.ERR, "查询商品失败: ", err)
return nil, err
end
-- 解析JSON响应
local data = cjson.decode(body)
-- 检查业务状态码
if data.code == 200 then
return data.data
end
return nil, "查询失败"
end
-- ========================================
-- 查询商品库存信息
-- @param productId: 商品ID
-- @return: 库存数据表, 错误信息
-- ========================================
local function getStock(productId)
local url = GIN_HOST .. "/stock/" .. productId
local body, err = http_util.get(url, {
["Content-Type"] = "application/json"
}, 3000)
if not body then
ngx.log(ngx.ERR, "查询库存失败: ", err)
return nil, err
end
local data = cjson.decode(body)
if data.code == 200 then
return data.data
end
return nil, "查询失败"
end
-- ========================================
-- 合并商品和库存数据
-- @param product: 商品信息表
-- @param stock: 库存信息表
-- @return: 合并后的商品详情表
-- ========================================
local function mergeProductDetail(product, stock)
return {
id = product.id,
name = product.name,
price = product.price,
description = product.description,
image = product.image,
stock = stock.stock,
version = stock.version
}
end
-- ========================================
-- 主函数:处理请求的核心逻辑
-- ========================================
local function main()
-- 设置响应头
ngx.header["Content-Type"] = "application/json;charset=utf-8"
-- 获取路径参数(商品ID)
local id = ngx.var[1]
if not id then
local response = buildResponse(400, "缺少商品ID", cjson.null)
ngx.status = 400
ngx.say(cjson.encode(response))
return
end
-- 1. 查询商品基本信息
local product, err = getProduct(id)
if not product then
local response = buildResponse(500, "查询商品失败: " .. err, cjson.null)
ngx.status = 500
ngx.say(cjson.encode(response))
return
end
-- 2. 查询商品库存信息
local stock, err = getStock(id)
if not stock then
-- 库存查询失败时使用默认值
stock = {stock = 0, version = 0}
end
-- 3. 合并数据
local detail = mergeProductDetail(product, stock)
-- 4. 返回响应
local response = buildResponse(200, "success", detail)
ngx.say(cjson.encode(response))
end
-- 执行主函数
main()配置路由:
location ~ ^/api/detail/(\d+)$ {
default_type 'application/json';
content_by_lua_file lua/product_detail.lua;
}4.4.4 基于商品 ID 哈希负载均衡
配置负载均衡:
# ========================================
# 基于商品ID哈希的负载均衡配置
# 功能:同一商品的请求总是路由到同一台后端服务器
# 好处:提高本地缓存命中率,减少缓存重复
# ========================================
# 定义后端服务器组
upstream gin_backend {
server 127.0.0.1:8080; # Gin服务实例1
server 127.0.0.1:8081; # Gin服务实例2
server 127.0.0.1:8082; # Gin服务实例3
keepalive 32; # 保持连接池大小
}
server {
listen 80;
server_name localhost;
# ========================================
# 基于商品ID的一致性哈希负载均衡
# ========================================
location ~ ^/api/product/(\d+)$ {
# 将正则捕获组赋值给变量
set $product_id $1;
# ========================================
# 使用Lua计算目标后端服务器
# set_by_lua_block: 在rewrite阶段执行Lua代码,设置变量
# ========================================
set_by_lua_block $backend {
-- 获取商品ID
local product_id = ngx.var.product_id
-- 后端服务器列表
local backends = {"127.0.0.1:8080", "127.0.0.1:8081", "127.0.0.1:8082"}
-- ========================================
-- 计算哈希值(简单字符串哈希)
-- 使用类似Java String.hashCode的算法
-- ========================================
local hash = 0
for i = 1, #product_id do
-- string.byte: 获取字符的ASCII码
-- 哈希公式: hash = hash * 31 + char
hash = (hash * 31 + string.byte(product_id, i)) % 10000
end
-- ========================================
-- 根据哈希值选择后端服务器
-- 取模运算确保结果在数组范围内
-- Lua数组索引从1开始,所以+1
-- ========================================
local index = (hash % #backends) + 1
return backends[index]
}
# 使用计算出的后端地址进行代理
# $backend是上面Lua代码设置的变量
proxy_pass http://$backend/product/$product_id;
proxy_set_header Host $host;
}
}4.5 Redis 缓存预热(Go 版)
Redis 客户端引入:
go get github.com/redis/go-redis/v9Redis 客户端封装:
cache/redis_cache.go:
// ========================================
// Redis缓存客户端封装
// 功能:提供统一的Redis缓存操作接口
// ========================================
package cache
import (
"context"
"encoding/json"
"fmt"
"time"
"github.com/redis/go-redis/v9"
"multi-level-cache/config"
)
// RedisCache Redis缓存结构体
type RedisCache struct {
client *redis.Client // Redis客户端实例
ttl time.Duration // 默认过期时间
}
// NewRedisCache 创建Redis缓存实例
// 返回: RedisCache实例, 错误信息
func NewRedisCache() (*RedisCache, error) {
// 创建Redis客户端
client := redis.NewClient(&redis.Options{
Addr: config.AppConfig.Redis.Addr, // Redis服务器地址
Password: config.AppConfig.Redis.Password, // Redis密码
DB: config.AppConfig.Redis.DB, // Redis数据库编号
PoolSize: 100, // 连接池大小
})
// 创建带超时的上下文,用于连接测试
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 测试连接是否成功
if err := client.Ping(ctx).Err(); err != nil {
return nil, fmt.Errorf("连接Redis失败: %w", err)
}
return &RedisCache{
client: client,
ttl: config.AppConfig.Cache.RedisCacheTTL, // 从配置读取默认TTL
}, nil
}
// Set 设置缓存
// 参数: ctx上下文, key缓存键, value缓存值(任意类型)
// 说明: 自动将value序列化为JSON存储
func (rc *RedisCache) Set(ctx context.Context, key string, value interface{}) error {
// 将value序列化为JSON字节数组
data, err := json.Marshal(value)
if err != nil {
return err
}
// 存储到Redis,设置过期时间
return rc.client.Set(ctx, key, data, rc.ttl).Err()
}
// Get 获取缓存
// 参数: ctx上下文, key缓存键, dest目标结构体指针
// 说明: 自动将JSON反序列化到dest
func (rc *RedisCache) Get(ctx context.Context, key string, dest interface{}) error {
// 从Redis获取数据
data, err := rc.client.Get(ctx, key).Result()
if err != nil {
return err
}
// 反序列化JSON到目标结构体
return json.Unmarshal([]byte(data), dest)
}
// Delete 删除缓存
func (rc *RedisCache) Delete(ctx context.Context, key string) error {
return rc.client.Del(ctx, key).Err()
}
// Exists 检查缓存是否存在
// 返回: 是否存在, 错误信息
func (rc *RedisCache) Exists(ctx context.Context, key string) (bool, error) {
val, err := rc.client.Exists(ctx, key).Result()
if err != nil {
return false, err
}
return val > 0, nil
}
// Close 关闭Redis连接
func (rc *RedisCache) Close() error {
return rc.client.Close()
}缓存预热服务:
service/cache_warmup.go:
// ========================================
// 缓存预热服务
// 功能:服务启动时将数据预加载到Redis和本地缓存
// 目的:避免冷启动时大量请求打到数据库
// ========================================
package service
import (
"context"
"fmt"
"log"
"multi-level-cache/cache"
"multi-level-cache/dao"
"multi-level-cache/model"
)
// CacheWarmupService 缓存预热服务结构体
type CacheWarmupService struct {
localCache *cache.LocalCache // 本地缓存实例
redisCache *cache.RedisCache // Redis缓存实例
}
// NewCacheWarmupService 创建缓存预热服务实例
func NewCacheWarmupService(localCache *cache.LocalCache, redisCache *cache.RedisCache) *CacheWarmupService {
return &CacheWarmupService{
localCache: localCache,
redisCache: redisCache,
}
}
// WarmupAll 全量预热:将所有商品数据加载到Redis
// 适用场景:服务启动时执行,确保缓存中有数据
func (s *CacheWarmupService) WarmupAll(ctx context.Context) error {
log.Println("开始缓存预热...")
// 1. 查询所有有效商品ID
query := `SELECT id FROM tb_product WHERE status = 1`
rows, err := dao.DB.Query(query)
if err != nil {
return fmt.Errorf("查询商品列表失败: %w", err)
}
defer rows.Close()
// 2. 收集所有商品ID
var productIDs []int64
for rows.Next() {
var id int64
if err := rows.Scan(&id); err != nil {
log.Printf("扫描商品ID失败: %v", err)
continue
}
productIDs = append(productIDs, id)
}
log.Printf("共需要预热 %d 个商品", len(productIDs))
// 3. 逐个预热商品数据
successCount := 0
for _, id := range productIDs {
if err := s.warmupProduct(ctx, id); err != nil {
log.Printf("预热商品 %d 失败: %v", id, err)
continue
}
successCount++
}
log.Printf("缓存预热完成,成功 %d 个,失败 %d 个", successCount, len(productIDs)-successCount)
return nil
}
// warmupProduct 预热单个商品
// 步骤:查询商品信息 -> 查询库存信息 -> 合并数据 -> 写入Redis
func (s *CacheWarmupService) warmupProduct(ctx context.Context, id int64) error {
// 1. 查询商品基本信息
product, err := dao.GetProductByID(id)
if err != nil {
return err
}
// 2. 查询库存信息(失败时使用默认值)
stock, err := dao.GetStockByProductID(id)
if err != nil {
log.Printf("查询商品 %d 库存失败: %v", id, err)
stock = &model.Stock{ProductID: id, Stock: 0}
}
// 3. 组装商品详情数据
detail := &model.ProductDetail{
Product: *product,
Stock: *stock,
}
// 4. 写入Redis缓存
key := fmt.Sprintf("product:detail:%d", id)
if err := s.redisCache.Set(ctx, key, detail); err != nil {
return err
}
return nil
}
// WarmupHotProducts 热点商品预热:将热点商品加载到本地缓存
// 适用场景:将访问频繁的商品预热到本地缓存,提高访问速度
func (s *CacheWarmupService) WarmupHotProducts(ctx context.Context, productIDs []int64) error {
log.Printf("开始预热 %d 个热点商品到本地缓存", len(productIDs))
for _, id := range productIDs {
key := fmt.Sprintf("product:detail:%d", id)
// 1. 先从Redis获取
var detail model.ProductDetail
err := s.redisCache.Get(ctx, key, &detail)
if err != nil {
// Redis中没有,从数据库加载
if err := s.warmupProduct(ctx, id); err != nil {
log.Printf("预热热点商品 %d 失败: %v", id, err)
continue
}
// 重新从Redis获取
if err := s.redisCache.Get(ctx, key, &detail); err != nil {
continue
}
}
// 2. 写入本地缓存
if err := s.localCache.Set(key, detail); err != nil {
log.Printf("写入本地缓存失败: %v", err)
}
}
log.Println("热点商品预热完成")
return nil
}服务启动时预热:
main.go:
// ========================================
// 多级缓存服务主程序
// 功能:初始化各组件,启动缓存预热,启动HTTP服务
// ========================================
package main
import (
"context"
"fmt"
"log"
"multi-level-cache/cache"
"multi-level-cache/config"
"multi-level-cache/dao"
"multi-level-cache/router"
"multi-level-cache/service"
)
func main() {
// ========================================
// 1. 初始化数据库连接
// ========================================
if err := dao.InitDB(); err != nil {
log.Fatalf("初始化数据库失败: %v", err)
}
defer dao.DB.Close() // 程序退出时关闭数据库连接
// ========================================
// 2. 初始化本地缓存
// ========================================
localCache, err := cache.NewLocalCache()
if err != nil {
log.Fatalf("初始化本地缓存失败: %v", err)
}
defer localCache.Close()
// ========================================
// 3. 初始化Redis缓存
// ========================================
redisCache, err := cache.NewRedisCache()
if err != nil {
log.Fatalf("初始化Redis缓存失败: %v", err)
}
defer redisCache.Close()
// ========================================
// 4. 创建缓存预热服务
// ========================================
warmupService := service.NewCacheWarmupService(localCache, redisCache)
// ========================================
// 5. 异步执行缓存预热
// ========================================
ctx := context.Background()
// 使用goroutine异步执行,不阻塞服务启动
go func() {
// 全量预热:将所有商品数据加载到Redis
if err := warmupService.WarmupAll(ctx); err != nil {
log.Printf("缓存预热失败: %v", err)
}
}()
// 热点商品预热:将热点商品加载到本地缓存
hotProductIDs := []int64{1001, 1002, 1003, 1004, 1005}
go func() {
if err := warmupService.WarmupHotProducts(ctx, hotProductIDs); err != nil {
log.Printf("热点商品预热失败: %v", err)
}
}()
// ========================================
// 6. 创建业务服务
// ========================================
productService := service.NewProductService(localCache, redisCache)
// ========================================
// 7. 启动HTTP服务
// ========================================
r := router.SetupRouter(productService)
addr := fmt.Sprintf(":%d", config.AppConfig.Server.Port)
log.Printf("服务启动在 %s", addr)
if err := r.Run(addr); err != nil {
log.Fatalf("启动服务失败: %v", err)
}
}4.6 OpenResty 查询 Redis 缓存
4.6.1 封装 Redis 工具类
/usr/local/openresty/nginx/lua/redis_util.lua:
-- ========================================
-- Redis工具模块
-- 功能:封装Redis操作,提供连接池管理
-- ========================================
-- 引入OpenResty的Redis客户端库
local redis = require "resty.redis"
-- 创建模块表
local _M = {}
-- ========================================
-- 创建Redis连接
-- @return: Redis连接实例, 错误信息
-- ========================================
function _M.new()
-- 创建Redis实例
local red = redis:new()
-- 设置超时时间(毫秒)
-- 包括连接超时、发送超时、接收超时
red:set_timeout(1000)
-- 连接Redis服务器
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
return nil, err
end
return red, nil
end
-- ========================================
-- 获取缓存值
-- @param key: 缓存键
-- @return: 缓存值, 错误信息
-- ========================================
function _M.get(key)
-- 创建连接
local red, err = _M.new()
if not red then
return nil, err
end
-- 执行GET命令
local res, err = red:get(key)
-- ========================================
-- 连接池管理(重要!)
-- set_keepalive: 将连接放回连接池,而不是关闭
-- 参数1: 最大空闲时间(毫秒),超过则关闭
-- 参数2: 连接池大小
-- 好处: 避免频繁创建/销毁连接,提高性能
-- ========================================
red:set_keepalive(10000, 100)
-- 检查是否为空值
-- ngx.null: OpenResty中表示Redis返回的nil
if res == ngx.null then
return nil, "not found"
end
return res, nil
end
-- ========================================
-- 设置缓存值
-- @param key: 缓存键
-- @param value: 缓存值
-- @param ttl: 过期时间(秒,可选)
-- @return: 是否成功, 错误信息
-- ========================================
function _M.set(key, value, ttl)
local red, err = _M.new()
if not red then
return nil, err
end
-- 执行SET命令
local ok, err = red:set(key, value)
if not ok then
red:set_keepalive(10000, 100)
return nil, err
end
-- 设置过期时间(如果指定)
if ttl then
red:expire(key, ttl)
end
-- 放回连接池
red:set_keepalive(10000, 100)
return true, nil
end
-- ========================================
-- 删除缓存
-- @param key: 缓存键
-- @return: 删除的数量, 错误信息
-- ========================================
function _M.delete(key)
local red, err = _M.new()
if not red then
return nil, err
end
-- 执行DEL命令
local res, err = red:del(key)
red:set_keepalive(10000, 100)
return res, nil
end
-- ========================================
-- 获取Hash所有字段
-- @param key: Hash键名
-- @return: 字段-值表, 错误信息
-- ========================================
function _M.hgetall(key)
local red, err = _M.new()
if not red then
return nil, err
end
-- 执行HGETALL命令
local res, err = red:hgetall(key)
red:set_keepalive(10000, 100)
if not res then
return nil, err
end
-- ========================================
-- 将数组转换为表
-- Redis返回格式: {field1, value1, field2, value2, ...}
-- 转换后: {field1=value1, field2=value2, ...}
-- ========================================
local result = {}
for i = 1, #res, 2 do
result[res[i]] = res[i + 1]
end
return result, nil
end
-- 返回模块
return _M4.6.2 先查 Redis,未命中再查 Gin
/usr/local/openresty/nginx/lua/product_cache.lua:
-- ========================================
-- 商品缓存查询脚本(二级缓存:Redis → Gin)
-- 流程:先查Redis缓存,未命中则查询Gin服务并写入Redis
-- ========================================
local cjson = require "cjson"
local redis_util = require "lua.redis_util"
local http_util = require "lua.http_util"
-- 配置常量
local GIN_HOST = "http://127.0.0.1:8080" -- Gin服务地址
local REDIS_TTL = 1800 -- Redis缓存过期时间(秒)
-- 构建统一响应格式
local function buildResponse(code, message, data)
return {
code = code,
message = message,
data = data,
timestamp = ngx.now()
}
end
-- ========================================
-- 从Gin服务查询商品数据
-- @param id: 商品ID
-- @return: 商品数据, 错误信息
-- ========================================
local function queryFromGin(id)
local url = GIN_HOST .. "/product/" .. id
local body, err = http_util.get(url, {
["Content-Type"] = "application/json"
}, 3000)
if not body then
return nil, err
end
local data = cjson.decode(body)
if data.code == 200 then
return data.data, nil
end
return nil, "查询失败"
end
-- ========================================
-- 主函数:二级缓存查询逻辑
-- ========================================
local function main()
ngx.header["Content-Type"] = "application/json;charset=utf-8"
-- 1. 获取商品ID
local id = ngx.var[1]
if not id then
local response = buildResponse(400, "缺少商品ID", cjson.null)
ngx.status = 400
ngx.say(cjson.encode(response))
return
end
-- 构建缓存键
local cacheKey = "product:detail:" .. id
-- ========================================
-- 2. 查询Redis缓存
-- ========================================
local cacheData, err = redis_util.get(cacheKey)
if cacheData then
-- 缓存命中,直接返回
ngx.log(ngx.INFO, "Redis缓存命中: ", cacheKey)
local detail = cjson.decode(cacheData)
local response = buildResponse(200, "success (from Redis)", detail)
ngx.say(cjson.encode(response))
return
end
-- 缓存未命中,记录日志
ngx.log(ngx.INFO, "Redis缓存未命中: ", cacheKey)
-- ========================================
-- 3. 查询Gin服务(回源)
-- ========================================
local detail, err = queryFromGin(id)
if not detail then
local response = buildResponse(500, "查询失败: " .. err, cjson.null)
ngx.status = 500
ngx.say(cjson.encode(response))
return
end
-- ========================================
-- 4. 写入Redis缓存(回填)
-- ========================================
local jsonData = cjson.encode(detail)
redis_util.set(cacheKey, jsonData, REDIS_TTL)
ngx.log(ngx.INFO, "写入Redis缓存: ", cacheKey)
-- 5. 返回响应
local response = buildResponse(200, "success (from Gin)", detail)
ngx.say(cjson.encode(response))
end
main()配置路由:
location ~ ^/api/cache/product/(\d+)$ {
default_type 'application/json';
content_by_lua_file lua/product_cache.lua;
}测试:
curl http://localhost/api/cache/product/10014.7 Nginx 本地缓存(共享字典)
4.7.1 配置 lua_shared_dict
编辑nginx.conf:
http {
# ========================================
# 共享字典配置(Nginx本地缓存)
# ========================================
# lua_shared_dict: 在worker进程间共享的内存区域
# 语法: lua_shared_dict <名称> <大小>
# 特点:
# 1. 所有worker进程共享同一块内存
# 2. 基于内存的极快访问速度
# 3. 支持过期时间设置
# 4. 支持LRU淘汰策略
# ========================================
# 商品缓存:128MB,存储商品详情
lua_shared_dict product_cache 128m;
# 库存缓存:64MB,存储商品库存
lua_shared_dict stock_cache 64m;
# 用户缓存:64MB,存储用户信息
lua_shared_dict user_cache 64m;
server {
listen 80;
server_name localhost;
}
}4.7.2 完整三级查询:Nginx 本地缓存 → Redis → Gin
/usr/local/openresty/nginx/lua/product_multi_cache.lua:
-- ========================================
-- 多级缓存查询脚本(三级缓存)
-- 流程:Nginx本地缓存 → Redis缓存 → Gin服务
-- 核心思想:逐层回源,热点数据在离用户最近的地方
-- ========================================
local cjson = require "cjson"
local redis_util = require "lua.redis_util"
local http_util = require "lua.http_util"
-- ========================================
-- 缓存配置
-- ========================================
local GIN_HOST = "http://127.0.0.1:8080" -- Gin服务地址
local NGINX_CACHE_TTL = 300 -- Nginx缓存过期时间(5分钟)
local REDIS_TTL = 1800 -- Redis缓存过期时间(30分钟)
-- ========================================
-- 获取Nginx本地缓存
-- @param key: 缓存键
-- @return: 缓存值, 错误信息
-- ========================================
local function getNginxCache(key)
-- 获取共享字典实例
-- ngx.shared.<名称>: 获取nginx.conf中定义的共享字典
local cache = ngx.shared.product_cache
-- 从共享字典获取值
-- 返回: value值, flags标志位, err错误
local value, flags = cache:get(key)
if value then
return value, nil
end
return nil, "not found"
end
-- ========================================
-- 设置Nginx本地缓存
-- @param key: 缓存键
-- @param value: 缓存值
-- @param ttl: 过期时间(秒)
-- @return: 是否成功
-- ========================================
local function setNginxCache(key, value, ttl)
local cache = ngx.shared.product_cache
-- 设置缓存值
-- 返回: success是否成功, err错误, forcible是否强制淘汰
local success, err, forcible = cache:set(key, value, ttl)
if not success then
ngx.log(ngx.ERR, "设置Nginx缓存失败: ", err)
return false
end
-- forcible为true表示缓存已满,强制淘汰了旧数据
if forcible then
ngx.log(ngx.WARN, "Nginx缓存已满,强制淘汰旧数据")
end
return true
end
-- ========================================
-- 从Gin服务查询商品数据
-- ========================================
local function queryFromGin(id)
local url = GIN_HOST .. "/product/" .. id
local body, err = http_util.get(url, {
["Content-Type"] = "application/json"
}, 3000)
if not body then
return nil, err
end
local data = cjson.decode(body)
if data.code == 200 then
return data.data, nil
end
return nil, "查询失败"
end
-- 构建统一响应格式
local function buildResponse(code, message, data)
return {
code = code,
message = message,
data = data,
timestamp = ngx.now()
}
end
-- ========================================
-- 主函数:三级缓存查询逻辑
-- ========================================
local function main()
ngx.header["Content-Type"] = "application/json;charset=utf-8"
-- 1. 获取商品ID
local id = ngx.var[1]
if not id then
local response = buildResponse(400, "缺少商品ID", cjson.null)
ngx.status = 400
ngx.say(cjson.encode(response))
return
end
local cacheKey = "product:detail:" .. id
-- ========================================
-- 第一级:查询Nginx本地缓存(最快)
-- ========================================
local nginxCacheData, err = getNginxCache(cacheKey)
if nginxCacheData then
ngx.log(ngx.INFO, "Nginx本地缓存命中: ", cacheKey)
local detail = cjson.decode(nginxCacheData)
local response = buildResponse(200, "success (from Nginx)", detail)
ngx.say(cjson.encode(response))
return
end
ngx.log(ngx.INFO, "Nginx本地缓存未命中: ", cacheKey)
-- ========================================
-- 第二级:查询Redis缓存(中等)
-- ========================================
local redisCacheData, err = redis_util.get(cacheKey)
if redisCacheData then
ngx.log(ngx.INFO, "Redis缓存命中: ", cacheKey)
local detail = cjson.decode(redisCacheData)
-- 回填到Nginx本地缓存
setNginxCache(cacheKey, redisCacheData, NGINX_CACHE_TTL)
local response = buildResponse(200, "success (from Redis)", detail)
ngx.say(cjson.encode(response))
return
end
ngx.log(ngx.INFO, "Redis缓存未命中: ", cacheKey)
-- ========================================
-- 第三级:查询Gin服务(最慢,回源)
-- ========================================
local detail, err = queryFromGin(id)
if not detail then
local response = buildResponse(500, "查询失败: " .. err, cjson.null)
ngx.status = 500
ngx.say(cjson.encode(response))
return
end
-- ========================================
-- 回填缓存(写入Redis和Nginx)
-- ========================================
local jsonData = cjson.encode(detail)
-- 写入Redis缓存
redis_util.set(cacheKey, jsonData, REDIS_TTL)
ngx.log(ngx.INFO, "写入Redis缓存: ", cacheKey)
-- 写入Nginx本地缓存
setNginxCache(cacheKey, jsonData, NGINX_CACHE_TTL)
ngx.log(ngx.INFO, "写入Nginx本地缓存: ", cacheKey)
-- 返回响应
local response = buildResponse(200, "success (from Gin)", detail)
ngx.say(cjson.encode(response))
end
main()配置路由:
location ~ ^/api/multi/product/(\d+)$ {
default_type 'application/json';
content_by_lua_file lua/product_multi_cache.lua;
}测试:
# 第一次请求(Nginx未命中 → Redis未命中 → 查询Gin)
curl http://localhost/api/multi/product/1001
# 第二次请求(Nginx命中)
curl http://localhost/api/multi/product/1001
# 等待5分钟后(Nginx过期 → Redis命中)
curl http://localhost/api/multi/product/10014.7.3 分级过期时间设置
过期时间策略:
Nginx本地缓存:5分钟(热点数据)
Redis缓存:30分钟(全量数据)
应用本地缓存:1分钟(极热点数据)配置示例:
local NGINX_CACHE_TTL = 300 -- 5分钟
local REDIS_TTL = 1800 -- 30分钟
local APP_LOCAL_CACHE_TTL = 60 -- 1分钟过期时间设置原则:
-
越靠近客户端,过期时间越短
- Nginx 本地缓存:分钟级
- Redis 缓存:小时级
- 数据库:永久
-
热点数据过期时间更短
- 秒杀商品:1-5 分钟
- 普通商品:10-30 分钟
- 冷门商品:1-2 小时
-
考虑数据一致性要求
- 库存数据:短过期时间
- 商品信息:中等过期时间
- 历史数据:长过期时间
五、缓存同步与数据一致性
5.1 三种同步策略:过期、双写、异步通知
5.1.1 过期时间策略
原理:
为缓存设置过期时间,过期后自动删除,下次访问时重新加载。
优点:
- 实现简单
- 无需额外同步逻辑
- 适用于对一致性要求不高的场景
缺点:
- 过期前数据可能不一致
- 过期瞬间可能有大量请求打到数据库
- 无法实时同步
实现:
func (s *ProductService) GetProductDetail(id int64) (*model.ProductDetail, error) {
cacheKey := fmt.Sprintf("product:detail:%d", id)
var detail model.ProductDetail
err := s.localCache.Get(cacheKey, &detail)
if err == nil {
return &detail, nil
}
product, err := dao.GetProductByID(id)
if err != nil {
return nil, err
}
stock, err := dao.GetStockByProductID(id)
if err != nil {
stock = &model.Stock{ProductID: id, Stock: 0}
}
detail = model.ProductDetail{
Product: *product,
Stock: *stock,
}
s.localCache.Set(cacheKey, detail)
return &detail, nil
}5.1.2 双写策略
原理:
更新数据库的同时,主动更新或删除缓存。
优点:
- 数据一致性较好
- 实时更新缓存
- 适用于写操作频繁的场景
缺点:
- 需要额外的同步逻辑
- 可能出现数据不一致(并发问题)
- 增加写操作的开销
实现:
func (s *ProductService) UpdateProductStock(productID int64, stock int) error {
tx, err := dao.DB.Begin()
if err != nil {
return err
}
defer tx.Rollback()
query := `UPDATE tb_seckill_voucher SET stock = ? WHERE voucher_id = ?`
_, err = tx.Exec(query, stock, productID)
if err != nil {
return err
}
if err := tx.Commit(); err != nil {
return err
}
cacheKey := fmt.Sprintf("product:detail:%d", productID)
_ = s.localCache.Delete(cacheKey)
_ = s.redisCache.Delete(context.Background(), cacheKey)
return nil
}5.1.3 异步通知策略
原理:
使用消息队列或 Canal 监听数据库变更,异步更新缓存。
优点:
- 解耦数据库和缓存
- 不影响主业务性能
- 可靠性高
缺点:
- 实现复杂
- 需要额外的组件
- 存在一定的延迟
实现:
func (s *ProductService) UpdateProductStockAsync(productID int64, stock int) error {
tx, err := dao.DB.Begin()
if err != nil {
return err
}
defer tx.Rollback()
query := `UPDATE tb_seckill_voucher SET stock = ? WHERE voucher_id = ?`
_, err = tx.Exec(query, stock, productID)
if err != nil {
return err
}
if err := tx.Commit(); err != nil {
return err
}
event := CacheUpdateEvent{
Type: "stock_update",
ProductID: productID,
Stock: stock,
Timestamp: time.Now().Unix(),
}
eventData, _ := json.Marshal(event)
return s.redisClient.Publish(context.Background(), "cache:update", eventData).Err()
}
func (s *ProductService) SubscribeCacheUpdate(ctx context.Context) {
pubsub := s.redisClient.Subscribe(ctx, "cache:update")
_, err := pubsub.Receive(ctx)
if err != nil {
log.Printf("订阅失败: %v", err)
return
}
ch := pubsub.Channel()
for msg := range ch {
var event CacheUpdateEvent
if err := json.Unmarshal([]byte(msg.Payload), &event); err != nil {
log.Printf("解析消息失败: %v", err)
continue
}
cacheKey := fmt.Sprintf("product:detail:%d", event.ProductID)
_ = s.localCache.Delete(cacheKey)
_ = s.redisCache.Delete(ctx, cacheKey)
log.Printf("已删除商品 %d 的缓存", event.ProductID)
}
}
type CacheUpdateEvent struct {
Type string `json:"type"`
ProductID int64 `json:"product_id"`
Stock int `json:"stock"`
Timestamp int64 `json:"timestamp"`
}5.2 基于 Canal 实现零侵入缓存更新
5.2.1 Canal 简介
Canal 是阿里巴巴开源的 MySQL 数据库增量日志解析工具,提供增量数据订阅和消费功能。
工作原理:
- Canal 模拟 MySQL slave 的交互协议
- 伪装自己为 MySQL slave,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave
- Canal 解析 binary log 对象(原始为 byte 流)
架构:
MySQL Master
|
| binlog
v
Canal Server
|
| 消息队列/直接推送
v
Go应用服务
|
| 更新缓存
v
Redis + 本地缓存5.2.2 Canal 安装与配置
安装 Canal:
# 下载Canal
wget https://github.com/alibaba/canal/releases/download/canal-1.1.7/canal.deployer-1.1.7.tar.gz
# 解压
mkdir -p /usr/local/canal
tar -zxvf canal.deployer-1.1.7.tar.gz -C /usr/local/canal
# 配置Canal
cd /usr/local/canal
vi conf/example/instance.properties配置 MySQL:
编辑my.cnf:
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1配置 Canal 实例:
编辑conf/example/instance.properties:
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset=UTF-8
canal.instance.filter.regex=shop\\..*启动 Canal:
cd /usr/local/canal
./bin/startup.sh5.2.3 Go 服务监听 Canal 更新缓存
安装 Canal Go 客户端:
go get github.com/withlin/canal-goCanal 客户端实现:
canal/canal_client.go:
package canal
import (
"context"
"encoding/json"
"fmt"
"log"
"multi-level-cache/cache"
"github.com/withlin/canal-go/client"
"github.com/withlin/canal-go/protocol"
)
type CanalClient struct {
connector *client.SimpleCanalConnector
localCache *cache.LocalCache
redisCache *cache.RedisCache
}
func NewCanalClient(localCache *cache.LocalCache, redisCache *cache.RedisCache) *CanalClient {
connector := client.NewSimpleCanalConnector(
"127.0.0.1",
11111,
"",
"",
"example",
60000,
60*60*1000,
)
return &CanalClient{
connector: connector,
localCache: localCache,
redisCache: redisCache,
}
}
func (c *CanalClient) Connect() error {
err := c.connector.Connect()
if err != nil {
return fmt.Errorf("连接Canal失败: %w", err)
}
err = c.connector.Subscribe("shop\\.tb_product,shop\\.tb_seckill_voucher")
if err != nil {
return fmt.Errorf("订阅失败: %w", err)
}
return nil
}
func (c *CanalClient) Start(ctx context.Context) {
for {
select {
case <-ctx.Done():
return
default:
message, err := c.connector.Get(100, nil, nil)
if err != nil {
log.Printf("获取消息失败: %v", err)
continue
}
if len(message.Entries) == 0 {
continue
}
for _, entry := range message.Entries {
if entry.GetEntryType() == protocol.EntryType_ROWDATA {
c.processEntry(entry)
}
}
}
}
}
func (c *CanalClient) processEntry(entry protocol.Entry) {
rowChange := &protocol.RowChange{}
err := proto.Unmarshal(entry.GetStoreValue(), rowChange)
if err != nil {
log.Printf("解析RowChange失败: %v", err)
return
}
eventType := rowChange.GetEventType()
tableName := entry.GetTableName()
for _, rowData := range rowChange.GetRowDatas() {
var productID int64
if tableName == "tb_product" {
if eventType == protocol.EventType_DELETE {
productID = c.getColumnValue(rowData.GetBeforeColumns(), "id")
} else {
productID = c.getColumnValue(rowData.GetAfterColumns(), "id")
}
} else if tableName == "tb_seckill_voucher" {
if eventType == protocol.EventType_DELETE {
productID = c.getColumnValue(rowData.GetBeforeColumns(), "voucher_id")
} else {
productID = c.getColumnValue(rowData.GetAfterColumns(), "voucher_id")
}
}
if productID > 0 {
c.invalidateCache(productID)
}
}
}
func (c *CanalClient) getColumnValue(columns []*protocol.Column, columnName string) int64 {
for _, col := range columns {
if col.GetName() == columnName {
var value int64
fmt.Sscanf(col.GetValue(), "%d", &value)
return value
}
}
return 0
}
func (c *CanalClient) invalidateCache(productID int64) {
cacheKey := fmt.Sprintf("product:detail:%d", productID)
ctx := context.Background()
if err := c.localCache.Delete(cacheKey); err != nil {
log.Printf("删除本地缓存失败: %v", err)
}
if err := c.redisCache.Delete(ctx, cacheKey); err != nil {
log.Printf("删除Redis缓存失败: %v", err)
}
log.Printf("已删除商品 %d 的缓存(Canal触发)", productID)
}
func (c *CanalClient) Close() {
c.connector.Disconnection()
}主程序集成:
package main
import (
"context"
"fmt"
"log"
"multi-level-cache/cache"
"multi-level-cache/canal"
"multi-level-cache/config"
"multi-level-cache/dao"
"multi-level-cache/router"
"multi-level-cache/service"
"os"
"os/signal"
"syscall"
)
func main() {
if err := dao.InitDB(); err != nil {
log.Fatalf("初始化数据库失败: %v", err)
}
defer dao.DB.Close()
localCache, err := cache.NewLocalCache()
if err != nil {
log.Fatalf("初始化本地缓存失败: %v", err)
}
defer localCache.Close()
redisCache, err := cache.NewRedisCache()
if err != nil {
log.Fatalf("初始化Redis缓存失败: %v", err)
}
defer redisCache.Close()
canalClient := canal.NewCanalClient(localCache, redisCache)
if err := canalClient.Connect(); err != nil {
log.Fatalf("连接Canal失败: %v", err)
}
defer canalClient.Close()
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
go canalClient.Start(ctx)
productService := service.NewProductService(localCache, redisCache)
r := router.SetupRouter(productService)
go func() {
addr := fmt.Sprintf(":%d", config.AppConfig.Server.Port)
log.Printf("服务启动在 %s", addr)
if err := r.Run(addr); err != nil {
log.Fatalf("启动服务失败: %v", err)
}
}()
quit := make(chan os.Signal, 1)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM)
<-quit
log.Println("正在关闭服务...")
cancel()
}5.3 缓存同步最佳实践
5.3.1 缓存更新策略选择
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| 读多写少 | 过期时间 | 实现简单,性能好 |
| 写多读少 | 双写 | 保证数据一致性 |
| 高并发写 | Canal 异步 | 解耦,不影响主业务 |
| 强一致性要求 | 分布式锁 + 双写 | 保证数据强一致 |
| 弱一致性要求 | 过期时间 | 简单可靠 |
5.3.2 延迟双删策略
原理:
先删除缓存,再更新数据库,延迟一段时间后再删除缓存。
流程:
1. 删除缓存
|
v
2. 更新数据库
|
v
3. 延迟N毫秒(如500ms)
|
v
4. 再次删除缓存实现:
func (s *ProductService) UpdateProductStockWithDoubleDelete(productID int64, stock int) error {
cacheKey := fmt.Sprintf("product:detail:%d", productID)
_ = s.localCache.Delete(cacheKey)
_ = s.redisCache.Delete(context.Background(), cacheKey)
tx, err := dao.DB.Begin()
if err != nil {
return err
}
defer tx.Rollback()
query := `UPDATE tb_seckill_voucher SET stock = ? WHERE voucher_id = ?`
_, err = tx.Exec(query, stock, productID)
if err != nil {
return err
}
if err := tx.Commit(); err != nil {
return err
}
time.AfterFunc(500*time.Millisecond, func() {
_ = s.localCache.Delete(cacheKey)
_ = s.redisCache.Delete(context.Background(), cacheKey)
log.Printf("延迟双删完成,商品ID: %d", productID)
})
return nil
}5.3.3 缓存穿透保护
问题:
查询不存在的数据,缓存和数据库都没有,导致每次请求都打到数据库。
解决方案:
- 空值缓存:缓存空值,设置短过期时间
- 布隆过滤器:在查询前先判断数据是否存在
实现:
func (s *ProductService) GetProductDetailWithProtection(id int64) (*model.ProductDetail, error) {
cacheKey := fmt.Sprintf("product:detail:%d", id)
nullKey := fmt.Sprintf("product:null:%d", id)
var detail model.ProductDetail
err := s.localCache.Get(cacheKey, &detail)
if err == nil {
return &detail, nil
}
var isNull bool
err = s.redisCache.Get(context.Background(), nullKey, &isNull)
if err == nil && isNull {
return nil, fmt.Errorf("商品不存在")
}
product, err := dao.GetProductByID(id)
if err != nil {
if err == sql.ErrNoRows {
s.redisCache.Set(context.Background(), nullKey, true, 5*time.Minute)
return nil, fmt.Errorf("商品不存在")
}
return nil, err
}
stock, err := dao.GetStockByProductID(id)
if err != nil {
stock = &model.Stock{ProductID: id, Stock: 0}
}
detail = model.ProductDetail{
Product: *product,
Stock: *stock,
}
s.localCache.Set(cacheKey, detail)
s.redisCache.Set(context.Background(), cacheKey, detail, 30*time.Minute)
return &detail, nil
}六、总结
6.1 多级缓存架构总结
核心思想:
逐层过滤请求,将热点数据放在离用户最近的地方,减少网络开销和后端压力。
架构层次:
- 浏览器缓存:静态资源、用户偏好
- Nginx 本地缓存:热点数据、极速访问
- Redis 分布式缓存:全量数据、共享存储
- 应用本地缓存:进程内缓存、零网络开销
- 数据库:持久化存储、数据源
6.2 技术选型建议
| 组件 | 推荐方案 | 原因 |
|---|---|---|
| Nginx | OpenResty | 支持 Lua,功能强大 |
| 本地缓存(Go) | BigCache | 零 GC、高性能 |
| 分布式缓存 | Redis Cluster | 高可用、可扩展 |
| 数据同步 | Canal | 零侵入、解耦 |
| 消息队列 | Redis Stream | 轻量级、可靠 |
6.3 性能优化建议
-
合理设置过期时间
- Nginx 缓存:分钟级
- Redis 缓存:小时级
- 本地缓存:秒级
-
预热关键数据
- 启动时预热热点数据
- 定期刷新缓存
- 避免冷启动问题
-
监控和告警
- 监控缓存命中率
- 监控缓存大小
- 设置合理的告警阈值
-
容灾和降级
- 缓存故障时降级到数据库
- 设置熔断和限流
- 保证系统可用性
6.4 注意事项
-
缓存一致性
- 选择合适的同步策略
- 考虑并发场景
- 必要时使用分布式锁
-
内存管理
- 合理设置缓存大小
- 监控内存使用情况
- 避免内存溢出
-
性能测试
- 压力测试验证性能
- 监控关键指标
- 持续优化
-
运维监控
- 完善的日志系统
- 实时监控告警
- 快速定位问题
参考资料:
- OpenResty 官方文档:https://openresty.org/cn/
- BigCache GitHub:https://github.com/allegro/bigcache
- Canal 官方文档:https://github.com/alibaba/canal
- Redis 官方文档:https://redis.io/documentation
Redis 高级篇之最佳实践
今日内容
- Redis 键值设计
- 批处理优化
- 服务端优化
- 集群最佳实践
1、Redis 键值设计
1.1、优雅的 key 结构
Redis 的 Key 虽然可以自定义,但最好遵循下面的几个最佳实践约定:
- 遵循基本格式:[业务名称]:[数据名]:[id]
- 长度不超过 44 字节
- 不包含特殊字符 例如:我们的登录业务,保存用户信息,其 key 可以设计成如下格式:
login:user:1001
login:user:1002
login:user:1003这样设计的好处:
- 可读性强
- 避免 key 冲突
- 方便管理
- 更节省内存: key 是 string 类型,底层编码包含 int、embstr 和 raw 三种。embstr 在小于 44 字节使用,采用连续内存空间,内存占用更小。当字节数大于 44 字节时,会转为 raw 模式存储,在 raw 模式下,内存空间不是连续的,而是采用一个指针指向了另外一段内存空间,在这段空间里存储 SDS 内容,这样空间不连续,访问的时候性能也就会收到影响,还有可能产生内存碎片
embstr编码(<44字节):
+--------+--------+--------+
| RedisObject | SDS(连续内存)|
+--------+--------+--------+
raw编码(>=44字节):
+--------+ +--------+
| RedisObject | --> | SDS(独立内存块)|
+--------+ +--------+1.2、拒绝 BigKey
BigKey 通常以 Key 的大小和 Key 中成员的数量来综合判定,例如:
- Key 本身的数据量过大:一个 String 类型的 Key,它的值为 5 MB
- Key 中的成员数过多:一个 ZSET 类型的 Key,它的成员数量为 10,000 个
- Key 中成员的数据量过大:一个 Hash 类型的 Key,它的成员数量虽然只有 1,000 个但这些成员的 Value(值)总大小为 100 MB 那么如何判断元素的大小呢?redis 也给我们提供了命令:
# 查看key存储的value占用的字节数
MEMORY USAGE keyname
# 查看字符串类型key的长度
STRLEN keyname
# 查看hash类型key的字段数量
HLEN keyname
# 查看list类型key的元素数量
LLEN keyname
# 查看set类型key的元素数量
SCARD keyname
# 查看zset类型key的成员数量
ZCARD keyname推荐值:
- 单个 key 的 value 小于 10KB
- 对于集合类型的 key,建议元素数量小于 1000
1.2.1、BigKey 的危害
- 网络阻塞
- 对 BigKey 执行读请求时,少量的 QPS 就可能导致带宽使用率被占满,导致 Redis 实例,乃至所在物理机变慢
- 数据倾斜
- BigKey 所在的 Redis 实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- Redis 阻塞
- 对元素较多的 hash、list、zset 等做运算会耗时较久,使主线程被阻塞
- CPU 压力
- 对 BigKey 的数据序列化和反序列化会导致 CPU 的使用率飙升,影响 Redis 实例和本机其它应用
1.2.2、如何发现 BigKey
①redis-cli —bigkeys
利用 redis-cli 提供的—bigkeys 参数,可以遍历分析所有 key,并返回 Key 的整体统计信息与每个数据的 Top1 的 big key
命令:redis-cli -a 密码 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far 'key1' with 1024 bytes
[00.00%] Biggest list found so far 'mylist' with 10000 items
[00.00%] Biggest hash found so far 'user:1001' with 500 fields
...
-------- summary -------
Sampled 10000 keys in the keyspace!
Total key length in bytes is 150000 (avg len 15.00)
Biggest string found 'bigkey1' has 512000 bytes
Biggest list found 'mylist' has 10000 items
Biggest hash found 'user:hash' has 5000 fields
Biggest set found 'myset' has 3000 members
Biggest zset found 'myzset' has 2000 members
10000 strings with 2048000 bytes (50.00% of keys, avg size 204.80)
5000 lists with 50000 items (25.00% of keys, avg size 10.00)
3000 hashs with 15000 fields (15.00% of keys, avg size 5.00)
1500 sets with 7500 members (7.50% of keys, avg size 5.00)
500 zsets with 2500 members (2.50% of keys, avg size 5.00)②scan 扫描
自己编程,利用 scan 扫描 Redis 中的所有 key,利用 strlen、hlen 等命令判断 key 的长度(此处不建议使用 MEMORY USAGE)
# scan命令基本用法
SCAN cursor [MATCH pattern] [COUNT count]
# 示例:
127.0.0.1:6379> scan 0
1) "17"
2) 1) "key1"
2) "key2"
3) "key3"
127.0.0.1:6379> scan 17
1) "0"
2) 1) "key4"
2) "key5"scan 命令调用完后每次会返回 2 个元素,第一个是下一次迭代的光标,第一次光标会设置为 0,当最后一次 scan 返回的光标等于 0 时,表示整个 scan 遍历结束了,第二个返回的是 List,一个匹配的 key 的数组
package main
import (
"fmt"
"github.com/go-redis/redis/v8"
"context"
)
var ctx = context.Background()
const (
STR_MAX_LEN = 10 * 1024
HASH_MAX_LEN = 500
)
func main() {
// 建立连接
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "123321",
DB: 0,
})
// 测试连接
_, err := rdb.Ping(ctx).Result()
if err != nil {
panic(err)
}
// scan扫描
var cursor uint64
for {
var keys []string
keys, cursor, err = rdb.Scan(ctx, cursor, "*", 10).Result()
if err != nil {
panic(err)
}
if len(keys) == 0 {
break
}
// 遍历keys
for _, key := range keys {
// 判断key的类型
keyType, _ := rdb.Type(ctx, key).Result()
var length int64
var maxLen int64
switch keyType {
case "string":
length, _ = rdb.StrLen(ctx, key).Result()
maxLen = STR_MAX_LEN
case "hash":
length, _ = rdb.HLen(ctx, key).Result()
maxLen = HASH_MAX_LEN
case "list":
length, _ = rdb.LLen(ctx, key).Result()
maxLen = HASH_MAX_LEN
case "set":
length, _ = rdb.SCard(ctx, key).Result()
maxLen = HASH_MAX_LEN
case "zset":
length, _ = rdb.ZCard(ctx, key).Result()
maxLen = HASH_MAX_LEN
}
if length >= maxLen {
fmt.Printf("Found big key : %s, type: %s, length or size: %d\n",
key, keyType, length)
}
}
// 如果cursor为0,说明遍历结束
if cursor == 0 {
break
}
}
}③第三方工具
- 利用第三方工具,如 Redis-Rdb-Tools 分析 RDB 快照文件,全面分析内存使用情况

④网络监控
- 自定义工具,监控进出 Redis 的网络数据,超出预警值时主动告警
- 一般阿里云搭建的云服务器就有相关监控页面
阿里云Redis监控面板示例:
┌─────────────────────────────────────────┐
│ 实例ID: r-xxxxxxxxx │
│ 内存使用率: 85.2% [警告] │
│ 连接数: 150/10000 │
│ QPS: 12000 │
│ 网络入流量: 15.6 MB/s │
│ 网络出流量: 42.3 MB/s │
└─────────────────────────────────────────┘1.2.3、如何删除 BigKey
BigKey 内存占用较多,即便时删除这样的 key 也需要耗费很长时间,导致 Redis 主线程阻塞,引发一系列问题。
- redis 3.0 及以下版本
- 如果是集合类型,则遍历 BigKey 的元素,先逐个删除子元素,最后删除 BigKey
# 对于Hash类型BigKey
HSCAN key 0
HDEL key field1 field2 ...
# 重复执行直到所有field删除完毕
DEL key
# 对于Set类型BigKey
SSCAN key 0
SREM key member1 member2 ...
# 重复执行直到所有member删除完毕
DEL key
# 对于List类型BigKey
LPOP key (循环执行)
或
RPOP key (循环执行)
# 直到列表为空
# 对于ZSet类型BigKey
ZSCAN key 0
ZREM key member1 member2 ...
# 重复执行直到所有member删除完毕
DEL key- Redis 4.0 以后
- Redis 在 4.0 后提供了异步删除的命令:unlink
# 异步删除,不阻塞主线程
UNLINK bigkey
# 查看是否删除成功
EXISTS bigkey1.3、恰当的数据类型
例 1:比如存储一个 User 对象,我们有三种存储方式
①方式一:json 字符串
| user:1 | {“name”: “Jack”, “age”: 21} |
|---|---|
| 优点:实现简单粗暴 | |
| 缺点:数据耦合,不够灵活 |
②方式二:字段打散
| user:1:name | Jack |
|---|---|
| user:1:age | 21 |
| 优点:可以灵活访问对象任意字段 | |
| 缺点:占用空间大、没办法做统一控制 |
③方式三:hash(推荐)
| user:1 | name | jack |
| age | 21 |
| key | field | value |
| someKey | id:0 | value0 |
| ..... | ..... | |
| id:999999 | value999999 |
| key | value |
| id:0 | value0 |
| ..... | ..... |
| id:999999 | value999999 |
| key | field | value |
| key:0 | id:00 | value0 |
| ..... | ..... | |
| id:99 | value99 | |
| key:1 | id:00 | value100 |
| ..... | ..... | |
| id:99 | value199 | |
| .... | ||
| key:9999 | id:00 | value999900 |
| ..... | ..... | |
| id:99 | value999999 | |
//plainplainplainplainplain 测试大Hash
testBigHash(rdb)
// 测试大String
testBigString(rdb)
// 测试小Hash
testSmallHash(rdb)} func testSetBigKey(rdb *redis.Client) { data := make(map[string]interface{}) for i := 1; i <= 650; i++ { data[fmt.Sprintf(“hello_%d”, i)] = “world!” } err := rdb.HMSet(ctx, “m2”, data).Err() if err != nil { panic(err) } fmt.Println(“Set big hash key successfully”) } func testBigHash(rdb *redis.Client) { data := make(map[string]interface{}) for i := 1; i <= 100000; i++ { data[fmt.Sprintf(“key_%d”, i)] = fmt.Sprintf(“value_%d”, i) } err := rdb.HMSet(ctx, “test:big:hash”, data).Err() if err != nil { panic(err) } fmt.Println(“Created big hash with 100000 entries”) } func testBigString(rdb *redis.Client) { for i := 1; i <= 100000; i++ { err := rdb.Set(ctx, fmt.Sprintf(“test:str:key_%d”, i), fmt.Sprintf(“value_%d”, i), 0).Err() if err != nil { panic(err) } } fmt.Println(“Created 100000 string keys”) } func testSmallHash(rdb *redis.Client) { hashSize := 100 data := make(map[string]interface{})
foplainplainplainplainplainr i := 1; i <= 100000; i++ {
k := (i - 1) / hashSize
v := i % hashSize
data[fmt.Sprintf("key_%d", v)] = fmt.Sprintf("value_%d", v)
// 每100条写入一个Hash
if v == 0 {
err := rdb.HMSet(ctx, fmt.Sprintf("test:small:hash_%d", k), data).Err()
if err != nil {
panic(err)
}
// 清空data,准备下一批
data = make(map[string]interface{})
}
}
fmt.Println("Created 1000 small hashes with 100 entries each")}
### 1.4、总结
- Key的最佳实践
- 固定格式:[业务名]:[数据名]:[id]
- 足够简短:不超过44字节
- 不包含特殊字符
- Value的最佳实践:
- 合理的拆分数据,拒绝BigKey
- 选择合适数据结构
- Hash结构的entry数量不要超过1000
- 设置合理的超时时间
## 2、批处理优化
### 2.1、Pipeline
#### 2.1.1、我们的客户端与redis服务器是这样交互的
单个命令的执行流程客户端 Redis 服务器 | | |----发送命令--------->| | |---执行命令 |<---返回结果----------| | |
时间消耗:网络往返时间 + 命令执行时间
N条命令的执行流程客户端 Redis 服务器 | | |----命令 1------------>| |<---结果 1-------------| |----命令 2------------>| |<---结果 2-------------| |----命令 3------------>| |<---结果 3-------------| | … |
时间消耗:N * (网络往返时间 + 命令执行时间)
redis处理指令是很快的,主要花费的时候在于网络传输。于是乎很容易想到将多条指令批量的传输给redis客户端 Redis 服务器 | | |----命令 1------------>| |----命令 2------------>| |----命令 3------------>| | … | | |---批量执行 |<---结果 1-------------| |<---结果 2-------------| |<---结果 3-------------| | … |
时间消耗:1 次网络往返时间 + N * 命令执行时间
#### 2.1.2、MSet
Redis提供了很多Mxxx这样的命令,可以实现批量插入数据,例如:
- mset
- hmset
利用mset批量插入10万条数据
```go
package main
import (
"fmt"
"time"
"github.com/go-redis/redis/v8"
"context"
)
var ctx = context.Background()
func main() {
// 建立连接
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "123321",
DB: 0,
})
// 测试MSET
start := time.Now()
for i := 1; i <= 100000; i++ {
// 每1000条执行一次mset
if i%1000 == 0 {
// 构建key-value对
kv := make([]interface{}, 0, 2000)
for j := i - 999; j <= i; j++ {
kv = append(kv, fmt.Sprintf("test:key_%d", j))
kv = append(kv, fmt.Sprintf("value_%d", j))
}
// 执行mset
err := rdb.MSet(ctx, kv...).Err()
if err != nil {
panic(err)
}
}
}
elapsed := time.Since(start)
fmt.Printf("MSET time: %v\n", elapsed)
}2.1.3、Pipeline
MSET 虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用 Pipeline
package main
import (
"fmt"
"time"
"github.com/go-redis/redis/v8"
"context"
)
var ctx = context.Background()
func main() {
// 建立连接
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "123321",
DB: 0,
})
// 测试Pipeline
start := time.Now()
// 创建管道
pipe := rdb.Pipeline()
for i := 1; i <= 100000; i++ {
// 添加命令到管道
pipe.Set(ctx, fmt.Sprintf("test:key_%d", i),
fmt.Sprintf("value_%d", i), 0)
// 每1000条执行一次
if i%1000 == 0 {
// 执行管道中的命令
_, err := pipe.Exec(ctx)
if err != nil {
panic(err)
}
}
}
elapsed := time.Since(start)
fmt.Printf("Pipeline time: %v\n", elapsed)
}2.2、集群下的批处理
如 MSET 或 Pipeline 这样的批处理需要在一次请求中携带多条命令,而此时如果 Redis 是一个集群,那批处理命令的多个 key 必须落在一个插槽中,否则就会导致执行失败。大家可以想一想这样的要求其实很难实现,因为我们在批处理时,可能一次要插入很多条数据,这些数据很有可能不会都落在相同的节点上,这就会导致报错了 这个时候,我们可以找到 4 种解决方案
┌─────────────────────────────────────────────────────────┐
│ 集群批处理解决方案对比 │
├────────────┬──────────────┬──────────────┬─────────────┤
│ 方案 │ 耗时 │ 复杂度 │ 问题 │
├────────────┼──────────────┼──────────────┼─────────────┤
│1.串行执行 │ 很长 │ 简单 │性能差 │
├────────────┼──────────────┼──────────────┼─────────────┤
│2.串行slot │ 较短 │ 较复杂 │实现复杂 │
├────────────┼──────────────┼──────────────┼─────────────┤
│3.并行slot │ 最短 │ 复杂 │实现最复杂 │
├────────────┼──────────────┼──────────────┼─────────────┤
│4.hash_tag │ 最短 │ 简单 │数据倾斜 │
└────────────┴──────────────┴──────────────┴─────────────┘第一种方案:串行执行,所以这种方式没有什么意义,当然,执行起来就很简单了,缺点就是耗时过久。 第二种方案:串行 slot,简单来说,就是执行前,客户端先计算一下对应的 key 的 slot,一样 slot 的 key 就放到一个组里边,不同的,就放到不同的组里边,然后对每个组执行 pipeline 的批处理,他就能串行执行各个组的命令,这种做法比第一种方法耗时要少,但是缺点呢,相对来说复杂一点,所以这种方案还需要优化一下 第三种方案:并行 slot,相较于第二种方案,在分组完成后串行执行,第三种方案,就变成了并行执行各个命令,所以他的耗时就非常短,但是实现呢,也更加复杂。 第四种:hash_tag,redis 计算 key 的 slot 的时候,其实是根据 key 的有效部分来计算的,通过这种方式就能一次处理所有的 key,这种方式耗时最短,实现也简单,但是如果通过操作 key 的有效部分,那么就会导致所有的 key 都落在一个节点上,产生数据倾斜的问题,所以我们推荐使用第三种方式。 这是将提供的 Java/Spring 笔记改写为 Go 语言版本的笔记。
2.2.1 串行化执行代码实践
在 Go 语言中,最常用的 Redis 客户端库是 go-redis。与 Java 的 Spring Data Redis 不同,go-redis 在设计上更加底层和直观,它对集群模式下的批处理有内置的支持,但实现原理与 Spring 类似(基于 Slot 分组)。
在 Go 中使用 go-redis 库连接 Redis 集群。go-redis 的 NewClusterClient 会自动处理连接池管理,无需像 Jedis 那样手动配置 PoolConfig。
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
// 初始化集群客户端
func NewClusterClient() *redis.ClusterClient {
return redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{
"192.168.150.101:7001",
"192.168.150.101:7002",
"192.168.150.101:7003",
"192.168.150.101:8001",
"192.168.150.101:8002",
"192.168.150.101:8003",
},
// 连接池配置对应关系
PoolSize: 8, // 对应 MaxTotal
MinIdleConns: 0, // 对应 MinIdle
})
}
// 模拟 Jedis 的普通 MSet
// 注意:在集群模式下,如果 key 分布在不同 slot,直接调用 MSet 可能会报错 CROSSSLOT,
// 除非 Redis 版本较高且支持无哈希标签的 MSet,或者客户端做了特殊处理。
func TestMSet(client *redis.ClusterClient) {
ctx := context.Background()
// go-redis 的 MSet 接收 interface{} 切片
err := client.MSet(ctx, "name", "Jack", "age", "21", "sex", "male").Err()
if err != nil {
fmt.Println("MSet Error:", err)
}
}
// 模拟手动分组串行执行 MSet
func TestMSetManual(client *redis.ClusterClient) {
ctx := context.Background()
mapData := map[string]string{
"name": "Jack",
"age": "21",
"sex": "Male",
}
// 1. 根据 Slot 对数据进行分组
// key 是 slot,value 是属于该 slot 的键值对集合
slotMap := make(map[int][]interface{})
for key, value := range mapData {
// go-redis 提供了计算 slot 的方法
slot := redis.Slot(key)
// 将 key-value 交替存入切片,为后续 MSet 做准备
slotMap[slot] = append(slotMap[slot], key, value)
}
// 2. 串行执行 MSet 逻辑
for _, kvPairs := range slotMap {
// 每一组 kvPairs 都是同一个 slot 的数据,可以直接发送
err := client.MSet(ctx, kvPairs...).Err()
if err != nil {
fmt.Println("Manual MSet Error:", err)
}
}
}2.2.2 go-redis 集群环境下批处理代码
在 go-redis 中,并不像 Spring 那样提供一个自动处理 Cross-Slot 问题的 multiSet 方法(即 stringRedisTemplate.opsForValue().multiSet)。go-redis 的设计哲学是让开发者明确知道开销。
如果在集群环境下直接对不同 Slot 的 Key 调用 MSet,通常会导致错误。因此,go-redis 推荐使用 TxPipeline 或 Pipeline 来实现类似“批处理”的效果,这在网络 IO 开销上比串行 MSet 更优。
func TestMSetInCluster(client *redis.ClusterClient) {
ctx := context.Background()
mapData := map[string]string{
"name": "Rose",
"age": "21",
"sex": "Female",
}
// go-redis 集群客户端不支持直接对不同 slot 的 key 进行 MSet
// 标准做法是使用 Pipeline 批量发送命令
// Pipeline 会将命令打包发送,减少网络往返,但各命令独立执行
pipe := client.Pipeline()
for key, val := range mapData {
pipe.Set(ctx, key, val, 0) // 这里相当于批量发送多个 Set 命令
}
// 执行 Pipeline
cmders, err := pipe.Exec(ctx)
if err != nil {
fmt.Println("Pipeline Exec Error:", err)
return
}
fmt.Println("Pipeline executed, commands count:", len(cmders))
// 批量获取
keys := []string{"name", "age", "sex"}
// MGet 在集群模式下同样有 Cross-Slot 限制,
// go-redis 会尝试解析重定向,或者也可以用 Pipeline 批量 Get
pipeGet := client.Pipeline()
for _, k := range keys {
pipeGet.Get(ctx, k)
}
cmders, _ = pipeGet.Exec(ctx)
for _, cmd := range cmders {
val, _ := cmd.(*redis.StringCmd).Result()
fmt.Println(val)
}
}注意: 从 go-redis v9 开始,为了完全解决 Cross-Slot 问题,开发者通常采用 Hash Tag(如 {user}:name, {user}:age)确保相关 Key 落在同一个 Slot,这样就可以直接使用高效的 MSet/MGet 了。
原理分析
go-redis 的 ClusterClient 在执行命令时,其核心逻辑与 Spring 的 RedisAdvancedClusterAsyncCommandsImpl 类似。
在 ClusterClient.processTxPipeline 或相关内部路由逻辑中:
- 路由计算:客户端首先计算出 Key 所属的 Slot。
- 分组映射:根据 Slot 找到对应的 Redis 节点连接。
- 命令分发:
- 如果使用
Pipeline,go-redis会将命令按照节点进行分组,然后并行(或串行,取决于配置)地将打包好的命令发送到各个节点。 - 这与 Spring 中
partitionedMap 的逻辑一致:将大的 Map 拆分成多个小的 Map,分别发送给持有对应 Slot 的节点。
- 如果使用
以下伪代码展示了 go-redis 内部处理批处理的核心逻辑(简化版):
// 类似于 Spring 的 partitioned 逻辑
//cmds 是待执行的命令集合
func (c *ClusterClient) processPipeline(ctx context.Context, cmds []Cmder) error {
// 1. 根据 Slot 对命令进行分组
slotCmds := map[int][]Cmder{} // 实际上是根据 Node 地址分组
for _, cmd := range cmds {
slot := cmd.slot() // 内部方法获取 slot
// 获取该 slot 对应的节点连接
node, _ := c.slotMasterNode(slot)
// 将命令加入对应节点的待发送队列
slotCmds[node.ID] = append(slotCmds[node.ID], cmd)
}
// 2. 对每个节点并发执行 Pipeline
// 使用 sync.WaitGroup 等待所有节点响应
for nodeID, nodeCmds := range slotCmds {
go func(node *redis.Node, cmds []Cmder) {
// 发送 Pipeline 包到具体的 TCP 连接
conn := node.Conn()
conn.Send("MULTI") // 如果是 TxPipeline
for _, cmd := range cmds {
conn.Send(cmd.Args()...)
}
conn.Send("EXEC")
conn.Flush()
// 读取结果...
}(c.nodes[nodeID], nodeCmds)
}
// 3. 汇总结果
return nil
}总结区别:
- Spring Data Redis 的
multiSet对用户屏蔽了集群分片的细节,内部自动分组并执行(可能存在多次网络往返)。 - go-redis 更倾向于让开发者显式处理。它不提供“自动分组的 MSet”,而是推荐使用
Pipeline来达到批处理的效果(一次网络往返,多条命令),或者使用 Hash Tag 从设计上规避跨 Slot 问题。
3、服务器端优化-持久化配置
Redis 的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- 用来做缓存的 Redis 实例尽量不要开启持久化功能
- 建议关闭 RDB 持久化功能,使用 AOF 持久化
- 利用脚本定期在 slave 节点做 RDB,实现数据备份
- 设置合理的 rewrite 阈值,避免频繁的 bgrewrite
- 配置 no-appendfsync-on-rewrite = yes,禁止在 rewrite 期间执行 AOF 的 fsync 刷盘,避免因 AOF 引起的阻塞
- 部署有关建议:
- Redis 实例的物理机要预留足够内存,应对 fork 和 rewrite
- 单个 Redis 实例内存上限不要太大,例如 4G 或 8G。可以加快 fork 的速度、减少主从同步、数据迁移压力
- 不要与 CPU 密集型应用部署在一起
- 不要与高硬盘负载应用一起部署。例如:数据库、消息队列
4、服务器端优化-慢查询优化
4.1 什么是慢查询
并不是很慢的查询才是慢查询,而是:在 Redis 执行时耗时超过某个阈值的命令,称为慢查询。 慢查询的危害:由于 Redis 是单线程的,所以当客户端发出指令后,他们都会进入到 redis 底层的 queue 来执行,如果此时有一些慢查询的数据,就会导致大量请求阻塞,从而引起报错,所以我们需要解决慢查询问题。
Redis命令执行队列:
┌─────────────────────────────────┐
│ 客户端请求队列 (Queue) │
├─────────────────────────────────┤
│ cmd1 → cmd2 → cmd3 → ... │
│ ↓ │
│ [慢查询阻塞] │
│ ↓ │
│ 后续命令等待... │
└─────────────────────────────────┘慢查询的阈值可以通过配置指定: slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是 10000,建议 1000 慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定: slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是 128,建议 1000
慢查询日志结构:
┌────────────────────────────┐
│ Slow Log (FIFO Queue) │
├────────────────────────────┤
│ Entry 1 (oldest) │
│ Entry 2 │
│ Entry 3 │
│ ... │
│ Entry N (newest) │
└────────────────────────────┘
↑
当超过max-len时,移除最旧的条目修改这两个配置可以使用:config set 命令:
# 设置慢查询阈值为1000微秒(1毫秒)
127.0.0.1:6379> CONFIG SET slowlog-log-slower-than 1000
OK
# 设置慢查询日志长度为1000
127.0.0.1:6379> CONFIG SET slowlog-max-len 1000
OK4.2 如何查看慢查询
知道了以上内容之后,那么咱们如何去查看慢查询日志列表呢:
- slowlog len:查询慢查询日志长度
- slowlog get [n]:读取 n 条慢查询日志
- slowlog reset:清空慢查询列表
# 查看慢查询日志长度
127.0.0.1:6379> SLOWLOG LEN
(integer) 5
# 获取最近3条慢查询日志
127.0.0.1:6379> SLOWLOG GET 3
1) 1) (integer) 4 # 日志ID
2) (integer) 1623456789 # 时间戳
3) (integer) 5000 # 执行时长(微秒)
4) 1) "KEYS" # 命令
2) "user:*"
5) "127.0.0.1:54321" # 客户端地址
6) "client-1" # 客户端名称
2) 1) (integer) 3
2) (integer) 1623456788
3) (integer) 3500
4) 1) "HGETALL"
2) "big:hash:key"
5) "127.0.0.1:54322"
6) "client-2"
3) 1) (integer) 2
2) (integer) 1623456787
3) (integer) 2000
4) 1) "SMEMBERS"
2) "large:set"
5) "127.0.0.1:54323"
6) "client-3"
# 清空慢查询日志
127.0.0.1:6379> SLOWLOG RESET
OK5、服务器端优化-命令及安全配置
安全可以说是服务器端一个非常重要的话题,如果安全出现了问题,那么一旦这个漏洞被一些坏人知道了之后,并且进行攻击,那么这就会给咱们的系统带来很多的损失,所以我们这节课就来解决这个问题。 Redis 会绑定在 0.0.0.0:6379,这样将会将 Redis 服务暴露到公网上,而 Redis 如果没有做身份认证,会出现严重的安全漏洞. 漏洞重现方式:https://cloud.tencent.com/developer/article/1039000 为什么会出现不需要密码也能够登录呢,主要是 Redis 考虑到每次登录都比较麻烦,所以 Redis 就有一种 ssh 免秘钥登录的方式,生成一对公钥和私钥,私钥放在本地,公钥放在 redis 端,当我们登录时服务器,再登录时候,他会去解析公钥和私钥,如果没有问题,则不需要利用 redis 的登录也能访问,这种做法本身也很常见,但是这里有一个前提,前提就是公钥必须保存在服务器上,才行,但是 Redis 的漏洞在于在不登录的情况下,也能把秘钥送到 Linux 服务器,从而产生漏洞 漏洞出现的核心的原因有以下几点:
- Redis 未设置密码
- 利用了 Redis 的 config set 命令动态修改 Redis 配置
- 使用了 Root 账号权限启动 Redis 所以:如何解决呢?我们可以采用如下几种方案 为了避免这样的漏洞,这里给出一些建议:
- Redis 一定要设置密码
- 禁止线上使用下面命令:keys、flushall、flushdb、config set 等命令。可以利用 rename-command 禁用。
- bind:限制网卡,禁止外网网卡访问
- 开启防火墙
- 不要使用 Root 账户启动 Redis
- 尽量不是有默认的端口
# redis.conf 安全配置示例
# 1. 设置密码
requirepass your_strong_password_here
# 2. 禁用危险命令
rename-command KEYS ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
# 3. 限制访问IP
bind 127.0.0.1 192.168.1.100
# 4. 修改默认端口
port 6380
# 5. 禁用保护模式(慎用)
protected-mode yes6、服务器端优化-Redis 内存划分和内存配置
当 Redis 内存不足时,可能导致 Key 频繁被删除、响应时间变长、QPS 不稳定等问题。当内存使用率达到 90%以上时就需要我们警惕,并快速定位到内存占用的原因。 有关碎片问题分析 Redis 底层分配并不是这个 key 有多大,他就会分配多大,而是有他自己的分配策略,比如 8,16,20 等等,假定当前 key 只需要 10 个字节,此时分配 8 肯定不够,那么他就会分配 16 个字节,多出来的 6 个字节就不能被使用,这就是我们常说的 碎片问题 进程内存问题分析: 这片内存,通常我们都可以忽略不计 缓冲区内存问题分析: 一般包括客户端缓冲区、AOF 缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,所以这片内存也是我们需要重点分析的内存问题。
| 内存占用 | 说明 |
|---|---|
| 数据内存 | 是 Redis 最主要的部分,存储 Redis 的键值信息。主要问题是 BigKey 问题、内存碎片问题 |
| 进程内存 | Redis 主进程本身运⾏肯定需要占⽤内存,如代码、常量池等等;这部分内存⼤约⼏兆,在⼤多数⽣产环境中与 Redis 数据占⽤的内存相⽐可以忽略。 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF 缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用 BigKey,可能导致内存溢出。 |
| 于是我们就需要通过一些命令,可以查看到 Redis 目前的内存分配状态: |
- info memory:查看内存分配的情况
127.0.0.1:6379> INFO MEMORY
# Memory
used_memory:1024000 # Redis分配的内存总量
used_memory_human:1.00M
used_memory_rss:2048000 # 操作系统分配给Redis的内存
used_memory_rss_human:2.00M
used_memory_peak:1536000 # Redis内存使用的峰值
used_memory_peak_human:1.46M
used_memory_lua:37888 # Lua引擎使用的内存
mem_fragmentation_ratio:2.00 # 内存碎片率
mem_allocator:jemalloc-4.0.3 # 内存分配器- memory xxx:查看 key 的主要占用情况
# 查看指定key的内存占用
127.0.0.1:6379> MEMORY USAGE user:1001
(integer) 128
# 查看内存详情
127.0.0.1:6379> MEMORY STATS
1) peak.allocated
2) (integer) 1536000
3) total.allocated
4) (integer) 1024000
5) fragmentation.ratio
6) (double) 2.0
...接下来我们看到了这些配置,最关键的缓存区内存如何定位和解决呢? 内存缓冲区常见的有三种:
- 复制缓冲区:主从复制的 repl_backlog_buf,如果太小可能导致频繁的全量复制,影响性能。通过 replbacklog-size 来设置,默认 1mb
- AOF 缓冲区:AOF 刷盘之前的缓存区域,AOF 执行 rewrite 的缓冲区。无法设置容量上限
- 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大 1G 且不能设置。输出缓冲区可以设置 以上复制缓冲区和 AOF 缓冲区 不会有问题,最关键就是客户端缓冲区的问题 客户端缓冲区:指的就是我们发送命令时,客户端用来缓存命令的一个缓冲区,也就是我们向 redis 输入数据的输入端缓冲区和 redis 向客户端返回数据的响应缓存区,输入缓冲区最大 1G 且不能设置,所以这一块我们根本不用担心,如果超过了这个空间,redis 会直接断开,因为本来此时此刻就代表着 redis 处理不过来了,我们需要担心的就是输出端缓冲区
客户端缓冲区结构:
┌──────────────────────────────────┐
│ Redis服务器 │
├──────────────────────────────────┤
│ │
│ ┌────────────────────────────┐ │
│ │ 输入缓冲区 (Input) │ │
│ │ 最大1G,不可配置 │ │
│ └────────────────────────────┘ │
│ │
│ ┌────────────────────────────┐ │
│ │ 输出缓冲区 │ │
│ │ 可配置大小限制 │ │
│ └────────────────────────────┘ │
│ │
└──────────────────────────────────┘我们在使用 redis 过程中,处理大量的 big value,那么会导致我们的输出结果过多,如果输出缓存区过大,会导致 redis 直接断开,而默认配置的情况下, 其实他是没有大小的,这就比较坑了,内存可能一下子被占满,会直接导致咱们的 redis 断开,所以解决方案有两个 1、设置一个大小
# redis.conf 配置输出缓冲区限制
# client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
# 普通客户端
client-output-buffer-limit normal 0 0 0
# 从节点客户端
client-output-buffer-limit replica 256mb 64mb 60
# 发布订阅客户端
client-output-buffer-limit pubsub 32mb 8mb 602、增加我们带宽的大小,避免我们出现大量数据从而直接超过了 redis 的承受能力
7、服务器端集群优化-集群还是主从
集群虽然具备高可用特性,能实现自动故障恢复,但是如果使用不当,也会存在一些问题:
- 集群完整性问题
- 集群带宽问题
- 数据倾斜问题
- 客户端性能问题
- 命令的集群兼容性问题
- lua 和事务问题
问题 1、在 Redis 的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务: 大家可以设想一下,如果有几个 slot 不能使用,那么此时整个集群都不能用了,我们在开发中,其实最重要的是可用性,所以需要把如下配置修改成 no,即有 slot 不能使用时,我们的 redis 集群还是可以对外提供服务
# redis.conf
cluster-require-full-coverage no问题 2、集群带宽问题 集群节点之间会不断的互相 Ping 来确定集群中其它节点的状态。每次 Ping 携带的信息至少包括:
- 插槽信息
- 集群状态信息 集群中节点越多,集群状态信息数据量也越大,10 个节点的相关信息可能达到 1kb,此时每次集群互通需要的带宽会非常高,这样会导致集群中大量的带宽都会被 ping 信息所占用,这是一个非常可怕的问题,所以我们需要去解决这样的问题 解决途径:
- 避免大集群,集群节点数不要太多,最好少于 1000,如果业务庞大,则建立多个集群。
- 避免在单个物理机中运行太多 Redis 实例
- 配置合适的 cluster-node-timeout 值
# redis.conf
cluster-node-timeout 15000 # 默认15秒问题 3、命令的集群兼容性问题 有关这个问题咱们已经探讨过了,当我们使用批处理的命令时,redis 要求我们的 key 必须落在相同的 slot 上,然后大量的 key 同时操作时,是无法完成的,所以客户端必须要对这样的数据进行处理,这些方案我们之前已经探讨过了,所以不再这个地方赘述了。
问题 4、lua 和事务的问题 lua 和事务都是要保证原子性问题,如果你的 key 不在一个节点,那么是无法保证 lua 的执行和事务的特性的,所以在集群模式是没有办法执行 lua 和事务的
集群环境下lua和事务的限制:
事务示例:
┌────────────────────────────────┐
│ MULTI │
│ SET key1 value1 (slot 1234) │ ← 节点A
│ SET key2 value2 (slot 5678) │ ← 节点B
│ EXEC │
└────────────────────────────────┘
↓
执行失败!key分布在不同的节点
解决方案:使用hash tag
┌────────────────────────────────┐
│ MULTI │
│ SET {user}1 value1 (slot固定) │
│ SET {user}2 value2 (slot固定) │
│ EXEC │
└────────────────────────────────┘
↓
成功!通过{user}保证在同一slot那我们到底是集群还是主从 单体 Redis(主从 Redis)已经能达到万级别的 QPS,并且也具备很强的高可用特性。如果主从能满足业务需求的情况下,所以如果不是在万不得已的情况下,尽量不搭建 Redis 集群
Redis架构选择决策树:
QPS需求?
├─ < 10000 QPS
│ └─ 单机Redis(主从模式即可)
│ ├─ 成本低
│ ├─ 运维简单
│ └─ 高可用(Sentinel)
│
└─ > 10000 QPS
└─ Redis集群
├─ 数据分片
├─ 横向扩展
├─ 运维复杂
└─ 注意限制(批处理、事务、lua)Redis 原理篇
1、原理篇-Redis 数据结构
1.1 Redis 数据结构-动态字符串
我们都知道 Redis 中保存的 Key 是字符串,value 往往是字符串或者字符串的集合。可见字符串是 Redis 中最常用的一种数据结构。
不过 Redis 没有直接使用 C 语言中的字符串,因为 C 语言字符串存在很多问题: 获取字符串长度的需要通过运算 非二进制安全 不可修改 Redis 构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称 SDS。 例如,我们执行命令:

那么 Redis 将在底层创建两个 SDS,其中一个是包含“name”的 SDS,另一个是包含“虎哥”的 SDS。
Redis 是 C 语言实现的,其中 SDS 是一个结构体,源码如下:

例如,一个包含字符串“name”的 sds 结构如下:

SDS 之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为“hi”的 SDS:

假如我们要给 SDS 追加一段字符串“,Amy”,这里首先会申请新内存空间:
如果新字符串小于 1M,则新空间为扩展后字符串长度的两倍+1;
如果新字符串大于 1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配。


1.2 Redis 数据结构-intset
IntSet 是 Redis 中 set 集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。 结构如下:

其中的 encoding 包含三种模式,表示存储的整数大小不同:

为了方便查找,Redis 会将 intset 中所有的整数按照升序依次保存在 contents 数组中,结构如图:
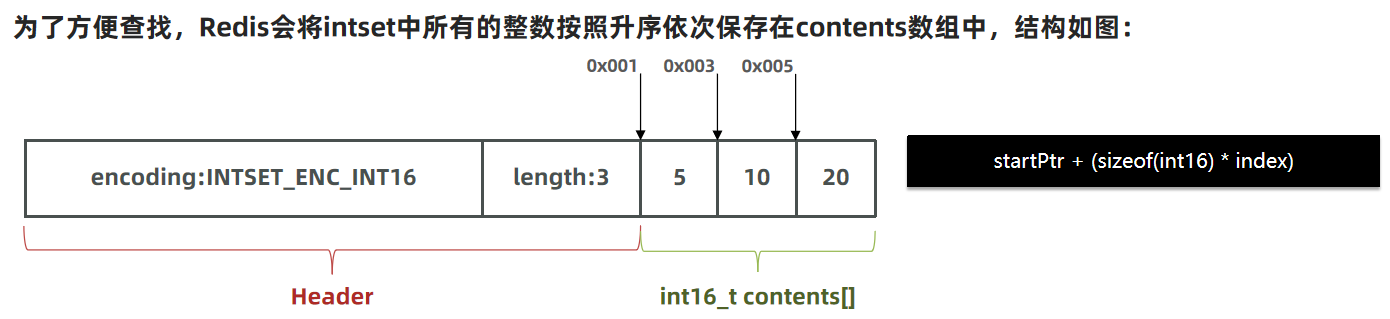
现在,数组中每个数字都在 int16_t 的范围内,因此采用的编码方式是 INTSET_ENC_INT16,每部分占用的字节大小为: encoding:4 字节 length:4 字节 contents:2 字节 * 3 = 6 字节

我们向该其中添加一个数字:50000,这个数字超出了 int16_t 的范围,intset 会自动升级编码方式到合适的大小。 以当前案例来说流程如下:
- 升级编码为 INTSET_ENC_INT32, 每个整数占 4 字节,并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将待添加的元素放入数组末尾
- 最后,将 inset 的 encoding 属性改为 INTSET_ENC_INT32,将 length 属性改为 4

源码如下:

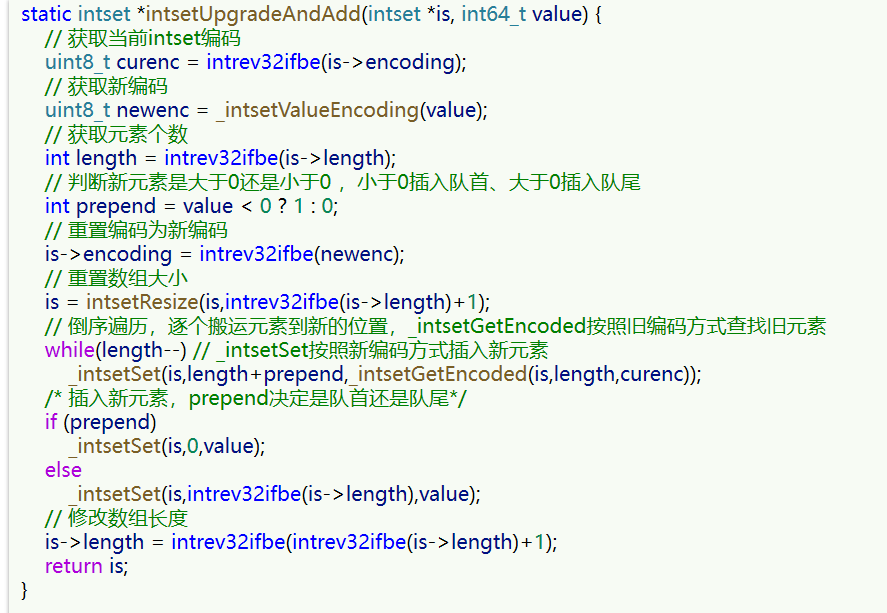
小总结:
Intset 可以看做是特殊的整数数组,具备一些特点:
- Redis 会确保 Intset 中的元素唯一、有序
- 具备类型升级机制,可以节省内存空间
- 底层采用二分查找方式来查询
1.3 Redis 数据结构-Dict
我们知道 Redis 是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过 Dict 来实现的。 Dict 由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)

当我们向 Dict 添加键值对时,Redis 首先根据 key 计算出 hash 值(h),然后利用 h & sizemask 来计算元素应该存储到数组中的哪个索引位置。我们存储 k1=v1,假设 k1 的哈希值 h =1,则 1&3 =1,因此 k1=v1 要存储到数组角标 1 位置。

Dict 由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
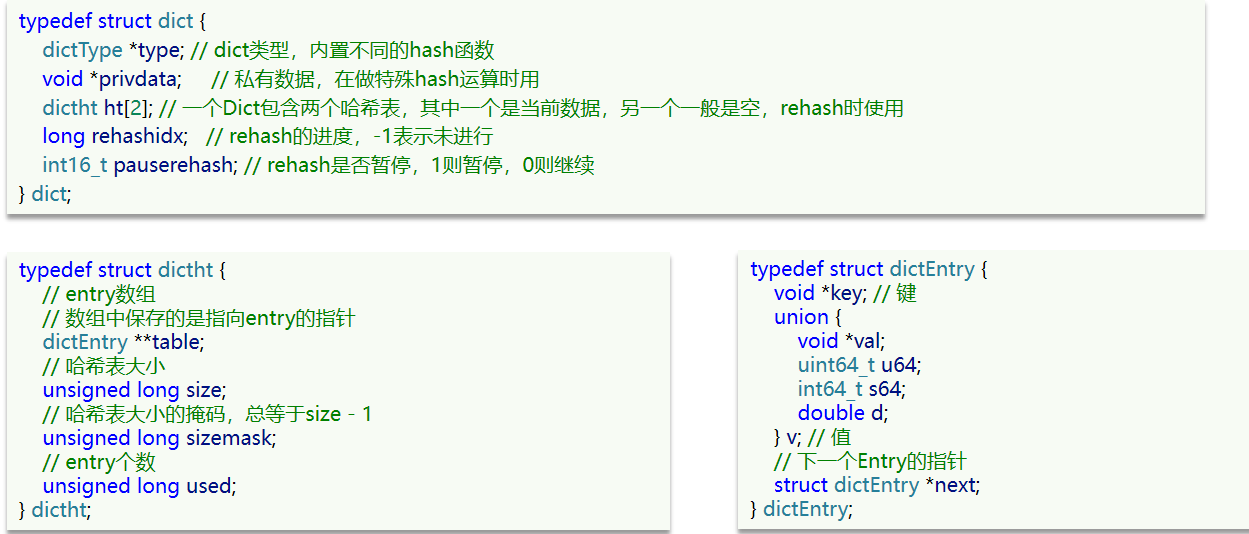

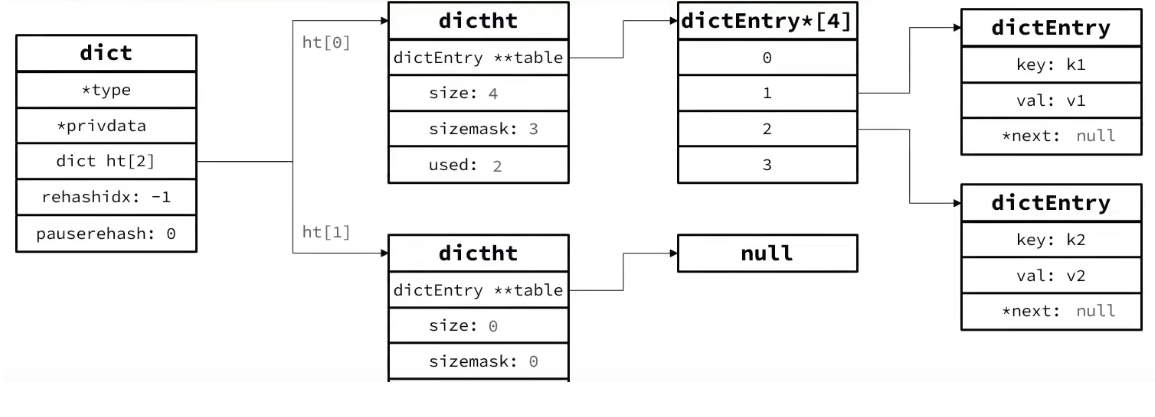
Dict 的扩容
Dict 中的 HashTable 就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。 Dict 在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容: 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程; 哈希表的 LoadFactor > 5 ;

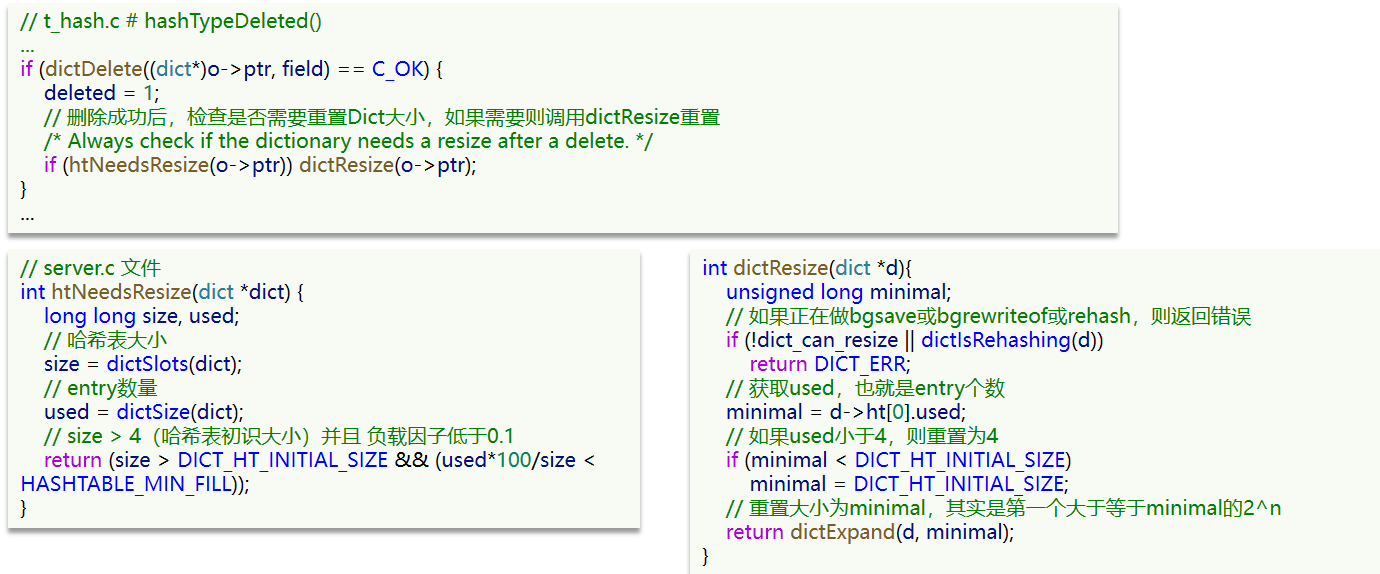
Dict 的 rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的 size 和 sizemask 变化,而 key 的查询与 sizemask 有关。因此必须对哈希表中的每一个 key 重新计算索引,插入新的哈希表,这个过程称为 rehash。过程是这样的:
-
计算新 hash 表的 realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新 size 为第一个大于等于 dict.ht[0].used + 1 的 2^n
- 如果是收缩,则新 size 为第一个大于等于 dict.ht[0].used 的 2^n (不得小于 4)
-
按照新的 realeSize 申请内存空间,创建 dictht,并赋值给 dict.ht[1]
-
设置 dict.rehashidx = 0,标示开始 rehash
-
将 dict.ht[0]中的每一个 dictEntry 都 rehash 到 dict.ht[1]
-
将 dict.ht[1]赋值给 dict.ht[0],给 dict.ht[1]初始化为空哈希表,释放原来的 dict.ht[0]的内存
-
将 rehashidx 赋值为-1,代表 rehash 结束
-
在 rehash 过程中,新增操作,则直接写入 ht[1],查询、修改和删除则会在 dict.ht[0]和 dict.ht[1]依次查找并执行。这样可以确保 ht[0]的数据只减不增,随着 rehash 最终为空
整个过程可以描述成:
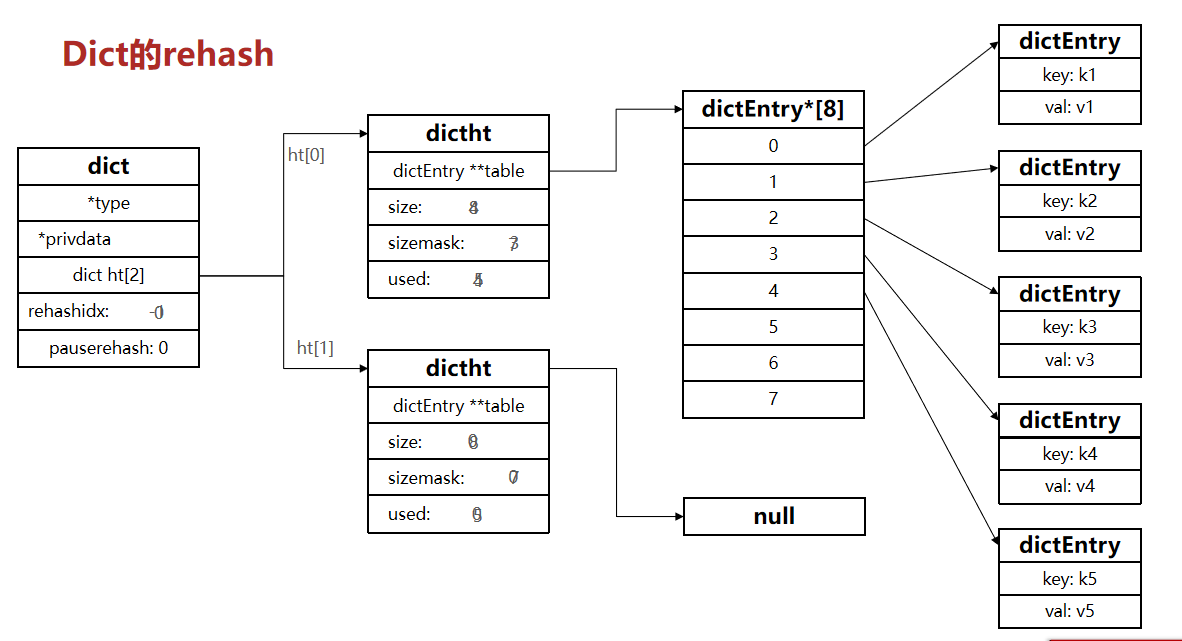
小总结:
Dict 的结构:
- 类似 java 的 HashTable,底层是数组加链表来解决哈希冲突
- Dict 包含两个哈希表,ht[0]平常用,ht[1]用来 rehash
Dict 的伸缩:
- 当 LoadFactor 大于 5 或者 LoadFactor 大于 1 并且没有子进程任务时,Dict 扩容
- 当 LoadFactor 小于 0.1 时,Dict 收缩
- 扩容大小为第一个大于等于 used + 1 的 2^n
- 收缩大小为第一个大于等于 used 的 2^n
- Dict 采用渐进式 rehash,每次访问 Dict 时执行一次 rehash
- rehash 时 ht[0]只减不增,新增操作只在 ht[1]执行,其它操作在两个哈希表
1.4 Redis 数据结构-ZipList
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
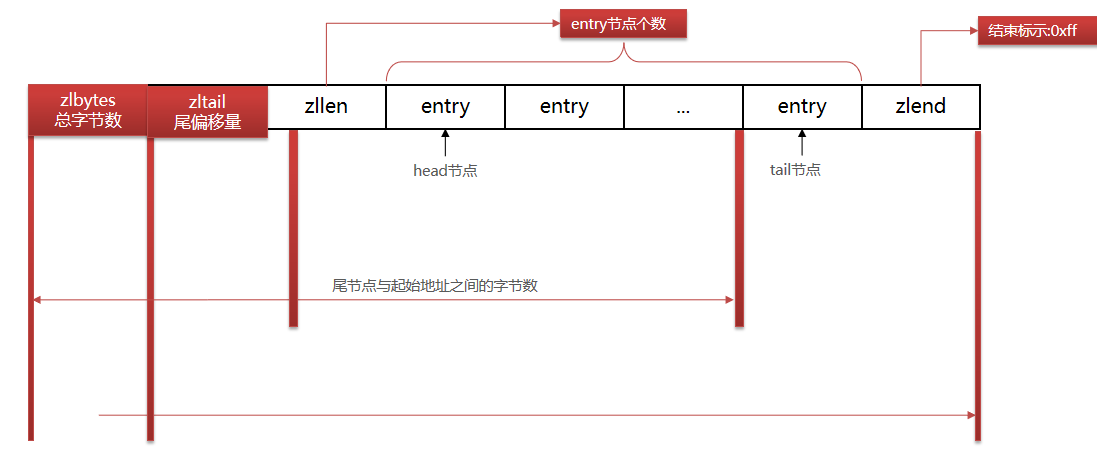

| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为 UINT16_MAX (65534),如果超过这个值,此处会记录为 65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ZipListEntry
ZipList 中的 Entry 并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用 16 个字节,浪费内存。而是采用了下面的结构:

-
previous_entry_length:前一节点的长度,占 1 个或 5 个字节。
- 如果前一节点的长度小于 254 字节,则采用 1 个字节来保存这个长度值
- 如果前一节点的长度大于 254 字节,则采用 5 个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才是真实长度数据
-
encoding:编码属性,记录 content 的数据类型(字符串还是整数)以及长度,占用 1 个、2 个或 5 个字节
-
contents:负责保存节点的数据,可以是字符串或整数
ZipList 中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值 0x1234,采用小端字节序后实际存储值为:0x3412
Encoding 编码
ZipListEntry 中的 encoding 编码分为字符串和整数两种: 字符串:如果 encoding 是以“00”、“01”或者“10”开头,则证明 content 是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab”和 “bc”

ZipListEntry 中的 encoding 编码分为字符串和整数两种:
- 整数:如果 encoding 是以“11”开始,则证明 content 是整数,且 encoding 固定只占用 1 个字节
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24 位有符整数(3 bytes) |
| 11111110 | 1 | 8 位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在 xxxx 位置保存数值,范围从 0001~1101,减 1 后结果为实际值 |

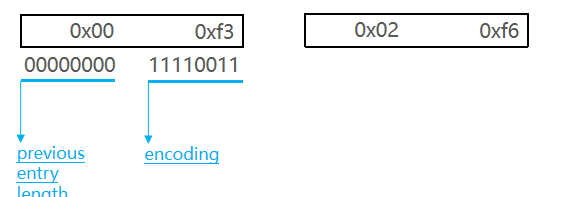
1.5 Redis 数据结构-ZipList 的连锁更新问题
ZipList 的每个 Entry 都包含 previous_entry_length 来记录上一个节点的大小,长度是 1 个或 5 个字节: 如果前一节点的长度小于 254 字节,则采用 1 个字节来保存这个长度值 如果前一节点的长度大于等于 254 字节,则采用 5 个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才是真实长度数据 现在,假设我们有 N 个连续的、长度为 250~253 字节之间的 entry,因此 entry 的 previous_entry_length 属性用 1 个字节即可表示,如图所示:

ZipList 这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
小总结:
ZipList 特性:
- 压缩列表的可以看做一种连续内存空间的”双向链表”
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
1.6 Redis 数据结构-QuickList
问题 1:ZipList 虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
答:为了缓解这个问题,我们必须限制 ZipList 的长度和 entry 大小。
问题 2:但是我们要存储大量数据,超出了 ZipList 最佳的上限该怎么办?
答:我们可以创建多个 ZipList 来分片存储数据。
问题 3:数据拆分后比较分散,不方便管理和查找,这多个 ZipList 如何建立联系?
答:Redis 在 3.2 版本引入了新的数据结构 QuickList,它是一个双端链表,只不过链表中的每个节点都是一个 ZipList。
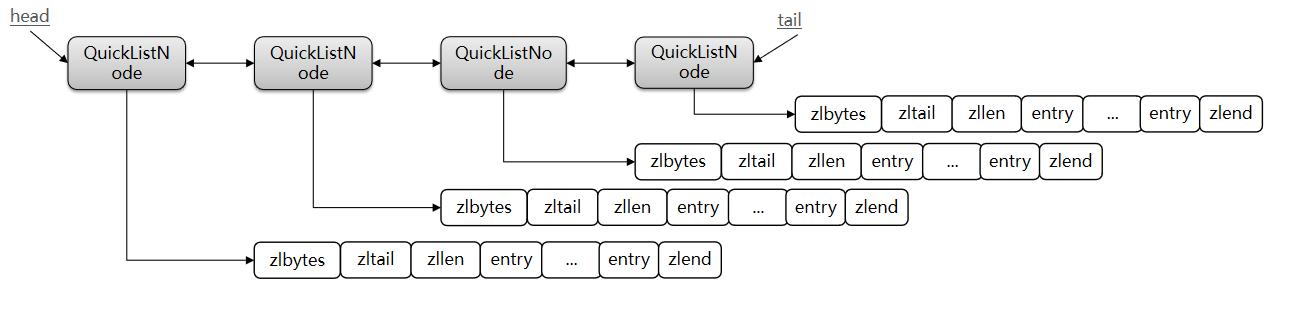
为了避免 QuickList 中的每个 ZipList 中 entry 过多,Redis 提供了一个配置项:list-max-ziplist-size 来限制。 如果值为正,则代表 ZipList 的允许的 entry 个数的最大值 如果值为负,则代表 ZipList 的最大内存大小,分 5 种情况:
- -1:每个 ZipList 的内存占用不能超过 4kb
- -2:每个 ZipList 的内存占用不能超过 8kb
- -3:每个 ZipList 的内存占用不能超过 16kb
- -4:每个 ZipList 的内存占用不能超过 32kb
- -5:每个 ZipList 的内存占用不能超过 64kb
其默认值为 -2:

以下是 QuickList 的和 QuickListNode 的结构源码:
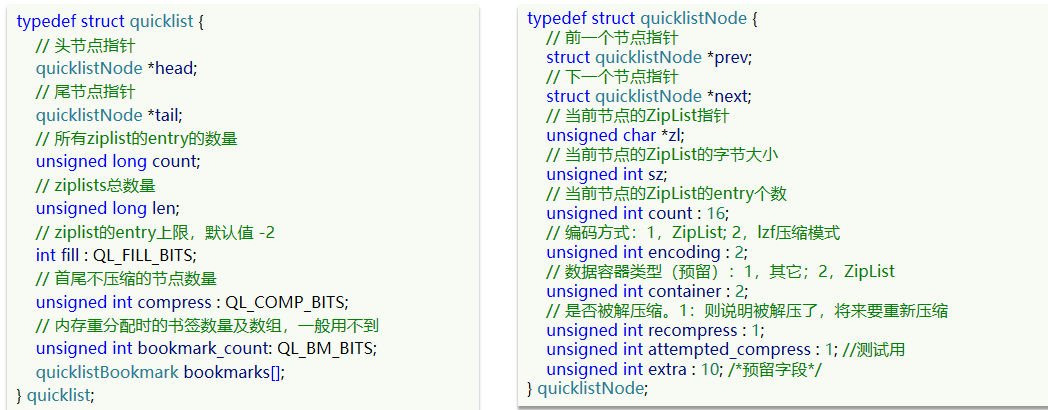
我们接下来用一段流程图来描述当前的这个结构
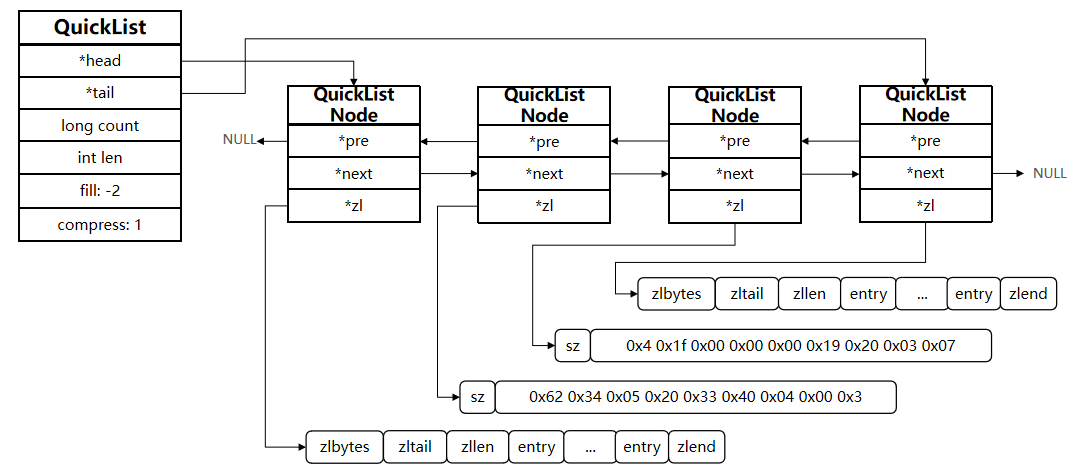
总结:
QuickList 的特点:
- 是一个节点为 ZipList 的双端链表
- 节点采用 ZipList,解决了传统链表的内存占用问题
- 控制了 ZipList 大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
1.7 Redis 数据结构-SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异: 元素按照升序排列存储 节点可能包含多个指针,指针跨度不同。
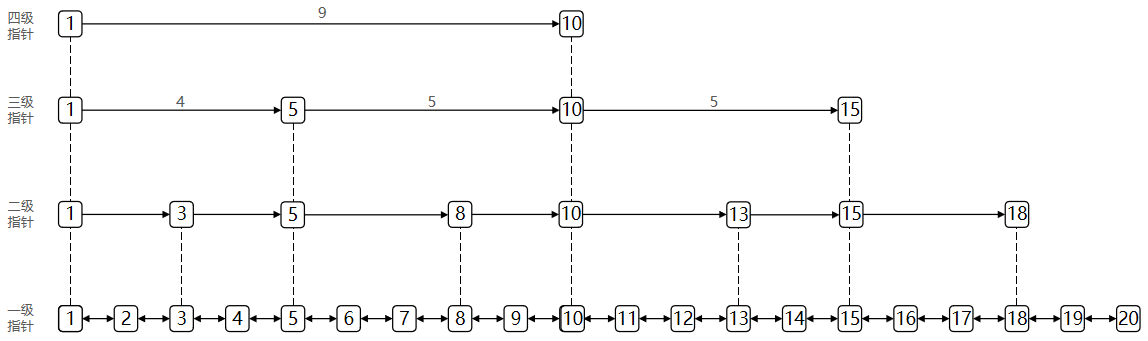
SkipList(跳表)首先是链表,但与传统链表相比有几点差异: 元素按照升序排列存储 节点可能包含多个指针,指针跨度不同。
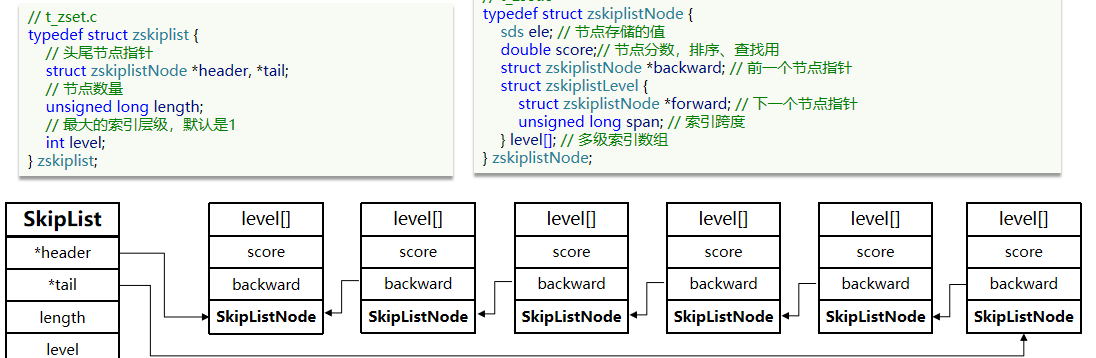
SkipList(跳表)首先是链表,但与传统链表相比有几点差异: 元素按照升序排列存储 节点可能包含多个指针,指针跨度不同。
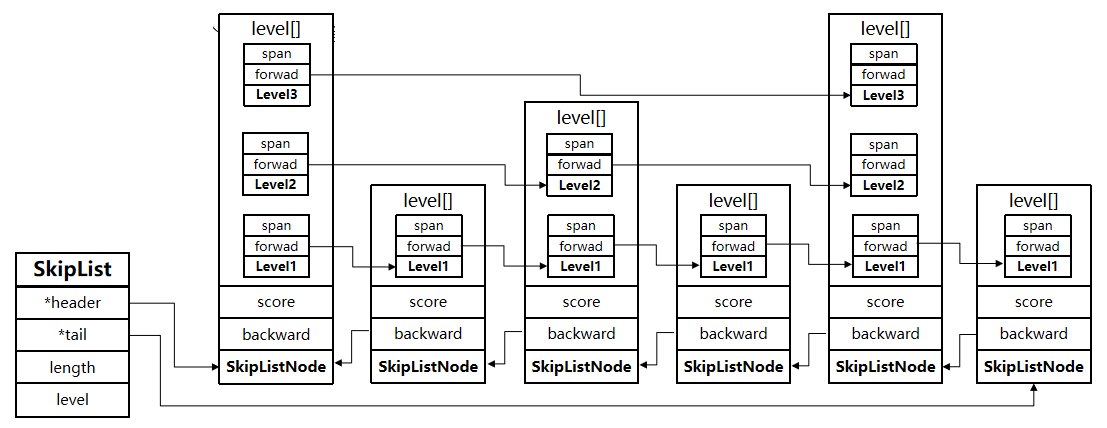
小总结:
SkipList 的特点:
- 跳跃表是一个双向链表,每个节点都包含 score 和 ele 值
- 节点按照 score 值排序,score 值一样则按照 ele 字典排序
- 每个节点都可以包含多层指针,层数是 1 到 32 之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
1.7 Redis 数据结构-RedisObject
Redis 中的任意数据类型的键和值都会被封装为一个 RedisObject,也叫做 Redis 对象,源码如下:
1、什么是 redisObject: 从 Redis 的使用者的角度来看,⼀个 Redis 节点包含多个 database(非 cluster 模式下默认是 16 个,cluster 模式下只能是 1 个),而一个 database 维护了从 key space 到 object space 的映射关系。这个映射关系的 key 是 string 类型,⽽value 可以是多种数据类型,比如: string, list, hash、set、sorted set 等。我们可以看到,key 的类型固定是 string,而 value 可能的类型是多个。 ⽽从 Redis 内部实现的⾓度来看,database 内的这个映射关系是用⼀个 dict 来维护的。dict 的 key 固定用⼀种数据结构来表达就够了,这就是动态字符串 sds。而 value 则比较复杂,为了在同⼀个 dict 内能够存储不同类型的 value,这就需要⼀个通⽤的数据结构,这个通用的数据结构就是 robj,全名是 redisObject。
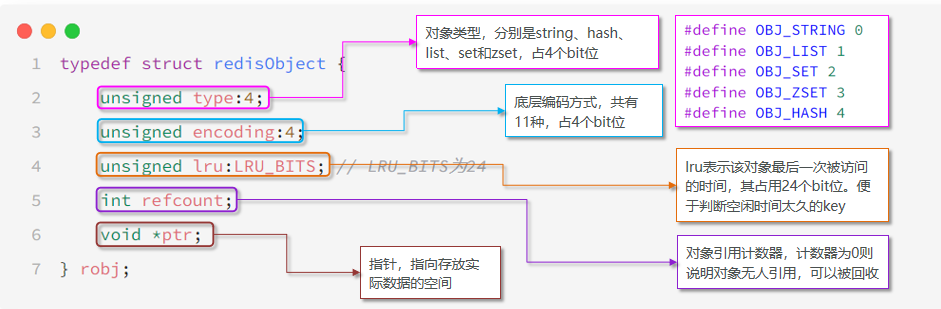
Redis 的编码方式
Redis 中会根据存储的数据类型不同,选择不同的编码方式,共包含 11 种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw 编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long 类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash 表(字典 dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr 的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream 流 |
五种数据结构
Redis 中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList 和 ZipList(3.2 以前)、QuickList(3.2 以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
1.8 Redis 数据结构-String
String 是 Redis 中最常见的数据存储类型:
其基本编码方式是 RAW,基于简单动态字符串(SDS)实现,存储上限为 512mb。
如果存储的 SDS 长度小于 44 字节,则会采用 EMBSTR 编码,此时 object head 与 SDS 是一段连续空间。申请内存时
只需要调用一次内存分配函数,效率更高。
(1)底层实现⽅式:动态字符串 sds 或者 long String 的内部存储结构⼀般是 sds(Simple Dynamic String,可以动态扩展内存),但是如果⼀个 String 类型的 value 的值是数字,那么 Redis 内部会把它转成 long 类型来存储,从⽽减少内存的使用。
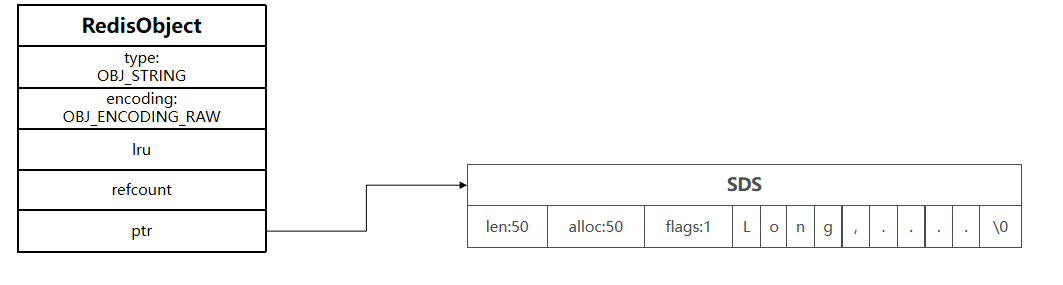
如果存储的字符串是整数值,并且大小在 LONG_MAX 范围内,则会采用 INT 编码:直接将数据保存在 RedisObject 的 ptr 指针位置(刚好 8 字节),不再需要 SDS 了。


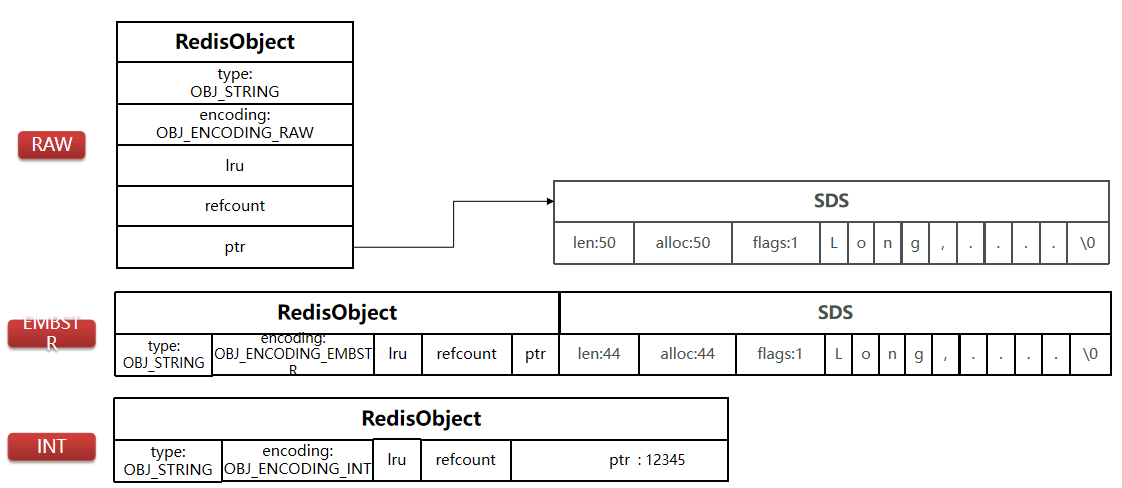
确切地说,String 在 Redis 中是⽤⼀个 robj 来表示的。
用来表示 String 的 robj 可能编码成 3 种内部表⽰:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT。 其中前两种编码使⽤的是 sds 来存储,最后⼀种 OBJ_ENCODING_INT 编码直接把 string 存成了 long 型。 在对 string 进行 incr, decr 等操作的时候,如果它内部是 OBJ_ENCODING_INT 编码,那么可以直接行加减操作;如果它内部是 OBJ_ENCODING_RAW 或 OBJ_ENCODING_EMBSTR 编码,那么 Redis 会先试图把 sds 存储的字符串转成 long 型,如果能转成功,再进行加减操作。对⼀个内部表示成 long 型的 string 执行 append, setbit, getrange 这些命令,针对的仍然是 string 的值(即⼗进制表示的字符串),而不是针对内部表⽰的 long 型进⾏操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的 ASCII 码分别是 0x33 和 0x32。当我们执行命令 setbit key 7 0 的时候,相当于把字符 0x33 变成了 0x32,这样字符串的值就变成了”22”。⽽如果将字符串”32”按照内部的 64 位 long 型来解释,那么它是 0x0000000000000020,在这个基础上执⾏setbit 位操作,结果就完全不对了。因此,在这些命令的实现中,会把 long 型先转成字符串再进行相应的操作。
1.9 Redis 数据结构-List
Redis 的 List 类型可以从首、尾操作列表中的元素:
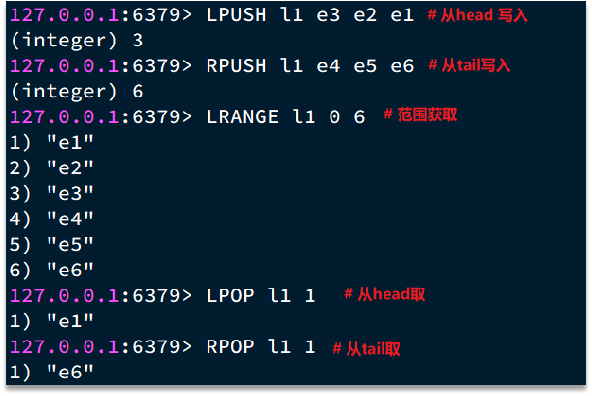
哪一个数据结构能满足上述特征?
- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个 ZipList,存储上限高
Redis 的 List 结构类似一个双端链表,可以从首、尾操作列表中的元素:
在 3.2 版本之前,Redis 采用 ZipList 和 LinkedList 来实现 List,当元素数量小于 512 并且元素大小小于 64 字节时采用 ZipList 编码,超过则采用 LinkedList 编码。
在 3.2 版本之后,Redis 统一采用 QuickList 来实现 List:
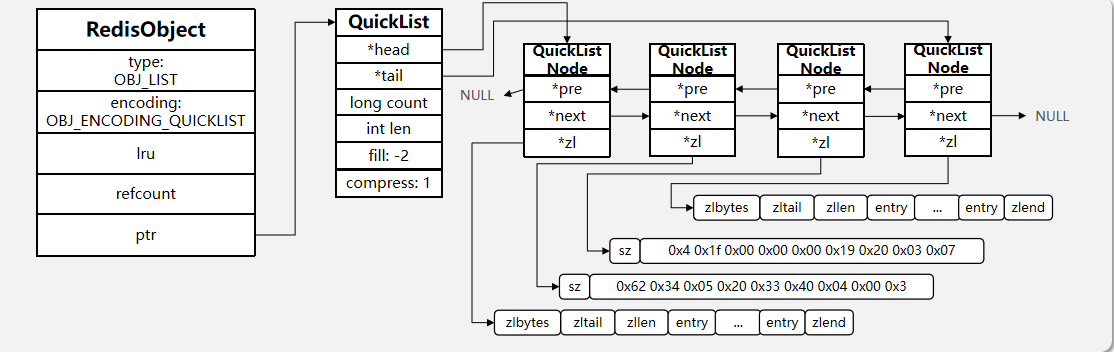
2.0 Redis 数据结构-Set 结构
Set 是 Redis 中的单列集合,满足下列特点:
- 不保证有序性
- 保证元素唯一
- 求交集、并集、差集
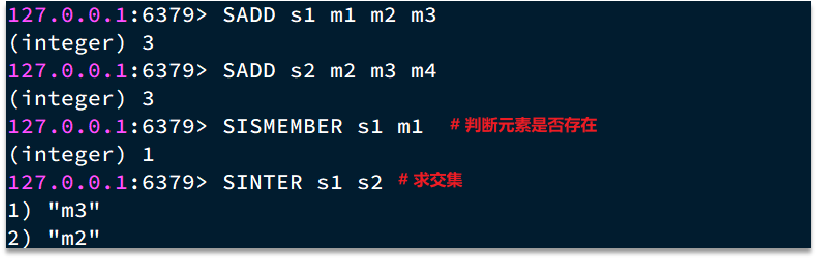
可以看出,Set 对查询元素的效率要求非常高,思考一下,什么样的数据结构可以满足? HashTable,也就是 Redis 中的 Dict,不过 Dict 是双列集合(可以存键、值对)
Set 是 Redis 中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。 为了查询效率和唯一性,set 采用 HT 编码(Dict)。Dict 中的 key 用来存储元素,value 统一为 null。 当存储的所有数据都是整数,并且元素数量不超过 set-max-intset-entries 时,Set 会采用 IntSet 编码,以节省内存
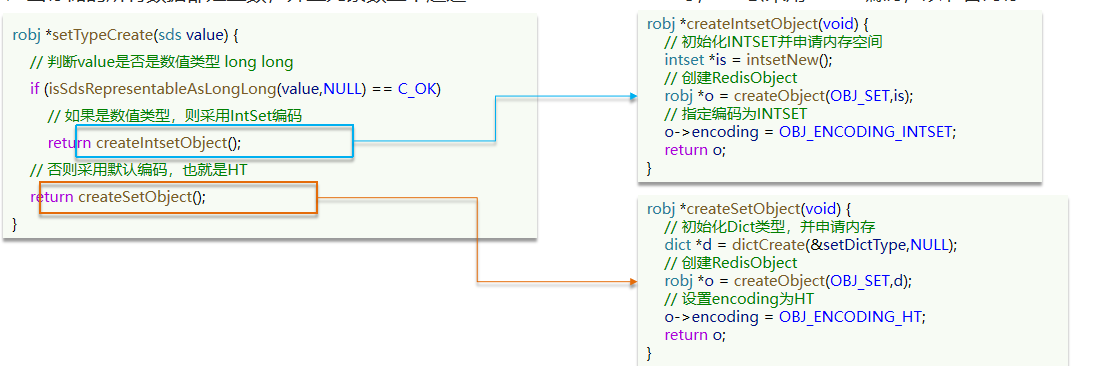
结构如下:
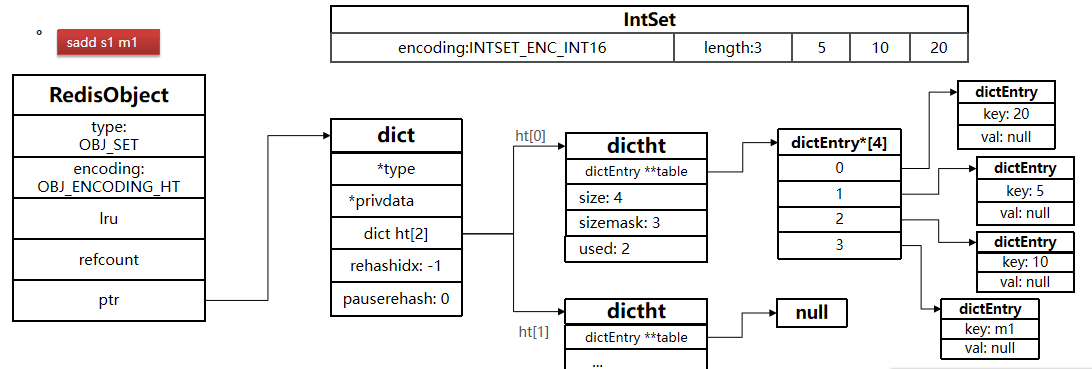
2.1、Redis 数据结构-ZSET
ZSet 也就是 SortedSet,其中每一个元素都需要指定一个 score 值和 member 值:
- 可以根据 score 值排序后
- member 必须唯一
- 可以根据 member 查询分数

因此,zset 底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储 score 和 ele 值(member)
- HT(Dict):可以键值存储,并且可以根据 key 找 value

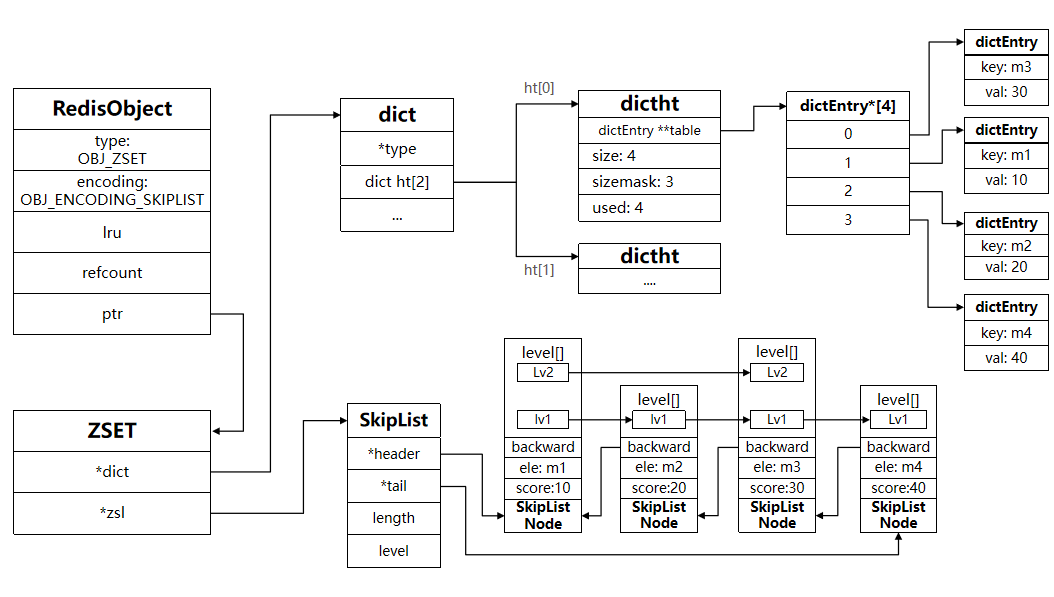
当元素数量不多时,HT 和 SkipList 的优势不明显,而且更耗内存。因此 zset 还会采用 ZipList 结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于 zset_max_ziplist_entries,默认值 128
- 每个元素都小于 zset_max_ziplist_value 字节,默认值 64
ziplist 本身没有排序功能,而且没有键值对的概念,因此需要有 zset 通过编码实现:
- ZipList 是连续内存,因此 score 和 element 是紧挨在一起的两个 entry, element 在前,score 在后
- score 越小越接近队首,score 越大越接近队尾,按照 score 值升序排列
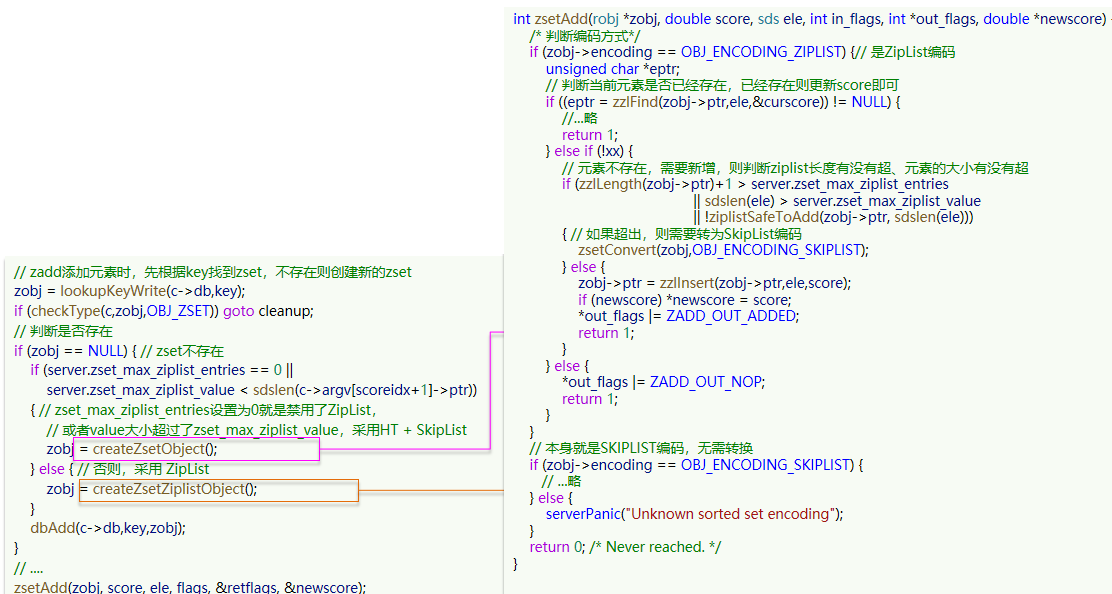
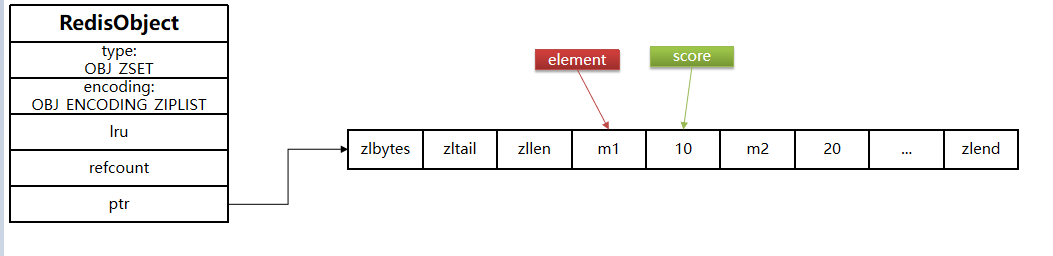
2.2 、Redis 数据结构-Hash
Hash 结构与 Redis 中的 Zset 非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset 的键是 member,值是 score;hash 的键和值都是任意值
- zset 要根据 score 排序;hash 则无需排序
(1)底层实现方式:压缩列表 ziplist 或者 字典 dict 当 Hash 中数据项比较少的情况下,Hash 底层才⽤压缩列表 ziplist 进⾏存储数据,随着数据的增加,底层的 ziplist 就可能会转成 dict,具体配置如下:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
当满足上面两个条件其中之⼀的时候,Redis 就使⽤dict 字典来实现 hash。 Redis 的 hash 之所以这样设计,是因为当 ziplist 变得很⼤的时候,它有如下几个缺点:
- 每次插⼊或修改引发的 realloc 操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当 ziplist 数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为 ziplist 上的查找需要进行遍历。
总之,ziplist 本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存 realloc,可能导致内存拷贝。
hash 结构如下:
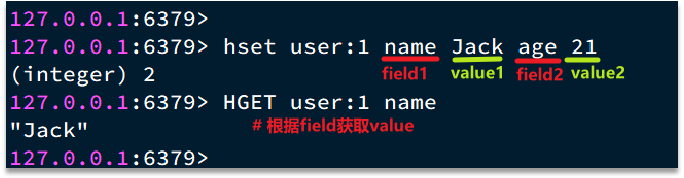
zset 集合如下:

因此,Hash 底层采用的编码与 Zset 也基本一致,只需要把排序有关的 SkipList 去掉即可:
Hash 结构默认采用 ZipList 编码,用以节省内存。 ZipList 中相邻的两个 entry 分别保存 field 和 value
当数据量较大时,Hash 结构会转为 HT 编码,也就是 Dict,触发条件有两个:
- ZipList 中的元素数量超过了 hash-max-ziplist-entries(默认 512)
- ZipList 中的任意 entry 大小超过了 hash-max-ziplist-value(默认 64 字节)
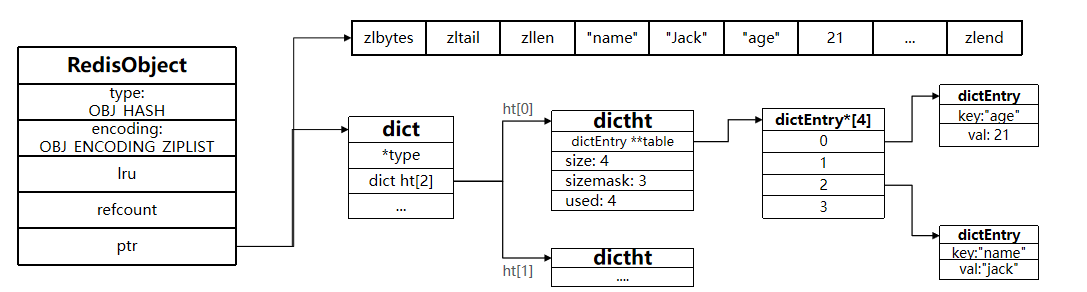
2、原理篇-Redis 网络模型
2.1 用户空间和内核态空间
服务器大多都采用 Linux 系统,这里我们以 Linux 为例来讲解:
ubuntu 和 Centos 都是 Linux 的发行版,发行版可以看成对 linux 包了一层壳,任何 Linux 发行版,其系统内核都是 Linux。我们的应用都需要通过 Linux 内核与硬件交互

用户的应用,比如 redis,mysql 等其实是没有办法去执行访问我们操作系统的硬件的,所以我们可以通过发行版的这个壳子去访问内核,再通过内核去访问计算机硬件

计算机硬件包括,如 cpu,内存,网卡等等,内核(通过寻址空间)可以操作硬件的,但是内核需要不同设备的驱动,有了这些驱动之后,内核就可以去对计算机硬件去进行 内存管理,文件系统的管理,进程的管理等等
我们想要用户的应用来访问,计算机就必须要通过对外暴露的一些接口,才能访问到,从而简介的实现对内核的操控,但是内核本身上来说也是一个应用,所以他本身也需要一些内存,cpu 等设备资源,用户应用本身也在消耗这些资源,如果不加任何限制,用户去操作随意的去操作我们的资源,就有可能导致一些冲突,甚至有可能导致我们的系统出现无法运行的问题,因此我们需要把用户和内核隔离开
进程的寻址空间划分成两部分:内核空间、用户空间
什么是寻址空间呢?我们的应用程序也好,还是内核空间也好,都是没有办法直接去物理内存的,而是通过分配一些虚拟内存映射到物理内存中,我们的内核和应用程序去访问虚拟内存的时候,就需要一个虚拟地址,这个地址是一个无符号的整数,比如一个 32 位的操作系统,他的带宽就是 32,他的虚拟地址就是 2 的 32 次方,也就是说他寻址的范围就是 0~2 的 32 次方, 这片寻址空间对应的就是 2 的 32 个字节,就是 4GB,这个 4GB,会有 3 个 GB 分给用户空间,会有 1GB 给内核系统
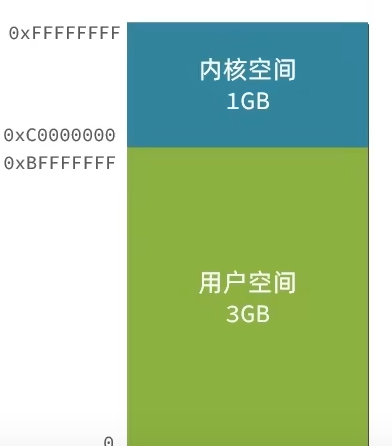
在 linux 中,他们权限分成两个等级,0 和 3,用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问内核空间可以执行特权命令(Ring0),调用一切系统资源,所以一般情况下,用户的操作是运行在用户空间,而内核运行的数据是在内核空间的,而有的情况下,一个应用程序需要去调用一些特权资源,去调用一些内核空间的操作,所以此时他俩需要在用户态和内核态之间进行切换。
比如:
Linux 系统为了提高 IO 效率,会在用户空间和内核空间都加入缓冲区:
写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
读数据时,要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
针对这个操作:我们的用户在写读数据时,会去向内核态申请,想要读取内核的数据,而内核数据要去等待驱动程序从硬件上读取数据,当从磁盘上加载到数据之后,内核会将数据写入到内核的缓冲区中,然后再将数据拷贝到用户态的 buffer 中,然后再返回给应用程序,整体而言,速度慢,就是这个原因,为了加速,我们希望 read 也好,还是 wait for data 也最好都不要等待,或者时间尽量的短。
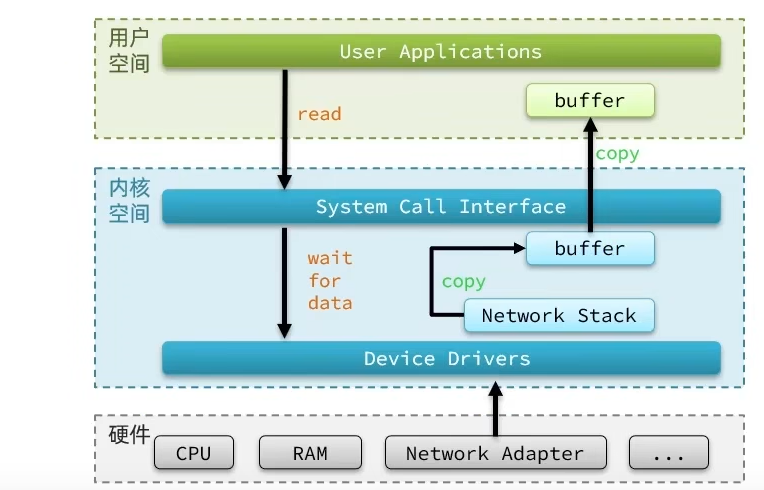
2.2.网络模型-阻塞 IO
在《UNIX 网络编程》一书中,总结归纳了 5 种 IO 模型:
- 阻塞 IO(Blocking IO)
- 非阻塞 IO(Nonblocking IO)
- IO 多路复用(IO Multiplexing)
- 信号驱动 IO(Signal Driven IO)
- 异步 IO(Asynchronous IO)
应用程序想要去读取数据,他是无法直接去读取磁盘数据的,他需要先到内核里边去等待内核操作硬件拿到数据,这个过程就是 1,是需要等待的,等到内核从磁盘上把数据加载出来之后,再把这个数据写给用户的缓存区,这个过程是 2,如果是阻塞 IO,那么整个过程中,用户从发起读请求开始,一直到读取到数据,都是一个阻塞状态。
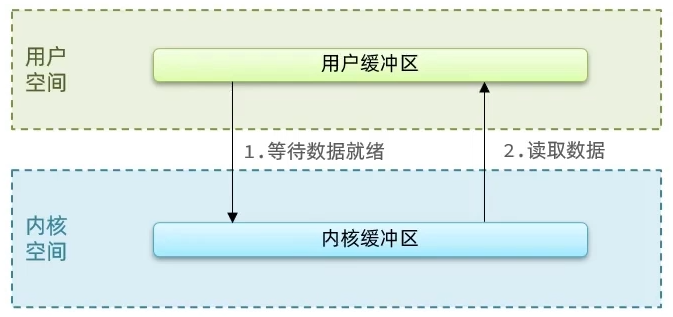
具体流程如下图:
用户去读取数据时,会去先发起 recvform 一个命令,去尝试从内核上加载数据,如果内核没有数据,那么用户就会等待,此时内核会去从硬件上读取数据,内核读取数据之后,会把数据拷贝到用户态,并且返回 ok,整个过程,都是阻塞等待的,这就是阻塞 IO
总结如下:
顾名思义,阻塞 IO 就是两个阶段都必须阻塞等待:
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 此时用户进程也处于阻塞状态
阶段二:
- 数据到达并拷贝到内核缓冲区,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
可以看到,阻塞 IO 模型中,用户进程在两个阶段都是阻塞状态。
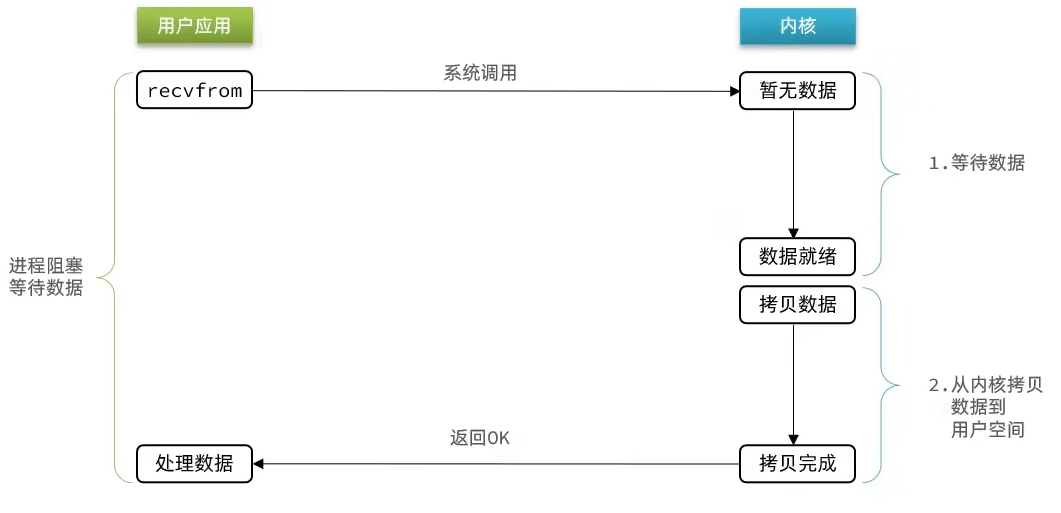
2.3 网络模型-非阻塞 IO
顾名思义,非阻塞 IO 的 recvfrom 操作会立即返回结果而不是阻塞用户进程。
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程拿到 error 后,再次尝试读取
- 循环往复,直到数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据
- 可以看到,非阻塞 IO 模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致 CPU 空转,CPU 使用率暴增。
2.4 网络模型-IO 多路复用
无论是阻塞 IO 还是非阻塞 IO,用户应用在一阶段都需要调用 recvfrom 来获取数据,差别在于无数据时的处理方案:
如果调用 recvfrom 时,恰好没有数据,阻塞 IO 会使 CPU 阻塞,非阻塞 IO 使 CPU 空转,都不能充分发挥 CPU 的作用。 如果调用 recvfrom 时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
所以怎么看起来以上两种方式性能都不好
而在单线程情况下,只能依次处理 IO 事件,如果正在处理的 IO 事件恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有 IO 事件都必须等待,性能自然会很差。
就比如服务员给顾客点餐,分两步:
- 顾客思考要吃什么(等待数据就绪)
- 顾客想好了,开始点餐(读取数据)
要提高效率有几种办法?
方案一:增加更多服务员(多线程) 方案二:不排队,谁想好了吃什么(数据就绪了),服务员就给谁点餐(用户应用就去读取数据)
那么问题来了:用户进程如何知道内核中数据是否就绪呢?
所以接下来就需要详细的来解决多路复用模型是如何知道到底怎么知道内核数据是否就绪的问题了
这个问题的解决依赖于提出的
文件描述符(File Descriptor):简称 FD,是一个从 0 开始的无符号整数,用来关联 Linux 中的一个文件。在 Linux 中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
通过 FD,我们的网络模型可以利用一个线程监听多个 FD,并在某个 FD 可读、可写时得到通知,从而避免无效的等待,充分利用 CPU 资源。
阶段一:
- 用户进程调用 select,指定要监听的 FD 集合
- 核监听 FD 对应的多个 socket
- 任意一个或多个 socket 数据就绪则返回 readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找到就绪的 socket
- 依次调用 recvfrom 读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
当用户去读取数据的时候,不再去直接调用 recvfrom 了,而是调用 select 的函数,select 函数会将需要监听的数据交给内核,由内核去检查这些数据是否就绪了,如果说这个数据就绪了,就会通知应用程序数据就绪,然后来读取数据,再从内核中把数据拷贝给用户态,完成数据处理,如果 N 多个 FD 一个都没处理完,此时就进行等待。
用 IO 复用模式,可以确保去读数据的时候,数据是一定存在的,他的效率比原来的阻塞 IO 和非阻塞 IO 性能都要高
IO 多路复用是利用单个线程来同时监听多个 FD,并在某个 FD 可读、可写时得到通知,从而避免无效的等待,充分利用 CPU 资源。不过监听 FD 的方式、通知的方式又有多种实现,常见的有:
- select
- poll
- epoll
其中 select 和 pool 相当于是当被监听的数据准备好之后,他会把你监听的 FD 整个数据都发给你,你需要到整个 FD 中去找,哪些是处理好了的,需要通过遍历的方式,所以性能也并不是那么好
而 epoll,则相当于内核准备好了之后,他会把准备好的数据,直接发给你,咱们就省去了遍历的动作。
2.5 网络模型-IO 多路复用-select 方式
select 是 Linux 最早是由的 I/O 多路复用技术:
简单说,就是我们把需要处理的数据封装成 FD,然后在用户态时创建一个 fd 的集合(这个集合的大小是要监听的那个 FD 的最大值+1,但是大小整体是有限制的 ),这个集合的长度大小是有限制的,同时在这个集合中,标明出来我们要控制哪些数据,
比如要监听的数据,是 1,2,5 三个数据,此时会执行 select 函数,然后将整个 fd 发给内核态,内核态会去遍历用户态传递过来的数据,如果发现这里边都数据都没有就绪,就休眠,直到有数据准备好时,就会被唤醒,唤醒之后,再次遍历一遍,看看谁准备好了,然后再将处理掉没有准备好的数据,最后再将这个 FD 集合写回到用户态中去,此时用户态就知道了,奥,有人准备好了,但是对于用户态而言,并不知道谁处理好了,所以用户态也需要去进行遍历,然后找到对应准备好数据的节点,再去发起读请求,我们会发现,这种模式下他虽然比阻塞 IO 和非阻塞 IO 好,但是依然有些麻烦的事情, 比如说频繁的传递 fd 集合,频繁的去遍历 FD 等问题

2.6 网络模型-IO 多路复用模型-poll 模式
poll 模式对 select 模式做了简单改进,但性能提升不明显,部分关键代码如下:
IO 流程:
- 创建 pollfd 数组,向其中添加关注的 fd 信息,数组大小自定义
- 调用 poll 函数,将 pollfd 数组拷贝到内核空间,转链表存储,无上限
- 内核遍历 fd,判断是否就绪
- 数据就绪或超时后,拷贝 pollfd 数组到用户空间,返回就绪 fd 数量 n
- 用户进程判断 n 是否大于 0,大于 0 则遍历 pollfd 数组,找到就绪的 fd
与 select 对比:
- select 模式中的 fd_set 大小固定为 1024,而 pollfd 在内核中采用链表,理论上无上限
- 监听 FD 越多,每次遍历消耗时间也越久,性能反而会下降

2.7 网络模型-IO 多路复用模型-epoll 函数
epoll 模式是对 select 和 poll 的改进,它提供了三个函数:
第一个是:eventpoll 的函数,他内部包含两个东西
一个是:
1、红黑树-> 记录的事要监听的 FD
2、一个是链表->一个链表,记录的是就绪的 FD
紧接着调用 epoll_ctl 操作,将要监听的数据添加到红黑树上去,并且给每个 fd 设置一个监听函数,这个函数会在 fd 数据就绪时触发,就是准备好了,现在就把 fd 把数据添加到 list_head 中去
3、调用 epoll_wait 函数
就去等待,在用户态创建一个空的 events 数组,当就绪之后,我们的回调函数会把数据添加到 list_head 中去,当调用这个函数的时候,会去检查 list_head,当然这个过程需要参考配置的等待时间,可以等一定时间,也可以一直等, 如果在此过程中,检查到了 list_head 中有数据会将数据添加到链表中,此时将数据放入到 events 数组中,并且返回对应的操作的数量,用户态的此时收到响应后,从 events 中拿到对应准备好的数据的节点,再去调用方法去拿数据。
小总结:
select 模式存在的三个问题:
- 能监听的 FD 最大不超过 1024
- 每次 select 都需要把所有要监听的 FD 都拷贝到内核空间
- 每次都要遍历所有 FD 来判断就绪状态
poll 模式的问题:
- poll 利用链表解决了 select 中监听 FD 上限的问题,但依然要遍历所有 FD,如果监听较多,性能会下降
epoll 模式中如何解决这些问题的?
- 基于 epoll 实例中的红黑树保存要监听的 FD,理论上无上限,而且增删改查效率都非常高
- 每个 FD 只需要执行一次 epoll_ctl 添加到红黑树,以后每次 epol_wait 无需传递任何参数,无需重复拷贝 FD 到内核空间
- 利用 ep_poll_callback 机制来监听 FD 状态,无需遍历所有 FD,因此性能不会随监听的 FD 数量增多而下降
2.8、网络模型-epoll 中的 ET 和 LT
当 FD 有数据可读时,我们调用 epoll_wait(或者 select、poll)可以得到通知。但是事件通知的模式有两种:
- LevelTriggered:简称 LT,也叫做水平触发。只要某个 FD 中有数据可读,每次调用 epoll_wait 都会得到通知。
- EdgeTriggered:简称 ET,也叫做边沿触发。只有在某个 FD 有状态变化时,调用 epoll_wait 才会被通知。
举个栗子:
- 假设一个客户端 socket 对应的 FD 已经注册到了 epoll 实例中
- 客户端 socket 发送了 2kb 的数据
- 服务端调用 epoll_wait,得到通知说 FD 就绪
- 服务端从 FD 读取了 1kb 数据回到步骤 3(再次调用 epoll_wait,形成循环)
结论
如果我们采用 LT 模式,因为 FD 中仍有 1kb 数据,则第⑤步依然会返回结果,并且得到通知 如果我们采用 ET 模式,因为第③步已经消费了 FD 可读事件,第⑤步 FD 状态没有变化,因此 epoll_wait 不会返回,数据无法读取,客户端响应超时。
2.9 网络模型-基于 epoll 的服务器端流程
我们来梳理一下这张图
服务器启动以后,服务端会去调用 epoll_create,创建一个 epoll 实例,epoll 实例中包含两个数据
1、红黑树(为空):rb_root 用来去记录需要被监听的 FD
2、链表(为空):list_head,用来存放已经就绪的 FD
创建好了之后,会去调用 epoll_ctl 函数,此函数会会将需要监听的数据添加到 rb_root 中去,并且对当前这些存在于红黑树的节点设置回调函数,当这些被监听的数据一旦准备完成,就会被调用,而调用的结果就是将红黑树的 fd 添加到 list_head 中去(但是此时并没有完成)
3、当第二步完成后,就会调用 epoll_wait 函数,这个函数会去校验是否有数据准备完毕(因为数据一旦准备就绪,就会被回调函数添加到 list_head 中),在等待了一段时间后(可以进行配置),如果等够了超时时间,则返回没有数据,如果有,则进一步判断当前是什么事件,如果是建立连接时间,则调用 accept() 接受客户端 socket,拿到建立连接的 socket,然后建立起来连接,如果是其他事件,则把数据进行写出
3.0 、网络模型-信号驱动
信号驱动 IO 是与内核建立 SIGIO 的信号关联并设置回调,当内核有 FD 就绪时,会发出 SIGIO 信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
阶段一:
- 用户进程调用 sigaction,注册信号处理函数
- 内核返回成功,开始监听 FD
- 用户进程不阻塞等待,可以执行其它业务
- 当内核数据就绪后,回调用户进程的 SIGIO 处理函数
阶段二:
- 收到 SIGIO 回调信号
- 调用 recvfrom,读取
- 内核将数据拷贝到用户空间
- 用户进程处理数据
当有大量 IO 操作时,信号较多,SIGIO 处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
3.0.1 异步 IO
这种方式,不仅仅是用户态在试图读取数据后,不阻塞,而且当内核的数据准备完成后,也不会阻塞
他会由内核将所有数据处理完成后,由内核将数据写入到用户态中,然后才算完成,所以性能极高,不会有任何阻塞,全部都由内核完成,可以看到,异步 IO 模型中,用户进程在两个阶段都是非阻塞状态。
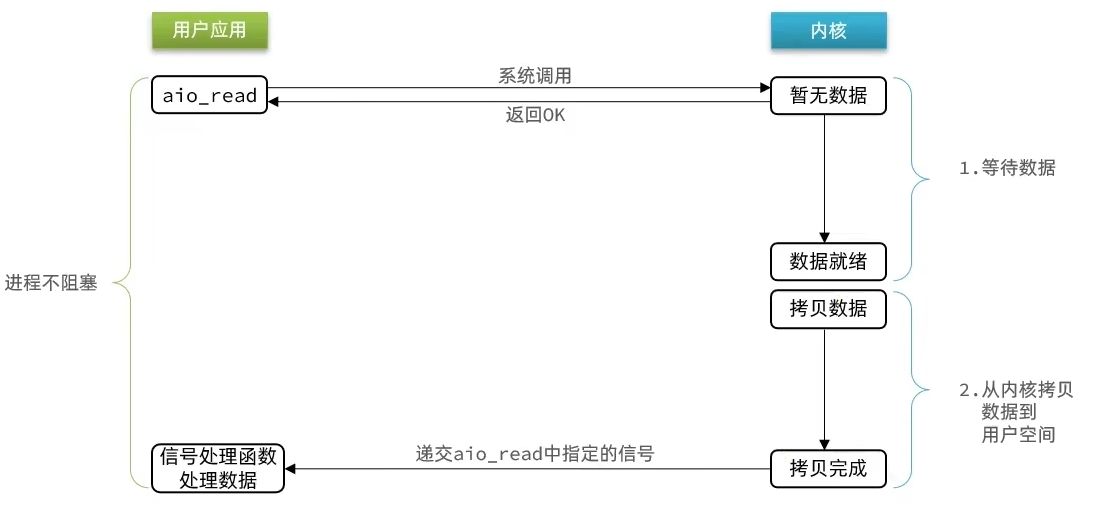
3.0.2 对比
最后用一幅图,来说明他们之间的区别
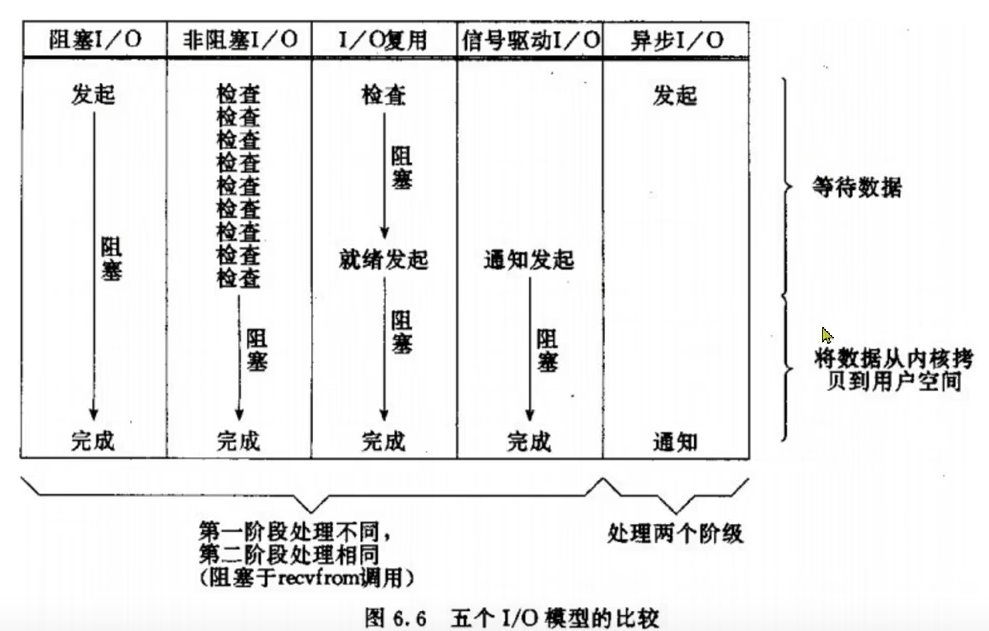
3.1 、网络模型-Redis 是单线程的吗?为什么使用单线程
Redis 到底是单线程还是多线程?
- 如果仅仅聊 Redis 的核心业务部分(命令处理),答案是单线程
- 如果是聊整个 Redis,那么答案就是多线程
在 Redis 版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
- Redis v4.0:引入多线程异步处理一些耗时较旧的任务,例如异步删除命令 unlink
- Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核 CPU 的利用率
因此,对于 Redis 的核心网络模型,在 Redis 6.0 之前确实都是单线程。是利用 epoll(Linux 系统)这样的 IO 多路复用技术在事件循环中不断处理客户端情况。
为什么 Redis 要选择单线程?
- 抛开持久化不谈,Redis 是纯 内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣
3.2 、Redis 的单线程模型-Redis 单线程和多线程网络模型变更
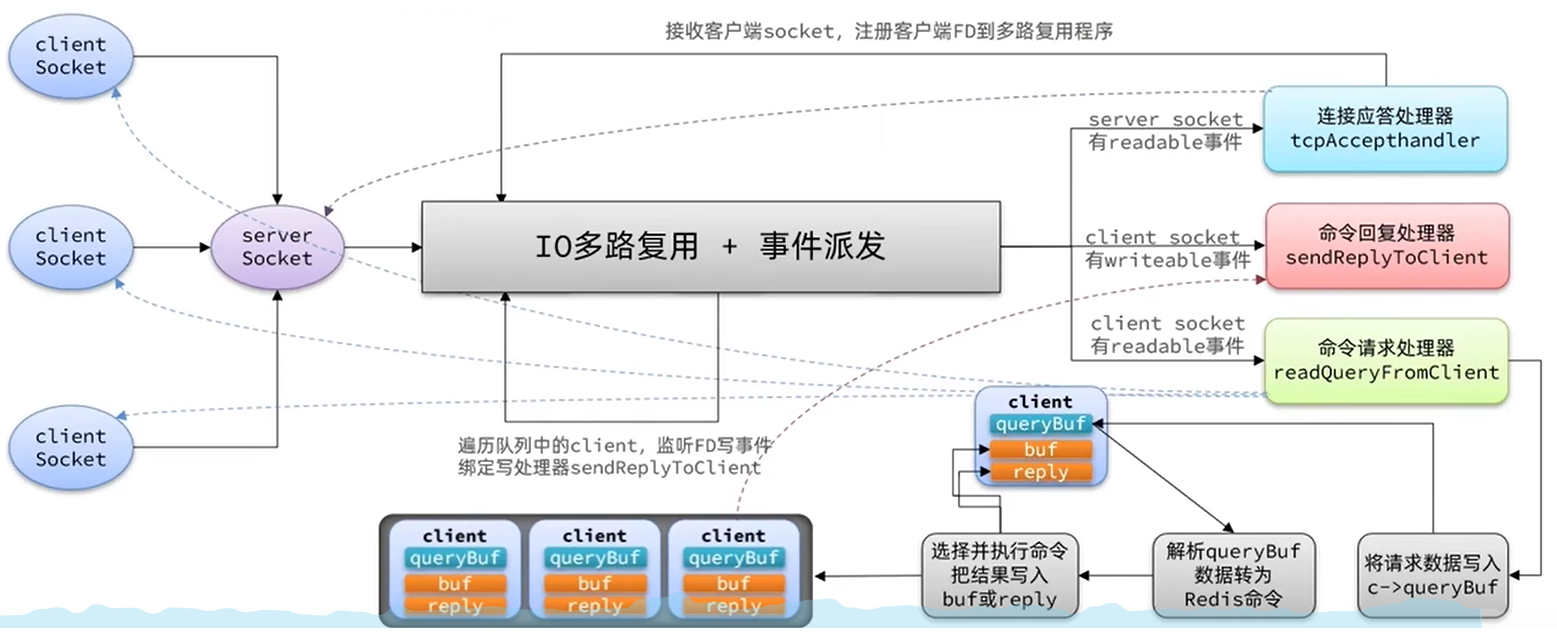
当我们的客户端想要去连接我们服务器,会去先到 IO 多路复用模型去进行排队,会有一个连接应答处理器,他会去接受读请求,然后又把读请求注册到具体模型中去,此时这些建立起来的连接,如果是客户端请求处理器去进行执行命令时,他会去把数据读取出来,然后把数据放入到 client 中, clinet 去解析当前的命令转化为 redis 认识的命令,接下来就开始处理这些命令,从 redis 中的 command 中找到这些命令,然后就真正的去操作对应的数据了,当数据操作完成后,会去找到命令回复处理器,再由他将数据写出。
3、Redis 通信协议-RESP 协议
Redis 是一个 CS 架构的软件,通信一般分两步(不包括 pipeline 和 PubSub):
客户端(client)向服务端(server)发送一条命令
服务端解析并执行命令,返回响应结果给客户端
因此客户端发送命令的格式、服务端响应结果的格式必须有一个规范,这个规范就是通信协议。
而在 Redis 中采用的是 RESP(Redis Serialization Protocol)协议:
Redis 1.2 版本引入了 RESP 协议
Redis 2.0 版本中成为与 Redis 服务端通信的标准,称为 RESP2
Redis 6.0 版本中,从 RESP2 升级到了 RESP3 协议,增加了更多数据类型并且支持 6.0 的新特性—客户端缓存
但目前,默认使用的依然是 RESP2 协议,也是我们要学习的协议版本(以下简称 RESP)。
在 RESP 中,通过首字节的字符来区分不同数据类型,常用的数据类型包括 5 种:
单行字符串:首字节是 ‘+’ ,后面跟上单行字符串,以 CRLF( “\r\n” )结尾。例如返回”OK”: “+OK\r\n”
错误(Errors):首字节是 ‘-’ ,与单行字符串格式一样,只是字符串是异常信息,例如:“-Error message\r\n”
数值:首字节是 ‘:’ ,后面跟上数字格式的字符串,以 CRLF 结尾。例如:“:10\r\n”
多行字符串:首字节是 ‘$’ ,表示二进制安全的字符串,最大支持 512MB:
如果大小为 0,则代表空字符串:“$0\r\n\r\n”
如果大小为-1,则代表不存在:”$-1\r\n”
数组:首字节是 ‘*’,后面跟上数组元素个数,再跟上元素,元素数据类型不限:

3.1、Redis 通信协议-基于 Socket 自定义 Redis 的客户端
Redis 支持 TCP 通信,因此我们可以使用 Socket 来模拟客户端,与 Redis 服务端建立连接:
package main
import (
"bufio"
"fmt"
"net"
"strconv"
"strings"
)
func main() {
// ===================== 1. 建立 TCP 连接到 Redis =====================
// Redis 服务地址和端口
host := "127.0.0.1"
port := 6379
// 发起 TCP 连接(Dial 对应 Java new Socket)
conn, err := net.Dial("tcp", fmt.Sprintf("%s:%d", host, port))
if err != nil {
fmt.Println("连接 Redis 失败:", err)
return
}
// 程序结束后关闭连接(对应 Java finally close)
defer conn.Close()
// 创建读写缓冲(提高效率,对应 Java BufferedReader/PrintWriter)
reader := bufio.NewReader(conn)
writer := bufio.NewWriter(conn)
// ===================== 2. 执行 Redis 命令 =====================
// 1) 设置 key:set name 虎哥
sendRequest(writer, "set", "name", "虎哥")
resp, err := handleResponse(reader)
if err != nil {
fmt.Println("set 错误:", err)
return
}
fmt.Println("set 结果:", resp)
// 2) 获取 key:get name
sendRequest(writer, "get", "name")
resp, err = handleResponse(reader)
if err != nil {
fmt.Println("get 错误:", err)
return
}
fmt.Println("get 结果:", resp)
// 3) 批量获取:mget name num msg
sendRequest(writer, "mget", "name", "num", "msg")
resp, err = handleResponse(reader)
if err != nil {
fmt.Println("mget 错误:", err)
return
}
fmt.Println("mget 结果:", resp)
}
// ----------------------------------------------------------------
// sendRequest:发送 Redis 命令,**按照 RESP 协议拼接请求**
// 参数:命令 + 参数列表(例如:"set","name","虎哥")
// ----------------------------------------------------------------
func sendRequest(w *bufio.Writer, args ...string) {
// ========== 拼接 RESP 数组格式:*参数个数 \r\n ==========
// 示例:*3(代表有3个元素:set、name、虎哥)
cmd := fmt.Sprintf("*%d\r\n", len(args))
// ========== 遍历每个参数,拼接成 RESP 批量字符串 ==========
// 格式:$长度 \r\n 内容 \r\n
for _, arg := range args {
// 拼接 $长度
cmd += fmt.Sprintf("$%d\r\n", len(arg))
// 拼接参数内容
cmd += fmt.Sprintf("%s\r\n", arg)
}
// ========== 写入缓冲区并发送(flush) ==========
w.WriteString(cmd)
w.Flush()
}
// ----------------------------------------------------------------
// handleResponse:解析 Redis 响应(RESP 协议核心)
// 读取首字节判断类型,递归解析
// ----------------------------------------------------------------
func handleResponse(r *bufio.Reader) (interface{}, error) {
// 1. 读取第一个字节(RESP 类型标识:+ - : $ *)
prefix, err := r.ReadByte()
if err != nil {
return nil, err
}
// 2. 根据类型前缀处理
switch prefix {
case '+':
// --------------------
// 简单字符串:+OK\r\n
// --------------------
line, err := readLine(r)
return line, err
case '-':
// --------------------
// 错误信息:-ERR xxx\r\n
// --------------------
line, _ := readLine(r)
return nil, fmt.Errorf("redis 错误:%s", line)
case ':':
// --------------------
// 整数::100\r\n
// --------------------
line, err := readLine(r)
if err != nil {
return nil, err
}
num, _ := strconv.ParseInt(line, 10, 64)
return num, nil
case '$':
// --------------------
// 批量字符串(二进制安全):$5\r\nhello\r\n
// --------------------
// 第一步:读取长度
lenStr, err := readLine(r)
if err != nil {
return nil, err
}
length, _ := strconv.Atoi(lenStr)
// 特殊情况:nil(key不存在)
if length == -1 {
return nil, nil
}
// 空字符串
if length == 0 {
return "", nil
}
// 第二步:读取指定长度的内容
data := make([]byte, length)
_, err = r.Read(data)
if err != nil {
return nil, err
}
// 读取末尾的 \r\n(丢弃)
readLine(r)
return string(data), nil
case '*':
// --------------------
// 数组:*2\r\n$3\r\nfoo\r\n...
// 用于 mget、hgetall 等返回多结果
// --------------------
return readArray(r)
default:
return nil, fmt.Errorf("未知类型:%c", prefix)
}
}
// ----------------------------------------------------------------
// readArray:解析 RESP 数组(递归调用 handleResponse)
// ----------------------------------------------------------------
func readArray(r *bufio.Reader) ([]interface{}, error) {
// 1. 读取数组长度
lenStr, err := readLine(r)
if err != nil {
return nil, err
}
length, _ := strconv.Atoi(lenStr)
// 空数组
if length <= 0 {
return nil, nil
}
// 2. 遍历读取数组中的每一个元素
var arr []interface{}
for i := 0; i < length; i++ {
item, err := handleResponse(r)
if err != nil {
return nil, err
}
arr = append(arr, item)
}
return arr, nil
}
// ----------------------------------------------------------------
// readLine:读取一行数据(自动去掉结尾 \r\n)
// ----------------------------------------------------------------
func readLine(r *bufio.Reader) (string, error) {
line, err := r.ReadString('\n')
if err != nil {
return "", err
}
// 去掉 \r\n
line = strings.TrimSpace(line)
return line, nil
}
3.2、Redis 内存回收-过期 key 处理
Redis 之所以性能强,最主要的原因就是基于内存存储。然而单节点的 Redis 其内存大小不宜过大,会影响持久化或主从同步性能。 我们可以通过修改配置文件来设置 Redis 的最大内存:

当内存使用达到上限时,就无法存储更多数据了。为了解决这个问题,Redis 提供了一些策略实现内存回收:
内存过期策略
在学习 Redis 缓存的时候我们说过,可以通过 expire 命令给 Redis 的 key 设置 TTL(存活时间):
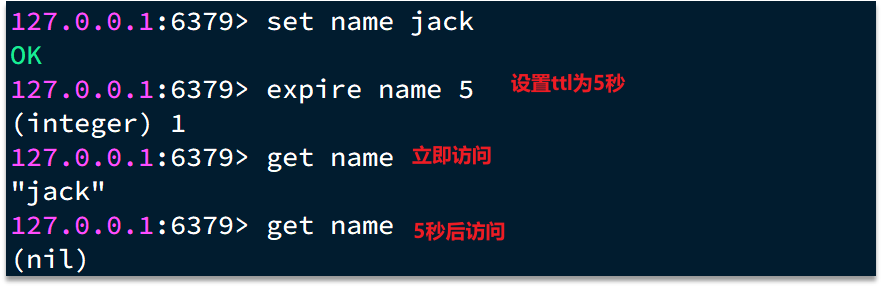
可以发现,当 key 的 TTL 到期以后,再次访问 name 返回的是 nil,说明这个 key 已经不存在了,对应的内存也得到释放。从而起到内存回收的目的。
Redis 本身是一个典型的 key-value 内存存储数据库,因此所有的 key、value 都保存在之前学习过的 Dict 结构中。不过在其 database 结构体中,有两个 Dict:一个用来记录 key-value;另一个用来记录 key-TTL。
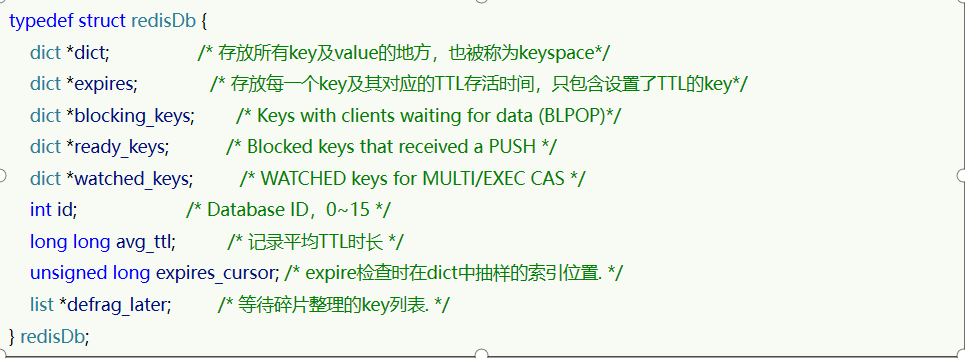
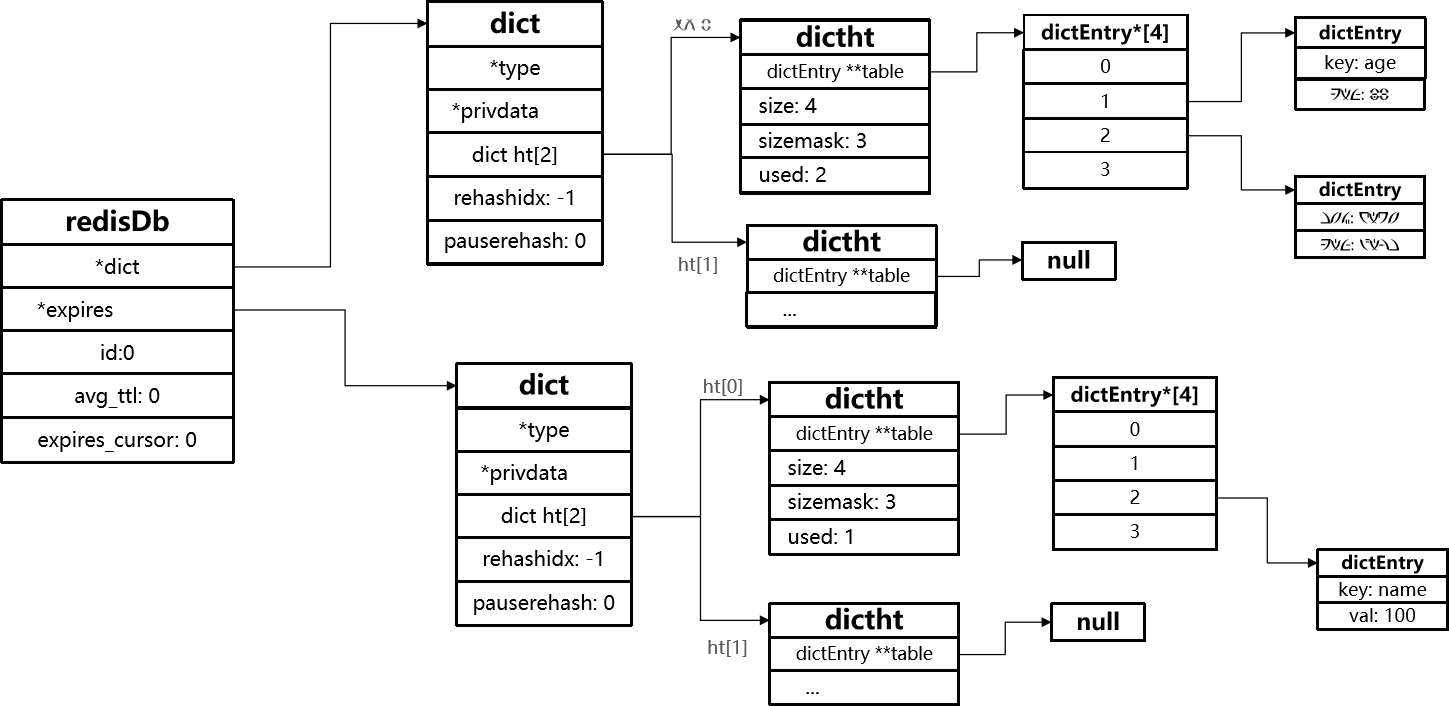
这里有两个问题需要我们思考: Redis 是如何知道一个 key 是否过期呢?
利用两个 Dict 分别记录 key-value 对及 key-ttl 对
是不是 TTL 到期就立即删除了呢?
惰性删除
惰性删除:顾明思议并不是在 TTL 到期后就立刻删除,而是在访问一个 key 的时候,检查该 key 的存活时间,如果已经过期才执行删除。

周期删除
周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的 key,然后执行删除。执行周期有两种: Redis 服务初始化函数 initServer()中设置定时任务,按照 server.hz 的频率来执行过期 key 清理,模式为 SLOW Redis 的每个事件循环前会调用 beforeSleep()函数,执行过期 key 清理,模式为 FAST
周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的 key,然后执行删除。执行周期有两种: Redis 服务初始化函数 initServer()中设置定时任务,按照 server.hz 的频率来执行过期 key 清理,模式为 SLOW Redis 的每个事件循环前会调用 beforeSleep()函数,执行过期 key 清理,模式为 FAST
SLOW 模式规则:
- 执行频率受 server.hz 影响,默认为 10,即每秒执行 10 次,每个执行周期 100ms。
- 执行清理耗时不超过一次执行周期的 25%.默认 slow 模式耗时不超过 25ms
- 逐个遍历 db,逐个遍历 db 中的 bucket,抽取 20 个 key 判断是否过期
- 如果没达到时间上限(25ms)并且过期 key 比例大于 10%,再进行一次抽样,否则结束
- FAST 模式规则(过期 key 比例小于 10%不执行 ):
- 执行频率受 beforeSleep()调用频率影响,但两次 FAST 模式间隔不低于 2ms
- 执行清理耗时不超过 1ms
- 逐个遍历 db,逐个遍历 db 中的 bucket,抽取 20 个 key 判断是否过期 如果没达到时间上限(1ms)并且过期 key 比例大于 10%,再进行一次抽样,否则结束
小总结:
RedisKey 的 TTL 记录方式:
在 RedisDB 中通过一个 Dict 记录每个 Key 的 TTL 时间
过期 key 的删除策略:
惰性清理:每次查找 key 时判断是否过期,如果过期则删除
定期清理:定期抽样部分 key,判断是否过期,如果过期则删除。 定期清理的两种模式:
SLOW 模式执行频率默认为 10,每次不超过 25ms
FAST 模式执行频率不固定,但两次间隔不低于 2ms,每次耗时不超过 1ms
3.3 Redis 内存回收-内存淘汰策略
内存淘汰:就是当 Redis 内存使用达到设置的上限时,主动挑选部分 key 删除以释放更多内存的流程。Redis 会在处理客户端命令的方法 processCommand()中尝试做内存淘汰:

淘汰策略
Redis 支持 8 种不同策略来选择要删除的 key:
- noeviction: 不淘汰任何 key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了 TTL 的 key,比较 key 的剩余 TTL 值,TTL 越小越先被淘汰
- allkeys-random:对全体 key ,随机进行淘汰。也就是直接从 db->dict 中随机挑选
- volatile-random:对设置了 TTL 的 key ,随机进行淘汰。也就是从 db->expires 中随机挑选。
- allkeys-lru: 对全体 key,基于 LRU 算法进行淘汰
- volatile-lru: 对设置了 TTL 的 key,基于 LRU 算法进行淘汰
- allkeys-lfu: 对全体 key,基于 LFU 算法进行淘汰
- volatile-lfu: 对设置了 TTL 的 key,基于 LFI 算法进行淘汰
比较容易混淆的有两个:
- LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU(Least Frequently Used),最少频率使用。会统计每个 key 的访问频率,值越小淘汰优先级越高。
Redis 的数据都会被封装为 RedisObject 结构:

LFU 的访问次数之所以叫做逻辑访问次数,是因为并不是每次 key 被访问都计数,而是通过运算:
- 生成 0~1 之间的随机数 R
- 计算 (旧次数 * lfu_log_factor + 1),记录为 P
- 如果 R < P ,则计数器 + 1,且最大不超过 255
- 访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟,计数器 -1
最后用一副图来描述当前的这个流程吧
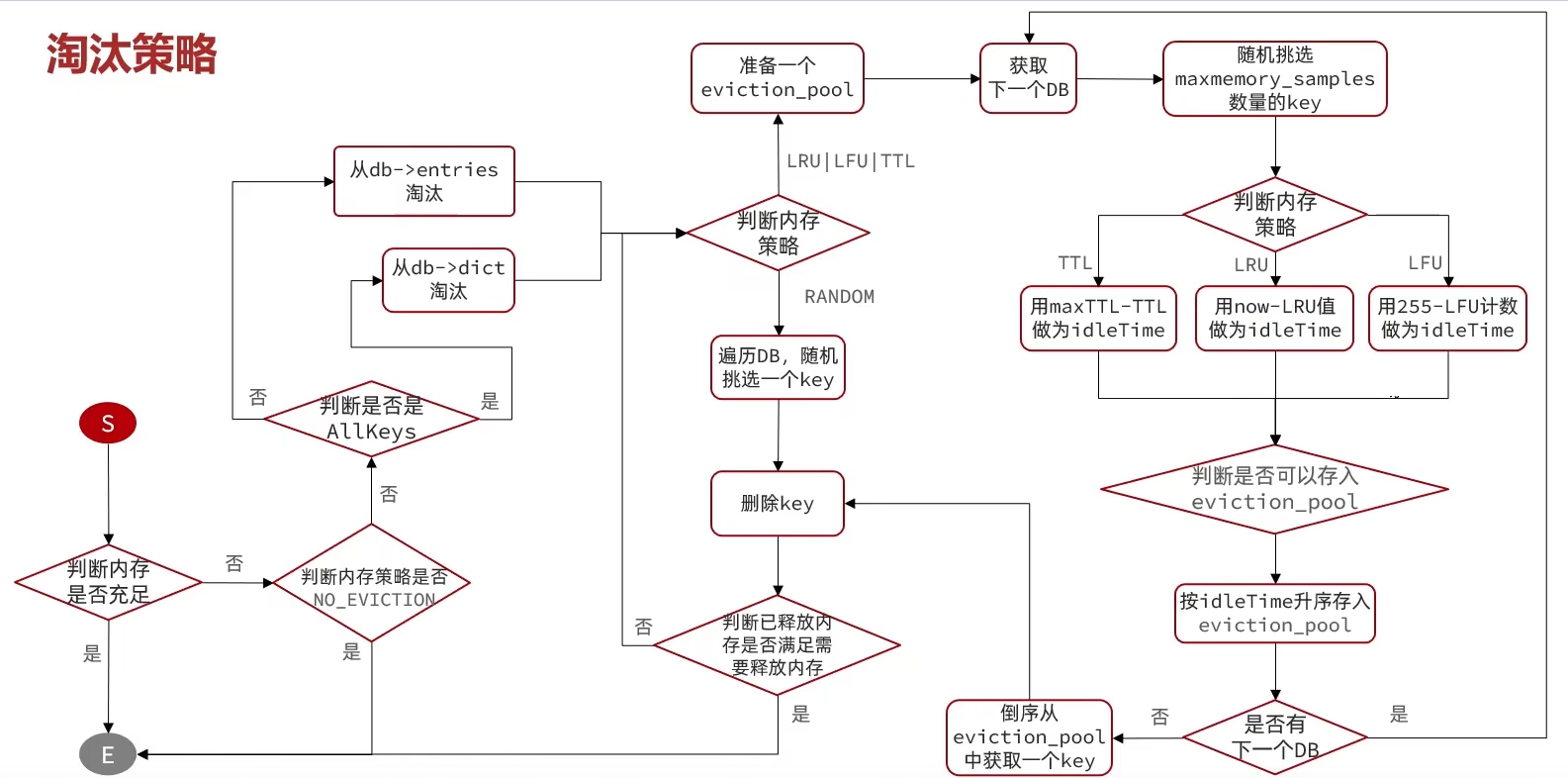
喜欢的话,留下你的评论吧~